research
Rumors
sporadically spread with people with fewer followers in the center
Researched
over 100 rumors in the US from 2006 to 2009
Is it
possible to filter information on SNS such as Twitter and Facebook?
A research
team led by Professor Mee-Young Cha from the Department of Cultural Technology
Graduate School at KAIST, Professor Kyo-Min Jung of Seoul National University,
Doctor Wei Chen and Yajun Wang of Microsoft Asia, has developed a technology
that can accurately filter out information on Twitter to 90% accuracy.
The
research not only deduced a new mathematical model, network structure, and
linguistic characteristics on rumors from SNS data, but is also expected to
enhance the effort to make secure technology to regulate Internet rumors.
The team
analysed the characteristics of rumors in over 100 widespread cases in the US
from 2006 to 2009 on Twitter. The team gathered data, which included a range of
areas such as politics, IT, health and celebrity gossips, and their analysis
could identify rumors to 90% accuracy. The filtering was more accurate in
rumors that included slanders or insults.
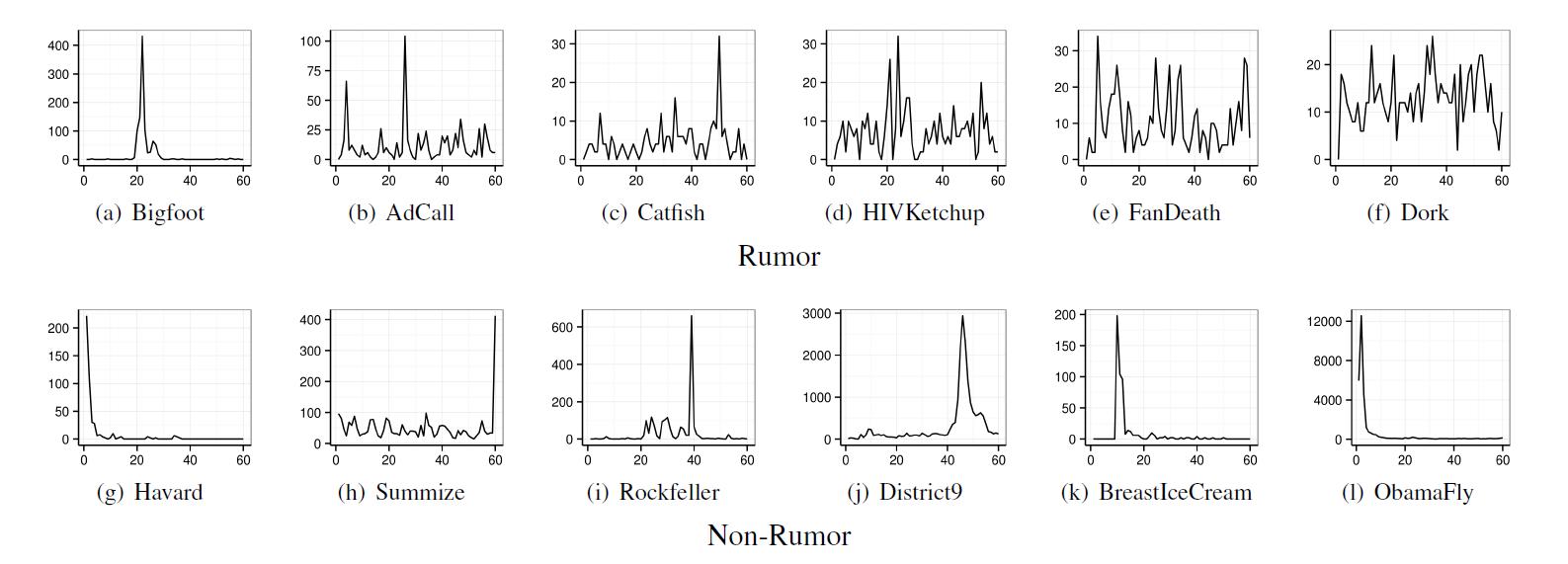
The
research team identified three characteristics of the spread of rumors.
Firstly,
rumors spread continuously. Normal news spreads widely once and is mentioned
rarely again on media, but rumors tend to continue for years.
Secondly,
rumors spread through sporadic participation of random users with no
connections. Rumors start from people with fewer followers and spread to the
more popular. This phenomenon is often observed in rumors concerning
celebrities or politicians.
Lastly,
rumors have unique linguistic characteristics. Rumors frequently include words
(such as “it may be true,” “although not certain, I think,” “although I cannot
fully remember”) related to psychological processes that question, deny, or
infer the reliability of the information.
Professor
Cha said, “This research deduced not only a statistical and mathematical model
but also is an integrated research on social psychological theory on the
characteristics of rumors that attract great attention from the society based
on ample data.”
The results were made public in IEEE International Conference on Data Mining last December in Texas, USA.
- No Data