big+data
-
 Unraveling Mitochondrial DNA Mutations in Human Cells
Throughout our lifetime, cells accumulate DNA mutations, which contribute to genetic diversity, or “mosaicism”, among cells. These genomic mutations are pivotal for the aging process and the onset of various diseases, including cancer. Mitochondria, essential cellular organelles involved in energy metabolism and apoptosis, possess their own DNA, which are susceptible to mutations. However, studies on mtDNA mutations and mosaicism have been limited due to a variety of technical challenges.
Genomic scientists from KAIST have revealed the genetic mosaicism characterized by variations in mitochondrial DNA (mtDNA) across normal human cells. This study provides fundamental insights into understanding human aging and disease onset mechanisms.
The study, “Mitochondrial DNA mosaicism in normal human somatic cells,” was published in Nature Genetics on July 22. It was led by graduate student Jisong An under the supervision of Professor Young Seok Ju from the Graduate School of Medical Science and Engineering.
Researchers from Seoul National University College of Medicine, Yonsei University College of Medicine, Korea University College of Medicine, Washington University School of Medicine National Cancer Center, Seoul National University Hospital, Gangnam Severance Hospital and KAIST faculty startup company Inocras Inc. also participated in this study.
< Figure 1. a. Flow of experiment. b. Schematic diagram illustrating the origin and dynamics of mtDNA alterations across a lifetime. >
The study involved a bioinformatic analysis of whole-genome sequences from 2,096 single cells obtained from normal human colorectal epithelial tissue, fibroblasts, and blood collected from 31 individuals. The study highlights an average of three significant mtDNA differences between cells, with approximately 6% of these variations confirmed to be inherited as heteroplasmy from the mother.
Moreover, mutations significantly increased during tumorigenesis, with some mutations contributing to instability in mitochondrial RNA. Based on these findings, the study illustrates a computational model that comprehensively elucidates the evolution of mitochondria from embryonic development to aging and tumorigenesis.
This study systematically reveals the mechanisms behind mitochondrial DNA mosaicism in normal human cells, establishing a crucial foundation for understanding the impact of mtDNA on aging and disease onset.
Professor Ju remarked, “By systematically utilizing whole-genome big data, we can illuminate previously unknown phenomena in life sciences.” He emphasized the significance of the study, adding, “For the first time, we have established a method to systematically understand mitochondrial DNA changes occurring during human embryonic development, aging, and cancer development.”
This work was supported by the National Research Foundation of Korea and the Suh Kyungbae Foundation.
2024.07.24 View 5469
Unraveling Mitochondrial DNA Mutations in Human Cells
Throughout our lifetime, cells accumulate DNA mutations, which contribute to genetic diversity, or “mosaicism”, among cells. These genomic mutations are pivotal for the aging process and the onset of various diseases, including cancer. Mitochondria, essential cellular organelles involved in energy metabolism and apoptosis, possess their own DNA, which are susceptible to mutations. However, studies on mtDNA mutations and mosaicism have been limited due to a variety of technical challenges.
Genomic scientists from KAIST have revealed the genetic mosaicism characterized by variations in mitochondrial DNA (mtDNA) across normal human cells. This study provides fundamental insights into understanding human aging and disease onset mechanisms.
The study, “Mitochondrial DNA mosaicism in normal human somatic cells,” was published in Nature Genetics on July 22. It was led by graduate student Jisong An under the supervision of Professor Young Seok Ju from the Graduate School of Medical Science and Engineering.
Researchers from Seoul National University College of Medicine, Yonsei University College of Medicine, Korea University College of Medicine, Washington University School of Medicine National Cancer Center, Seoul National University Hospital, Gangnam Severance Hospital and KAIST faculty startup company Inocras Inc. also participated in this study.
< Figure 1. a. Flow of experiment. b. Schematic diagram illustrating the origin and dynamics of mtDNA alterations across a lifetime. >
The study involved a bioinformatic analysis of whole-genome sequences from 2,096 single cells obtained from normal human colorectal epithelial tissue, fibroblasts, and blood collected from 31 individuals. The study highlights an average of three significant mtDNA differences between cells, with approximately 6% of these variations confirmed to be inherited as heteroplasmy from the mother.
Moreover, mutations significantly increased during tumorigenesis, with some mutations contributing to instability in mitochondrial RNA. Based on these findings, the study illustrates a computational model that comprehensively elucidates the evolution of mitochondria from embryonic development to aging and tumorigenesis.
This study systematically reveals the mechanisms behind mitochondrial DNA mosaicism in normal human cells, establishing a crucial foundation for understanding the impact of mtDNA on aging and disease onset.
Professor Ju remarked, “By systematically utilizing whole-genome big data, we can illuminate previously unknown phenomena in life sciences.” He emphasized the significance of the study, adding, “For the first time, we have established a method to systematically understand mitochondrial DNA changes occurring during human embryonic development, aging, and cancer development.”
This work was supported by the National Research Foundation of Korea and the Suh Kyungbae Foundation.
2024.07.24 View 5469 -
 Machine Learning-Based Algorithm to Speed up DNA Sequencing
The algorithm presents the first full-fledged, short-read alignment software that leverages learned indices for solving the exact match search problem for efficient seeding
The human genome consists of a complete set of DNA, which is about 6.4 billion letters long. Because of its size, reading the whole genome sequence at once is challenging. So scientists use DNA sequencers to produce hundreds of millions of DNA sequence fragments, or short reads, up to 300 letters long. Then the DNA sequencer assembles all the short reads like a giant jigsaw puzzle to reconstruct the entire genome sequence. Even with very fast computers, this job can take hours to complete.
A research team at KAIST has achieved up to 3.45x faster speeds by developing the first short-read alignment software that uses a recent advance in machine-learning called a learned index.
The research team reported their findings on March 7, 2022 in the journal Bioinformatics. The software has been released as open source and can be found on github (https://github.com/kaist-ina/BWA-MEME).
Next-generation sequencing (NGS) is a state-of-the-art DNA sequencing method. Projects are underway with the goal of producing genome sequencing at population scale. Modern NGS hardware is capable of generating billions of short reads in a single run. Then the short reads have to be aligned with the reference DNA sequence. With large-scale DNA sequencing operations running hundreds of next-generation sequences, the need for an efficient short read alignment tool has become even more critical. Accelerating the DNA sequence alignment would be a step toward achieving the goal of population-scale sequencing. However, existing algorithms are limited in their performance because of their frequent memory accesses.
BWA-MEM2 is a popular short-read alignment software package currently used to sequence the DNA. However, it has its limitations. The state-of-the-art alignment has two phases – seeding and extending. During the seeding phase, searches find exact matches of short reads in the reference DNA sequence. During the extending phase, the short reads from the seeding phase are extended. In the current process, bottlenecks occur in the seeding phase. Finding the exact matches slows the process.
The researchers set out to solve the problem of accelerating the DNA sequence alignment. To speed the process, they applied machine learning techniques to create an algorithmic improvement. Their algorithm, BWA-MEME (BWA-MEM emulated) leverages learned indices to solve the exact match search problem. The original software compared one character at a time for an exact match search. The team’s new algorithm achieves up to 3.45x faster speeds in seeding throughput over BWA-MEM2 by reducing the number of instructions by 4.60x and memory accesses by 8.77x. “Through this study, it has been shown that full genome big data analysis can be performed faster and less costly than conventional methods by applying machine learning technology,” said Professor Dongsu Han from the School of Electrical Engineering at KAIST.
The researchers’ ultimate goal was to develop efficient software that scientists from academia and industry could use on a daily basis for analyzing big data in genomics. “With the recent advances in artificial intelligence and machine learning, we see so many opportunities for designing better software for genomic data analysis. The potential is there for accelerating existing analysis as well as enabling new types of analysis, and our goal is to develop such software,” added Han.
Whole genome sequencing has traditionally been used for discovering genomic mutations and identifying the root causes of diseases, which leads to the discovery and development of new drugs and cures. There could be many potential applications. Whole genome sequencing is used not only for research, but also for clinical purposes. “The science and technology for analyzing genomic data is making rapid progress to make it more accessible for scientists and patients. This will enhance our understanding about diseases and develop a better cure for patients of various diseases.”
The research was funded by the National Research Foundation of the Korean government’s Ministry of Science and ICT.
-PublicationYoungmok Jung, Dongsu Han, “BWA-MEME:BWA-MEM emulated with a machine learning approach,” Bioinformatics, Volume 38, Issue 9, May 2022
(https://doi.org/10.1093/bioinformatics/btac137)
-ProfileProfessor Dongsu HanSchool of Electrical EngineeringKAIST
2022.05.10 View 10456
Machine Learning-Based Algorithm to Speed up DNA Sequencing
The algorithm presents the first full-fledged, short-read alignment software that leverages learned indices for solving the exact match search problem for efficient seeding
The human genome consists of a complete set of DNA, which is about 6.4 billion letters long. Because of its size, reading the whole genome sequence at once is challenging. So scientists use DNA sequencers to produce hundreds of millions of DNA sequence fragments, or short reads, up to 300 letters long. Then the DNA sequencer assembles all the short reads like a giant jigsaw puzzle to reconstruct the entire genome sequence. Even with very fast computers, this job can take hours to complete.
A research team at KAIST has achieved up to 3.45x faster speeds by developing the first short-read alignment software that uses a recent advance in machine-learning called a learned index.
The research team reported their findings on March 7, 2022 in the journal Bioinformatics. The software has been released as open source and can be found on github (https://github.com/kaist-ina/BWA-MEME).
Next-generation sequencing (NGS) is a state-of-the-art DNA sequencing method. Projects are underway with the goal of producing genome sequencing at population scale. Modern NGS hardware is capable of generating billions of short reads in a single run. Then the short reads have to be aligned with the reference DNA sequence. With large-scale DNA sequencing operations running hundreds of next-generation sequences, the need for an efficient short read alignment tool has become even more critical. Accelerating the DNA sequence alignment would be a step toward achieving the goal of population-scale sequencing. However, existing algorithms are limited in their performance because of their frequent memory accesses.
BWA-MEM2 is a popular short-read alignment software package currently used to sequence the DNA. However, it has its limitations. The state-of-the-art alignment has two phases – seeding and extending. During the seeding phase, searches find exact matches of short reads in the reference DNA sequence. During the extending phase, the short reads from the seeding phase are extended. In the current process, bottlenecks occur in the seeding phase. Finding the exact matches slows the process.
The researchers set out to solve the problem of accelerating the DNA sequence alignment. To speed the process, they applied machine learning techniques to create an algorithmic improvement. Their algorithm, BWA-MEME (BWA-MEM emulated) leverages learned indices to solve the exact match search problem. The original software compared one character at a time for an exact match search. The team’s new algorithm achieves up to 3.45x faster speeds in seeding throughput over BWA-MEM2 by reducing the number of instructions by 4.60x and memory accesses by 8.77x. “Through this study, it has been shown that full genome big data analysis can be performed faster and less costly than conventional methods by applying machine learning technology,” said Professor Dongsu Han from the School of Electrical Engineering at KAIST.
The researchers’ ultimate goal was to develop efficient software that scientists from academia and industry could use on a daily basis for analyzing big data in genomics. “With the recent advances in artificial intelligence and machine learning, we see so many opportunities for designing better software for genomic data analysis. The potential is there for accelerating existing analysis as well as enabling new types of analysis, and our goal is to develop such software,” added Han.
Whole genome sequencing has traditionally been used for discovering genomic mutations and identifying the root causes of diseases, which leads to the discovery and development of new drugs and cures. There could be many potential applications. Whole genome sequencing is used not only for research, but also for clinical purposes. “The science and technology for analyzing genomic data is making rapid progress to make it more accessible for scientists and patients. This will enhance our understanding about diseases and develop a better cure for patients of various diseases.”
The research was funded by the National Research Foundation of the Korean government’s Ministry of Science and ICT.
-PublicationYoungmok Jung, Dongsu Han, “BWA-MEME:BWA-MEM emulated with a machine learning approach,” Bioinformatics, Volume 38, Issue 9, May 2022
(https://doi.org/10.1093/bioinformatics/btac137)
-ProfileProfessor Dongsu HanSchool of Electrical EngineeringKAIST
2022.05.10 View 10456 -
 CXL-Based Memory Disaggregation Technology Opens Up a New Direction for Big Data Solution Frameworks
A KAIST team’s compute express link (CXL) provides new insights on memory disaggregation and ensures direct access and high-performance capabilities
A team from the Computer Architecture and Memory Systems Laboratory (CAMEL) at KAIST presented a new compute express link (CXL) solution whose directly accessible, and high-performance memory disaggregation opens new directions for big data memory processing. Professor Myoungsoo Jung said the team’s technology significantly improves performance compared to existing remote direct memory access (RDMA)-based memory disaggregation.
CXL is a peripheral component interconnect-express (PCIe)-based new dynamic multi-protocol made for efficiently utilizing memory devices and accelerators. Many enterprise data centers and memory vendors are paying attention to it as the next-generation multi-protocol for the era of big data.
Emerging big data applications such as machine learning, graph analytics, and in-memory databases require large memory capacities. However, scaling out the memory capacity via a prior memory interface like double data rate (DDR) is limited by the number of the central processing units (CPUs) and memory controllers. Therefore, memory disaggregation, which allows connecting a host to another host’s memory or memory nodes, has appeared.
RDMA is a way that a host can directly access another host’s memory via InfiniBand, the commonly used network protocol in data centers. Nowadays, most existing memory disaggregation technologies employ RDMA to get a large memory capacity. As a result, a host can share another host’s memory by transferring the data between local and remote memory.
Although RDMA-based memory disaggregation provides a large memory capacity to a host, two critical problems exist. First, scaling out the memory still needs an extra CPU to be added. Since passive memory such as dynamic random-access memory (DRAM), cannot operate by itself, it should be controlled by the CPU. Second, redundant data copies and software fabric interventions for RDMA-based memory disaggregation cause longer access latency. For example, remote memory access latency in RDMA-based memory disaggregation is multiple orders of magnitude longer than local memory access.
To address these issues, Professor Jung’s team developed the CXL-based memory disaggregation framework, including CXL-enabled customized CPUs, CXL devices, CXL switches, and CXL-aware operating system modules. The team’s CXL device is a pure passive and directly accessible memory node that contains multiple DRAM dual inline memory modules (DIMMs) and a CXL memory controller. Since the CXL memory controller supports the memory in the CXL device, a host can utilize the memory node without processor or software intervention. The team’s CXL switch enables scaling out a host’s memory capacity by hierarchically connecting multiple CXL devices to the CXL switch allowing more than hundreds of devices. Atop the switches and devices, the team’s CXL-enabled operating system removes redundant data copy and protocol conversion exhibited by conventional RDMA, which can significantly decrease access latency to the memory nodes.
In a test comparing loading 64B (cacheline) data from memory pooling devices, CXL-based memory disaggregation showed 8.2 times higher data load performance than RDMA-based memory disaggregation and even similar performance to local DRAM memory. In the team’s evaluations for a big data benchmark such as a machine learning-based test, CXL-based memory disaggregation technology also showed a maximum of 3.7 times higher performance than prior RDMA-based memory disaggregation technologies.
“Escaping from the conventional RDMA-based memory disaggregation, our CXL-based memory disaggregation framework can provide high scalability and performance for diverse datacenters and cloud service infrastructures,” said Professor Jung. He went on to stress, “Our CXL-based memory disaggregation research will bring about a new paradigm for memory solutions that will lead the era of big data.”
-Profile: Professor Myoungsoo Jung Computer Architecture and Memory Systems Laboratory (CAMEL)http://camelab.org School of Electrical EngineeringKAIST
2022.03.16 View 24151
CXL-Based Memory Disaggregation Technology Opens Up a New Direction for Big Data Solution Frameworks
A KAIST team’s compute express link (CXL) provides new insights on memory disaggregation and ensures direct access and high-performance capabilities
A team from the Computer Architecture and Memory Systems Laboratory (CAMEL) at KAIST presented a new compute express link (CXL) solution whose directly accessible, and high-performance memory disaggregation opens new directions for big data memory processing. Professor Myoungsoo Jung said the team’s technology significantly improves performance compared to existing remote direct memory access (RDMA)-based memory disaggregation.
CXL is a peripheral component interconnect-express (PCIe)-based new dynamic multi-protocol made for efficiently utilizing memory devices and accelerators. Many enterprise data centers and memory vendors are paying attention to it as the next-generation multi-protocol for the era of big data.
Emerging big data applications such as machine learning, graph analytics, and in-memory databases require large memory capacities. However, scaling out the memory capacity via a prior memory interface like double data rate (DDR) is limited by the number of the central processing units (CPUs) and memory controllers. Therefore, memory disaggregation, which allows connecting a host to another host’s memory or memory nodes, has appeared.
RDMA is a way that a host can directly access another host’s memory via InfiniBand, the commonly used network protocol in data centers. Nowadays, most existing memory disaggregation technologies employ RDMA to get a large memory capacity. As a result, a host can share another host’s memory by transferring the data between local and remote memory.
Although RDMA-based memory disaggregation provides a large memory capacity to a host, two critical problems exist. First, scaling out the memory still needs an extra CPU to be added. Since passive memory such as dynamic random-access memory (DRAM), cannot operate by itself, it should be controlled by the CPU. Second, redundant data copies and software fabric interventions for RDMA-based memory disaggregation cause longer access latency. For example, remote memory access latency in RDMA-based memory disaggregation is multiple orders of magnitude longer than local memory access.
To address these issues, Professor Jung’s team developed the CXL-based memory disaggregation framework, including CXL-enabled customized CPUs, CXL devices, CXL switches, and CXL-aware operating system modules. The team’s CXL device is a pure passive and directly accessible memory node that contains multiple DRAM dual inline memory modules (DIMMs) and a CXL memory controller. Since the CXL memory controller supports the memory in the CXL device, a host can utilize the memory node without processor or software intervention. The team’s CXL switch enables scaling out a host’s memory capacity by hierarchically connecting multiple CXL devices to the CXL switch allowing more than hundreds of devices. Atop the switches and devices, the team’s CXL-enabled operating system removes redundant data copy and protocol conversion exhibited by conventional RDMA, which can significantly decrease access latency to the memory nodes.
In a test comparing loading 64B (cacheline) data from memory pooling devices, CXL-based memory disaggregation showed 8.2 times higher data load performance than RDMA-based memory disaggregation and even similar performance to local DRAM memory. In the team’s evaluations for a big data benchmark such as a machine learning-based test, CXL-based memory disaggregation technology also showed a maximum of 3.7 times higher performance than prior RDMA-based memory disaggregation technologies.
“Escaping from the conventional RDMA-based memory disaggregation, our CXL-based memory disaggregation framework can provide high scalability and performance for diverse datacenters and cloud service infrastructures,” said Professor Jung. He went on to stress, “Our CXL-based memory disaggregation research will bring about a new paradigm for memory solutions that will lead the era of big data.”
-Profile: Professor Myoungsoo Jung Computer Architecture and Memory Systems Laboratory (CAMEL)http://camelab.org School of Electrical EngineeringKAIST
2022.03.16 View 24151 -
 ‘Urban Green Space Affects Citizens’ Happiness’
Study finds the relationship between green space, the economy, and happiness
A recent study revealed that as a city becomes more economically developed, its citizens’ happiness becomes more directly related to the area of urban green space.
A joint research project by Professor Meeyoung Cha of the School of Computing and her collaborators studied the relationship between green space and citizen happiness by analyzing big data from satellite images of 60 different countries.
Urban green space, including parks, gardens, and riversides not only provides aesthetic pleasure, but also positively affects our health by promoting physical activity and social interactions. Most of the previous research attempting to verify the correlation between urban green space and citizen happiness was based on few developed countries. Therefore, it was difficult to identify whether the positive effects of green space are global, or merely phenomena that depended on the economic state of the country. There have also been limitations in data collection, as it is difficult to visit each location or carry out investigations on a large scale based on aerial photographs.
The research team used data collected by Sentinel-2, a high-resolution satellite operated by the European Space Agency (ESA) to investigate 90 green spaces from 60 different countries around the world. The subjects of analysis were cities with the highest population densities (cities that contain at least 10% of the national population), and the images were obtained during the summer of each region for clarity. Images from the northern hemisphere were obtained between June and September of 2018, and those from the southern hemisphere were obtained between December of 2017 and February of 2018.
The areas of urban green space were then quantified and crossed with data from the World Happiness Report and GDP by country reported by the United Nations in 2018. Using these data, the relationships between green space, the economy, and citizen happiness were analyzed.
The results showed that in all cities, citizen happiness was positively correlated with the area of urban green space regardless of the country’s economic state. However, out of the 60 countries studied, the happiness index of the bottom 30 by GDP showed a stronger correlation with economic growth. In countries whose gross national income (GDP per capita) was higher than 38,000 USD, the area of green space acted as a more important factor affecting happiness than economic growth. Data from Seoul was analyzed to represent South Korea, and showed an increased happiness index with increased green areas compared to the past.
The authors point out their work has several policy-level implications. First, public green space should be made accessible to urban dwellers to enhance social support. If public safety in urban parks is not guaranteed, its positive role in social support and happiness may diminish. Also, the meaning of public safety may change; for example, ensuring biological safety will be a priority in keeping urban parks accessible during the COVID-19 pandemic.
Second, urban planning for public green space is needed for both developed and developing countries. As it is challenging or nearly impossible to secure land for green space after the area is developed, urban planning for parks and green space should be considered in developing economies where new cities and suburban areas are rapidly expanding.
Third, recent climate changes can present substantial difficulty in sustaining urban green space. Extreme events such as wildfires, floods, droughts, and cold waves could endanger urban forests while global warming could conversely accelerate tree growth in cities due to the urban heat island effect. Thus, more attention must be paid to predict climate changes and discovering their impact on the maintenance of urban green space.
“There has recently been an increase in the number of studies using big data from satellite images to solve social conundrums,” said Professor Cha. “The tool developed for this investigation can also be used to quantify the area of aquatic environments like lakes and the seaside, and it will now be possible to analyze the relationship between citizen happiness and aquatic environments in future studies,” she added.
Professor Woo Sung Jung from POSTECH and Professor Donghee Wohn from the New Jersey Institute of Technology also joined this research. It was reported in the online issue of EPJ Data Science on May 30.
-PublicationOh-Hyun Kwon, Inho Hong, Jeasurk Yang, Donghee Y. Wohn, Woo-Sung Jung, andMeeyoung Cha, 2021. Urban green space and happiness in developed countries. EPJ Data Science. DOI: https://doi.org/10.1140/epjds/s13688-021-00278-7
-ProfileProfessor Meeyoung ChaData Science Labhttps://ds.ibs.re.kr/
School of Computing
KAIST
2021.06.21 View 13377
‘Urban Green Space Affects Citizens’ Happiness’
Study finds the relationship between green space, the economy, and happiness
A recent study revealed that as a city becomes more economically developed, its citizens’ happiness becomes more directly related to the area of urban green space.
A joint research project by Professor Meeyoung Cha of the School of Computing and her collaborators studied the relationship between green space and citizen happiness by analyzing big data from satellite images of 60 different countries.
Urban green space, including parks, gardens, and riversides not only provides aesthetic pleasure, but also positively affects our health by promoting physical activity and social interactions. Most of the previous research attempting to verify the correlation between urban green space and citizen happiness was based on few developed countries. Therefore, it was difficult to identify whether the positive effects of green space are global, or merely phenomena that depended on the economic state of the country. There have also been limitations in data collection, as it is difficult to visit each location or carry out investigations on a large scale based on aerial photographs.
The research team used data collected by Sentinel-2, a high-resolution satellite operated by the European Space Agency (ESA) to investigate 90 green spaces from 60 different countries around the world. The subjects of analysis were cities with the highest population densities (cities that contain at least 10% of the national population), and the images were obtained during the summer of each region for clarity. Images from the northern hemisphere were obtained between June and September of 2018, and those from the southern hemisphere were obtained between December of 2017 and February of 2018.
The areas of urban green space were then quantified and crossed with data from the World Happiness Report and GDP by country reported by the United Nations in 2018. Using these data, the relationships between green space, the economy, and citizen happiness were analyzed.
The results showed that in all cities, citizen happiness was positively correlated with the area of urban green space regardless of the country’s economic state. However, out of the 60 countries studied, the happiness index of the bottom 30 by GDP showed a stronger correlation with economic growth. In countries whose gross national income (GDP per capita) was higher than 38,000 USD, the area of green space acted as a more important factor affecting happiness than economic growth. Data from Seoul was analyzed to represent South Korea, and showed an increased happiness index with increased green areas compared to the past.
The authors point out their work has several policy-level implications. First, public green space should be made accessible to urban dwellers to enhance social support. If public safety in urban parks is not guaranteed, its positive role in social support and happiness may diminish. Also, the meaning of public safety may change; for example, ensuring biological safety will be a priority in keeping urban parks accessible during the COVID-19 pandemic.
Second, urban planning for public green space is needed for both developed and developing countries. As it is challenging or nearly impossible to secure land for green space after the area is developed, urban planning for parks and green space should be considered in developing economies where new cities and suburban areas are rapidly expanding.
Third, recent climate changes can present substantial difficulty in sustaining urban green space. Extreme events such as wildfires, floods, droughts, and cold waves could endanger urban forests while global warming could conversely accelerate tree growth in cities due to the urban heat island effect. Thus, more attention must be paid to predict climate changes and discovering their impact on the maintenance of urban green space.
“There has recently been an increase in the number of studies using big data from satellite images to solve social conundrums,” said Professor Cha. “The tool developed for this investigation can also be used to quantify the area of aquatic environments like lakes and the seaside, and it will now be possible to analyze the relationship between citizen happiness and aquatic environments in future studies,” she added.
Professor Woo Sung Jung from POSTECH and Professor Donghee Wohn from the New Jersey Institute of Technology also joined this research. It was reported in the online issue of EPJ Data Science on May 30.
-PublicationOh-Hyun Kwon, Inho Hong, Jeasurk Yang, Donghee Y. Wohn, Woo-Sung Jung, andMeeyoung Cha, 2021. Urban green space and happiness in developed countries. EPJ Data Science. DOI: https://doi.org/10.1140/epjds/s13688-021-00278-7
-ProfileProfessor Meeyoung ChaData Science Labhttps://ds.ibs.re.kr/
School of Computing
KAIST
2021.06.21 View 13377 -
 Research on the Million Follower Fallacy Receives the Test of Time Award
Professor Meeyoung Cha’s research investigating the correlation between the number of followers on social media and its influence was re-highlighted after 10 years of publication of the paper.
Saying that her research is still as relevant today as the day it was published 10 years ago, the Association for the Advancement of Artificial Intelligence (AAAI) presented Professor Cha from the School of Computing with the Test of Time Award during the 14th International Conference on Web and Social Media (ICWSM) held online June 8 through 11.
In her 2010 paper titled ‘Measuring User Influence in Twitter: The Million Follower Fallacy,’ Professor Cha proved that number of followers does not match the influential power. She investigated the data including 54,981,152 user accounts, 1,963,263,821 social links, and 1,755,925,520 Tweets, collected with 50 servers.
The research compares and illustrates the limitations of various methods used to measure the influence a user has on a social networking platform. These results provided new insights and interpretations to the influencer selection algorithm used to maximize the advertizing impact on big social networking platforms.
The research also looked at how long an influential user was active for, and whether the user could freely cross the borders between fields and be influential on different topics as well. By analyzing cases of who becomes an influencer when new events occur, it was shown that a person could quickly become an influencer using several key tactics, unlike what was previously claimed by the ‘accidental influential theory’.
Professor Cha explained, “At the time, data from social networking platforms did not receive much attention in computer science, but I remember those all-nighters I pulled to work on this project, fascinated by the fact that internet data could be used to solve difficult social science problems. I feel so grateful that my research has been endeared for such a long time.”
Professor Cha received both her undergraduate and graduate degrees from KAIST, and conducted this research during her postdoctoral course at the Max Planck Institute in Germany. She now also serves as a chief investigator of a data science group at the Institute for Basic Science (IBS).
(END)
2020.06.22 View 8202
Research on the Million Follower Fallacy Receives the Test of Time Award
Professor Meeyoung Cha’s research investigating the correlation between the number of followers on social media and its influence was re-highlighted after 10 years of publication of the paper.
Saying that her research is still as relevant today as the day it was published 10 years ago, the Association for the Advancement of Artificial Intelligence (AAAI) presented Professor Cha from the School of Computing with the Test of Time Award during the 14th International Conference on Web and Social Media (ICWSM) held online June 8 through 11.
In her 2010 paper titled ‘Measuring User Influence in Twitter: The Million Follower Fallacy,’ Professor Cha proved that number of followers does not match the influential power. She investigated the data including 54,981,152 user accounts, 1,963,263,821 social links, and 1,755,925,520 Tweets, collected with 50 servers.
The research compares and illustrates the limitations of various methods used to measure the influence a user has on a social networking platform. These results provided new insights and interpretations to the influencer selection algorithm used to maximize the advertizing impact on big social networking platforms.
The research also looked at how long an influential user was active for, and whether the user could freely cross the borders between fields and be influential on different topics as well. By analyzing cases of who becomes an influencer when new events occur, it was shown that a person could quickly become an influencer using several key tactics, unlike what was previously claimed by the ‘accidental influential theory’.
Professor Cha explained, “At the time, data from social networking platforms did not receive much attention in computer science, but I remember those all-nighters I pulled to work on this project, fascinated by the fact that internet data could be used to solve difficult social science problems. I feel so grateful that my research has been endeared for such a long time.”
Professor Cha received both her undergraduate and graduate degrees from KAIST, and conducted this research during her postdoctoral course at the Max Planck Institute in Germany. She now also serves as a chief investigator of a data science group at the Institute for Basic Science (IBS).
(END)
2020.06.22 View 8202 -
 Participation in the 2018 Bio-Digital City Workshop in Paris
(A student make a presentatiion during the Bio-Digital City Workshop in Paris last month.)
KAIST students explored ideas for developing future cities during the 2018 Bio-Digital City Workshop held in Paris last month.
This international workshop hosted by Cité des Sciences et de l'Industrie was held under the theme “Biomimicry, Digital City and Big Data.” During the workshop from July 10 to July 20, students teamed up with French counterparts to develop innovative urban design ideas. Cité des Sciences et de l'Industrie is the largest science museum in Europe and is operated by Universcience, a specialized institute of science and technology in France.
Professor Seongju Chang from the Department of Civil and Environmental Engineering and Professor Jihyun Lee of the Graduate School of Culture Technology Students led the students group.
Participants presented their ideas and findings on new urban solutions that combine biomimetic systems and digital technology. Each student group analyzed a special natural ecosystem such as sand dunes, jellyfish communities, or mangrove forests and conducted research to extract algorithms for constructing sustainable urban building complexes based on the results. The extracted algorithm was used to conceive a sustainable building complex forming a part of the urban environment by applying it to the actual Parisian city segment given as the virtual site for the workshop.
Students from diverse background in both countries participated in this convergence workshop. KAIST students included Ph.D. candidate Hyung Min Cho, undergraduates Min-Woo Jeong, Seung-Hwan Cha, and Sang-Jun Park from the Department of Civil and Environmental Engineering, undergraduate Kyeong-Keun Seo from the Department of Materials Science and Engineering, JiWhan Jeong (Master’s course) from the Department of Industrial and Systems Engineering, Ph.D. candidate Bo-Yoon Zang from the Graduate School of Culture Technology. They teamed up with French students from diverse backgrounds, including Design/Science, Visual Design, Geography, Computer Science and Humanities and Social Science.
This workshop will serve as another opportunity to expand academic and human exchange efforts in the domain of smart and sustainable cities with Europe in the future as the first international cooperation activity of KAIST and the Paris La Villette Science Museum.
Professor Seong-Ju Chang who led the research group said, "We will continue to establish a cooperative relationship between KAIST and the European scientific community. This workshop is a good opportunity to demonstrate the competence of KAIST students and their scientific and technological excellence on the international stage.”
2018.08.01 View 12601
Participation in the 2018 Bio-Digital City Workshop in Paris
(A student make a presentatiion during the Bio-Digital City Workshop in Paris last month.)
KAIST students explored ideas for developing future cities during the 2018 Bio-Digital City Workshop held in Paris last month.
This international workshop hosted by Cité des Sciences et de l'Industrie was held under the theme “Biomimicry, Digital City and Big Data.” During the workshop from July 10 to July 20, students teamed up with French counterparts to develop innovative urban design ideas. Cité des Sciences et de l'Industrie is the largest science museum in Europe and is operated by Universcience, a specialized institute of science and technology in France.
Professor Seongju Chang from the Department of Civil and Environmental Engineering and Professor Jihyun Lee of the Graduate School of Culture Technology Students led the students group.
Participants presented their ideas and findings on new urban solutions that combine biomimetic systems and digital technology. Each student group analyzed a special natural ecosystem such as sand dunes, jellyfish communities, or mangrove forests and conducted research to extract algorithms for constructing sustainable urban building complexes based on the results. The extracted algorithm was used to conceive a sustainable building complex forming a part of the urban environment by applying it to the actual Parisian city segment given as the virtual site for the workshop.
Students from diverse background in both countries participated in this convergence workshop. KAIST students included Ph.D. candidate Hyung Min Cho, undergraduates Min-Woo Jeong, Seung-Hwan Cha, and Sang-Jun Park from the Department of Civil and Environmental Engineering, undergraduate Kyeong-Keun Seo from the Department of Materials Science and Engineering, JiWhan Jeong (Master’s course) from the Department of Industrial and Systems Engineering, Ph.D. candidate Bo-Yoon Zang from the Graduate School of Culture Technology. They teamed up with French students from diverse backgrounds, including Design/Science, Visual Design, Geography, Computer Science and Humanities and Social Science.
This workshop will serve as another opportunity to expand academic and human exchange efforts in the domain of smart and sustainable cities with Europe in the future as the first international cooperation activity of KAIST and the Paris La Villette Science Museum.
Professor Seong-Ju Chang who led the research group said, "We will continue to establish a cooperative relationship between KAIST and the European scientific community. This workshop is a good opportunity to demonstrate the competence of KAIST students and their scientific and technological excellence on the international stage.”
2018.08.01 View 12601 -
 Strengthening Industry-Academia Cooperation with LG CNS
On November 20, KAIST signed an MoU with LG CNS for industry-academia partnership in education, research, and business in the fields of AI and Big Data. Rather than simply developing education programs or supporting industry-academia scholarships, both organizations agreed to carry out a joint research project on AI and Big Data that can be applied to practical business.
KAIST will collaborate with LG CNS in the fields of smart factories, customer analysis, and supply chain management analysis.
Not only will LG CNS offer internships to KAIST students, but it also will support professors and students who propose innovative startup ideas for AI and Big Data. Offering an industry-academia scholarship for graduate students is also being discussed. Together with LG CNS, KAIST will put its efforts into propose projects regarding AI and Big Data in the public sector.
Furthermore, KAIST and LG CNS will jointly explore and carry out industry-academia projects that could be practically used in business. Both will carry out the project vigorously through strong cooperation; for instance, LG CNS employees can be assigned to KAIST, if necessary. Also, LG CNS’s AI and Big Data platform, called DAP (Data Analytics & AI Platform) will be used as a data analysis tool during the project and the joint outcomes will be installed in DAP.
KAIST professors with expertise in AI deep learning have trained LG CNS employees since the Department of Industrial & Systems Engineering established ‘KAIST AI Academy’ in LG CNS last August.
“With KAIST, the best research-centered university in Korea, we will continue to lead in developing the field of AI and Big Data and provide innovative services that create value by connecting them to customer business,” Yong Shub Kim, the CEO of LG CNS, highlighted.
2017.11.22 View 13237
Strengthening Industry-Academia Cooperation with LG CNS
On November 20, KAIST signed an MoU with LG CNS for industry-academia partnership in education, research, and business in the fields of AI and Big Data. Rather than simply developing education programs or supporting industry-academia scholarships, both organizations agreed to carry out a joint research project on AI and Big Data that can be applied to practical business.
KAIST will collaborate with LG CNS in the fields of smart factories, customer analysis, and supply chain management analysis.
Not only will LG CNS offer internships to KAIST students, but it also will support professors and students who propose innovative startup ideas for AI and Big Data. Offering an industry-academia scholarship for graduate students is also being discussed. Together with LG CNS, KAIST will put its efforts into propose projects regarding AI and Big Data in the public sector.
Furthermore, KAIST and LG CNS will jointly explore and carry out industry-academia projects that could be practically used in business. Both will carry out the project vigorously through strong cooperation; for instance, LG CNS employees can be assigned to KAIST, if necessary. Also, LG CNS’s AI and Big Data platform, called DAP (Data Analytics & AI Platform) will be used as a data analysis tool during the project and the joint outcomes will be installed in DAP.
KAIST professors with expertise in AI deep learning have trained LG CNS employees since the Department of Industrial & Systems Engineering established ‘KAIST AI Academy’ in LG CNS last August.
“With KAIST, the best research-centered university in Korea, we will continue to lead in developing the field of AI and Big Data and provide innovative services that create value by connecting them to customer business,” Yong Shub Kim, the CEO of LG CNS, highlighted.
2017.11.22 View 13237 -
 KAIST Professors Sweep the Best Science and Technology Award
(Distinguished Professors Sang Yup Lee (left) and Kyu-Young Whang)
Distinguished Professors Sang Yup Lee from the Department of Chemical and Biomolecular Engineering and Kyu-Young Whang of the College of Computing were selected as the winners of the "2017 Korea Best Science and Technology Award" by the Ministry of Science, ICT and Future Planning (MSIP) and the Korea Federation of Science and Technology Societies.
The award, which was established in 2003, is the highest honor bestowed to the two most outstanding scientists in Korea annually. This is the first time that KAIST faculty members have swept the award since its founding.
Distinguished Professor Lee is renowned for his pioneering studies of system metabolic engineering, which produces useful chemicals by utilizing microorganisms. Professor Lee has developed a number of globally-recognized original technologies such as gasoline production using micro-organisms, a bio-butanol production process, microbes for producing nylon and plastic raw materials, and making native-like spider silk produced in metabolically engineering bacterium which is stronger than steel but finer than human hair.
System metabolism engineering was also selected as one of the top 10 promising technologies in the world in 2016 by the World Economic Forum. Selected as one of the world’s top 20 applied bioscientists in 2014 by Nature Biotechnology, he has many ‘first’ titles in his academic and research careers. He was the first Asian to win the James Bailey Award (2016) and Marvin Johnson Award (2012), the first Korean elected to both the US National Academy of Science (NAS) and the National Academy of Engineering (NAE) this year. He is the dean of KAIST institutes, a multi and interdisciplinary research institute at KAIST. He serves as co-chair of the Global Council on Biotechnology and as a member of the Global Future Council on the Fourth Industrial Revolution at the World Economic Forum.
Distinguished Professor Whang, the first recipient in the field of computer science in this award, has been recognized for his lifetime achievement and contributions to the development of the software industry and the spreading of information culture. He has taken a pioneering role in presenting novel theories and innovative technologies in the field of database systems such as probabilistic aggregation, multidimensional indexing, query, and database and information retrieval. The Odysseus database management system Professor Hwang developed has been applied in many diverse fields of industry, while promoting the domestic software industry and its technical independence.
Professor Hwang is a fellow at the American Computer Society (ACM) and life fellow at IEEE. Professor Whang received the ACM SIGMOD Contributions Award in 2014 for his work promoting database research worldwide, the PAKDD Distinguished Contributions Award in 2014, and the DASFAA Outstanding Contributions Award in 2011 for his contributions to database and data mining research in the Asia-Pacific region. He is also the recipient of the prestigious Korea (presidential) Engineering Award in 2012.
2017.07.03 View 12660
KAIST Professors Sweep the Best Science and Technology Award
(Distinguished Professors Sang Yup Lee (left) and Kyu-Young Whang)
Distinguished Professors Sang Yup Lee from the Department of Chemical and Biomolecular Engineering and Kyu-Young Whang of the College of Computing were selected as the winners of the "2017 Korea Best Science and Technology Award" by the Ministry of Science, ICT and Future Planning (MSIP) and the Korea Federation of Science and Technology Societies.
The award, which was established in 2003, is the highest honor bestowed to the two most outstanding scientists in Korea annually. This is the first time that KAIST faculty members have swept the award since its founding.
Distinguished Professor Lee is renowned for his pioneering studies of system metabolic engineering, which produces useful chemicals by utilizing microorganisms. Professor Lee has developed a number of globally-recognized original technologies such as gasoline production using micro-organisms, a bio-butanol production process, microbes for producing nylon and plastic raw materials, and making native-like spider silk produced in metabolically engineering bacterium which is stronger than steel but finer than human hair.
System metabolism engineering was also selected as one of the top 10 promising technologies in the world in 2016 by the World Economic Forum. Selected as one of the world’s top 20 applied bioscientists in 2014 by Nature Biotechnology, he has many ‘first’ titles in his academic and research careers. He was the first Asian to win the James Bailey Award (2016) and Marvin Johnson Award (2012), the first Korean elected to both the US National Academy of Science (NAS) and the National Academy of Engineering (NAE) this year. He is the dean of KAIST institutes, a multi and interdisciplinary research institute at KAIST. He serves as co-chair of the Global Council on Biotechnology and as a member of the Global Future Council on the Fourth Industrial Revolution at the World Economic Forum.
Distinguished Professor Whang, the first recipient in the field of computer science in this award, has been recognized for his lifetime achievement and contributions to the development of the software industry and the spreading of information culture. He has taken a pioneering role in presenting novel theories and innovative technologies in the field of database systems such as probabilistic aggregation, multidimensional indexing, query, and database and information retrieval. The Odysseus database management system Professor Hwang developed has been applied in many diverse fields of industry, while promoting the domestic software industry and its technical independence.
Professor Hwang is a fellow at the American Computer Society (ACM) and life fellow at IEEE. Professor Whang received the ACM SIGMOD Contributions Award in 2014 for his work promoting database research worldwide, the PAKDD Distinguished Contributions Award in 2014, and the DASFAA Outstanding Contributions Award in 2011 for his contributions to database and data mining research in the Asia-Pacific region. He is also the recipient of the prestigious Korea (presidential) Engineering Award in 2012.
2017.07.03 View 12660 -
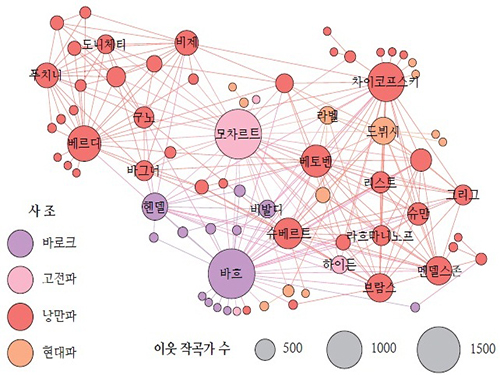 Big Data Reveals the Secret of Classical Music Creation
Professor Juyong Park of the Graduate School of Culture Technology at KAIST and his research team have recently published the result of their study (“Topology and Evolution of the Network of Western Classical Music Composers”) on the dynamics of how classical music is created, stylized, and disseminated in EPJ Data Science online on April 22, 2015. For the press release issued by the journal, please go to the link below:
EPJ Data Science, May 6, 2015
“EPJ Data Science Highlight—Big Data Reveals Classical Music Creation Secrets”
http://www.epj.org/113-epj-ds/941-epjds-highlight-big-data-reveals-classical-music-creation-secrets
Researchers used big-data analysis and modelling technique to examine the complex, undercurrent network of classical music composers, which was constructed from the large volume of compact disc (CD) recordings data collected from an online retailer, ArkivMusic, and a music reference website, AllMusicGuide.
The study discovered that the basic characteristics of composers’ network are similar to many real-world networks, including the small-world property, the existence of a giant component, high clustering, and heavy-tailed degree distributions. The research team also found that composers collaborated and influenced each other and that composers’ networks grew over time.
The research showed that consumers of classical music CDs tend to listen together to the music of a certain group of different composers, offering a useful tool to understand how the music style and market develops. Based on this, the research team predicted the future of the classical music market would be centered on top composers, while maintaining diversity due to the growing number of new composers.
Professor Park said, “In recent years, technology greatly affects the way we consume culture and art. Accordingly, we see more and more artists and institutions try to incorporate technology into their creative process, and this will lead us to larger- and higher-quality data that can allow us to learn more about culture and art. The quantitative methodology we have demonstrated in our research will give us an opportunity to explore the nature of art and literature in novel ways.”
The European Physical Journal (EPJ) comprises a series of peer-reviewed journals, eleven in total, which cover physics and related subjects such as The Large Hadron Collider, condensed matter, particles, soft matter, and biological physics. The EPJ Data Science is the latest journal launched by EPJ.
Figure: Backbone of the Composer Network
The composer-composer network backbone, projected from the CD-composer network, reveals the major component of the network. The node sizes represent the composers’ degrees, and the colors represent their active periods.
2015.05.07 View 11382
Big Data Reveals the Secret of Classical Music Creation
Professor Juyong Park of the Graduate School of Culture Technology at KAIST and his research team have recently published the result of their study (“Topology and Evolution of the Network of Western Classical Music Composers”) on the dynamics of how classical music is created, stylized, and disseminated in EPJ Data Science online on April 22, 2015. For the press release issued by the journal, please go to the link below:
EPJ Data Science, May 6, 2015
“EPJ Data Science Highlight—Big Data Reveals Classical Music Creation Secrets”
http://www.epj.org/113-epj-ds/941-epjds-highlight-big-data-reveals-classical-music-creation-secrets
Researchers used big-data analysis and modelling technique to examine the complex, undercurrent network of classical music composers, which was constructed from the large volume of compact disc (CD) recordings data collected from an online retailer, ArkivMusic, and a music reference website, AllMusicGuide.
The study discovered that the basic characteristics of composers’ network are similar to many real-world networks, including the small-world property, the existence of a giant component, high clustering, and heavy-tailed degree distributions. The research team also found that composers collaborated and influenced each other and that composers’ networks grew over time.
The research showed that consumers of classical music CDs tend to listen together to the music of a certain group of different composers, offering a useful tool to understand how the music style and market develops. Based on this, the research team predicted the future of the classical music market would be centered on top composers, while maintaining diversity due to the growing number of new composers.
Professor Park said, “In recent years, technology greatly affects the way we consume culture and art. Accordingly, we see more and more artists and institutions try to incorporate technology into their creative process, and this will lead us to larger- and higher-quality data that can allow us to learn more about culture and art. The quantitative methodology we have demonstrated in our research will give us an opportunity to explore the nature of art and literature in novel ways.”
The European Physical Journal (EPJ) comprises a series of peer-reviewed journals, eleven in total, which cover physics and related subjects such as The Large Hadron Collider, condensed matter, particles, soft matter, and biological physics. The EPJ Data Science is the latest journal launched by EPJ.
Figure: Backbone of the Composer Network
The composer-composer network backbone, projected from the CD-composer network, reveals the major component of the network. The node sizes represent the composers’ degrees, and the colors represent their active periods.
2015.05.07 View 11382 -
 2014 Conference on Korean Sociology Held at KAIST
The Korean Sociological Association (KSA) hosted a two-day conference in 2014 entitled “In the age of anxiety, sociology can present answers” at the College of Liberal Arts and Convergence Science, KAIST, on June 20-21, 2014. Professor Jung-Ro Yoon of the Department of Humanities and Social Sciences at KAIST is the President of KSA. The conference addressed issues such as big data and risk society. During the conference, 40 sessions took place, and 150 research papers were released.
Professor Yoon said, “The conference will offer a great opportunity for Korean sociologists to discuss anxiety, chaos, risk, and the uncertainty that Korean society experiences and suggest answers and a new vision upon which Korean society should move forward.”
2014.06.22 View 8837
2014 Conference on Korean Sociology Held at KAIST
The Korean Sociological Association (KSA) hosted a two-day conference in 2014 entitled “In the age of anxiety, sociology can present answers” at the College of Liberal Arts and Convergence Science, KAIST, on June 20-21, 2014. Professor Jung-Ro Yoon of the Department of Humanities and Social Sciences at KAIST is the President of KSA. The conference addressed issues such as big data and risk society. During the conference, 40 sessions took place, and 150 research papers were released.
Professor Yoon said, “The conference will offer a great opportunity for Korean sociologists to discuss anxiety, chaos, risk, and the uncertainty that Korean society experiences and suggest answers and a new vision upon which Korean society should move forward.”
2014.06.22 View 8837 -
 KAIST to Hold "Data Science Workshop"
Discussion regarding the scientific utilization of data and its future possibilityThe upcoming 2nd Data Science Workshop is to be held at COEX, Seoul, on 27th February‘Big Data’ has attracted the explosion of interest in recent years. KAIST has arranged a platform of discussion for the utilization of data science and its possible usage in the future.The Department of Knowledge Services Engineering at KAIST is to hold the 2nd Knowledge Services Workshop under the topic of "Data Science for Industry" at COEX, Seoul, on 27th February.Data Science refers to using scientific approach to extract generalized knowledge from the data in order to find meaningful information.With the era of Big Data ahead, the amounts of data produced by the industry are rapidly increasing. The companies have recognized the significance of the data, however, the understanding of its systematic utilization is yet to be realized."Data Science Workshop" has been organized to discuss on how to create a new value using the data compiled by the industry. Lectures are to be given by four leading professionals in the field of data science, who are the professors from Department of Knowledge Services Engineering at KAIST. The head of the department, Mun-Yong Lee, said, “This workshop will be an opportunity for the companies that are considering introducing data science, as well as the students who are interested in the related field, to think about the possibility and future of data science.”Pre-registration for the workshop is currently open until 23rd February on the official website (http://kseworkshop.kaist.ac.kr).
2014.02.20 View 10134
KAIST to Hold "Data Science Workshop"
Discussion regarding the scientific utilization of data and its future possibilityThe upcoming 2nd Data Science Workshop is to be held at COEX, Seoul, on 27th February‘Big Data’ has attracted the explosion of interest in recent years. KAIST has arranged a platform of discussion for the utilization of data science and its possible usage in the future.The Department of Knowledge Services Engineering at KAIST is to hold the 2nd Knowledge Services Workshop under the topic of "Data Science for Industry" at COEX, Seoul, on 27th February.Data Science refers to using scientific approach to extract generalized knowledge from the data in order to find meaningful information.With the era of Big Data ahead, the amounts of data produced by the industry are rapidly increasing. The companies have recognized the significance of the data, however, the understanding of its systematic utilization is yet to be realized."Data Science Workshop" has been organized to discuss on how to create a new value using the data compiled by the industry. Lectures are to be given by four leading professionals in the field of data science, who are the professors from Department of Knowledge Services Engineering at KAIST. The head of the department, Mun-Yong Lee, said, “This workshop will be an opportunity for the companies that are considering introducing data science, as well as the students who are interested in the related field, to think about the possibility and future of data science.”Pre-registration for the workshop is currently open until 23rd February on the official website (http://kseworkshop.kaist.ac.kr).
2014.02.20 View 10134