School+of+Computing
-
 KAIST Invites World-Renowned Scholars, Elevating Global Competitiveness
< Photo 1. (From left) Professor John Rogers, Professor Gregg Rothermel, Dr. Sang H. Choi >
KAIST announced on June 27th that it has appointed three world-renowned scholars, including Professor John A. Rogers of Northwestern University, USA, as Invited Distinguished Professors in key departments such as Materials Science and Engineering.
Professor John A. Rogers (Northwestern University, USA) will be working with the Department of Materials Science and Engineering from July 2025 to June 2028 with Professor Gregg Rothermel (North Carolina State University, USA) working with the School of Computing from August 2025 to July 2026, and Dr. Sang H. Choi (NASA Langley Research Center, USA) with the Department of Aerospace Engineering from May 2025 to April 2028.
Professor John A. Rogers, a person of global authority in the field of bio-integrated electronics, has been leading advanced convergence technologies such as flexible electronics, smart skin, and implantable sensors. His significant impact on academia and industry is evident through over 900 papers published in top-tier academic journals like Science, Nature, and Cell, and he comes in an H-index of 240*. His research group, the Rogers Research Group at Northwestern University, focuses on "Science that brings Solutions to Society," encompassing areas such as bio-integrated microsystems and unconventional nanofabrication techniques. He is the founding Director of the Querrey-Simpson Institute of Bioelectronics at Northwestern University.
* H-index 240: An H-index is a measurement used to assess the research productivity and impact of an individual authors. H-index 240 means that 240 or more papers have been cited at least 240 times each, indicating a significant impact and the presumable status as a world-class scholar.
The Department of Materials Science and Engineering plans to further enhance its research capabilities in next-generation bio-implantable materials and wearable devices and boost its global competitiveness through the invitation of Professor Rogers. In particular, it aims to create strong research synergies by linking with the development of bio-convergence interface materials, a core task of the Leading Research Center (ERC, total research budget of 13.5 billion KRW over 7 years) led by Professor Kun-Jae Lee.
Professor Gregg Rothermel, a world-renowned scholar in software engineering, was ranked second among the top 50 global researchers by Communications of the ACM. For over 30 years, he has conducted practical research to improve software reliability and quality. He has achieved influential research outcomes through collaborations with global companies such as Boeing, Microsoft, and Lockheed Martin. Dr. Rothermel's research at North Carolina State University focuses on software engineering and program analysis, with significant contributions through initiatives like the ESQuaReD Laboratory and the Software-Artifact Infrastructure Repository (SIR).
The School of Computing plans to strengthen its research capabilities in software engineering and conduct collaborative research on software design and testing to enhance the reliability and safety of AI-based software systems through the invitation of Professor Gregg Rothermel. In particular, he is expected to participate in the Big Data Edge-Cloud Service Research Center (ITRC, total research budget of 6.7 billion KRW over 8 years) led by Professor In-Young Ko of the School of Computing, and the Research on Improving Complex Mobility Safety (SafetyOps, Digital Columbus Project, total research budget of 3.5 billion KRW over 8 years), contributing to resolving uncertainties in machine learning-based AI software and advancing technology.
Dr. Sang H. Choi, a global expert in space exploration and energy harvesting, has worked at NASA Langley Research Center for over 40 years, authoring over 200 papers and reports, holding 45 patents, and receiving 71 awards from NASA. In 2022, he was inducted into the 'Inventors Hall of Fame' as part of NASA's Technology Transfer Program. This is a rare honor, recognizing researchers who have contributed to the private sector dissemination of space exploration technology, with only 35 individuals worldwide selected to date. Dr. Choi's extensive work at NASA includes research on advanced electronic and energetic materials, satellite sensors, and various nano-technologies.
Dr. Choi plans to collaborate with Associate Professor Hyun-Jung Kim (former NASA Research Scientist, 2009-2024), who joined the Department of Aerospace Engineering in September of 2024, to lead the development of core technologies for lunar exploration (energy sources, sensing, in-situ resource utilization ISRU).
KAIST President Kwang Hyung Lee stated, "It is very meaningful to be able to invite these world-class scholars. Through these appointments, KAIST will further strengthen its global competitiveness in research in the fields of advanced convergence technology such as bio-convergence electronics, AI software engineering, and space exploration, securing our position as the leader of global innovations."
2025.06.27 View 497
KAIST Invites World-Renowned Scholars, Elevating Global Competitiveness
< Photo 1. (From left) Professor John Rogers, Professor Gregg Rothermel, Dr. Sang H. Choi >
KAIST announced on June 27th that it has appointed three world-renowned scholars, including Professor John A. Rogers of Northwestern University, USA, as Invited Distinguished Professors in key departments such as Materials Science and Engineering.
Professor John A. Rogers (Northwestern University, USA) will be working with the Department of Materials Science and Engineering from July 2025 to June 2028 with Professor Gregg Rothermel (North Carolina State University, USA) working with the School of Computing from August 2025 to July 2026, and Dr. Sang H. Choi (NASA Langley Research Center, USA) with the Department of Aerospace Engineering from May 2025 to April 2028.
Professor John A. Rogers, a person of global authority in the field of bio-integrated electronics, has been leading advanced convergence technologies such as flexible electronics, smart skin, and implantable sensors. His significant impact on academia and industry is evident through over 900 papers published in top-tier academic journals like Science, Nature, and Cell, and he comes in an H-index of 240*. His research group, the Rogers Research Group at Northwestern University, focuses on "Science that brings Solutions to Society," encompassing areas such as bio-integrated microsystems and unconventional nanofabrication techniques. He is the founding Director of the Querrey-Simpson Institute of Bioelectronics at Northwestern University.
* H-index 240: An H-index is a measurement used to assess the research productivity and impact of an individual authors. H-index 240 means that 240 or more papers have been cited at least 240 times each, indicating a significant impact and the presumable status as a world-class scholar.
The Department of Materials Science and Engineering plans to further enhance its research capabilities in next-generation bio-implantable materials and wearable devices and boost its global competitiveness through the invitation of Professor Rogers. In particular, it aims to create strong research synergies by linking with the development of bio-convergence interface materials, a core task of the Leading Research Center (ERC, total research budget of 13.5 billion KRW over 7 years) led by Professor Kun-Jae Lee.
Professor Gregg Rothermel, a world-renowned scholar in software engineering, was ranked second among the top 50 global researchers by Communications of the ACM. For over 30 years, he has conducted practical research to improve software reliability and quality. He has achieved influential research outcomes through collaborations with global companies such as Boeing, Microsoft, and Lockheed Martin. Dr. Rothermel's research at North Carolina State University focuses on software engineering and program analysis, with significant contributions through initiatives like the ESQuaReD Laboratory and the Software-Artifact Infrastructure Repository (SIR).
The School of Computing plans to strengthen its research capabilities in software engineering and conduct collaborative research on software design and testing to enhance the reliability and safety of AI-based software systems through the invitation of Professor Gregg Rothermel. In particular, he is expected to participate in the Big Data Edge-Cloud Service Research Center (ITRC, total research budget of 6.7 billion KRW over 8 years) led by Professor In-Young Ko of the School of Computing, and the Research on Improving Complex Mobility Safety (SafetyOps, Digital Columbus Project, total research budget of 3.5 billion KRW over 8 years), contributing to resolving uncertainties in machine learning-based AI software and advancing technology.
Dr. Sang H. Choi, a global expert in space exploration and energy harvesting, has worked at NASA Langley Research Center for over 40 years, authoring over 200 papers and reports, holding 45 patents, and receiving 71 awards from NASA. In 2022, he was inducted into the 'Inventors Hall of Fame' as part of NASA's Technology Transfer Program. This is a rare honor, recognizing researchers who have contributed to the private sector dissemination of space exploration technology, with only 35 individuals worldwide selected to date. Dr. Choi's extensive work at NASA includes research on advanced electronic and energetic materials, satellite sensors, and various nano-technologies.
Dr. Choi plans to collaborate with Associate Professor Hyun-Jung Kim (former NASA Research Scientist, 2009-2024), who joined the Department of Aerospace Engineering in September of 2024, to lead the development of core technologies for lunar exploration (energy sources, sensing, in-situ resource utilization ISRU).
KAIST President Kwang Hyung Lee stated, "It is very meaningful to be able to invite these world-class scholars. Through these appointments, KAIST will further strengthen its global competitiveness in research in the fields of advanced convergence technology such as bio-convergence electronics, AI software engineering, and space exploration, securing our position as the leader of global innovations."
2025.06.27 View 497 -
 KAIST School of Computing Unveils 'KRAFTON Building,' A Symbol of Collective Generosity
< (From the fifth from the left) Provost and Executive Vice President Gyun Min Lee, Auditor Eun Woo Lee, President Kwang-Hyung Lee, Dean of the School of Computing Seok-Young Ryu, former Krafton member and donor Woong-Hee Cho, Krafton Chairman Byung-Gyu Chang >
KAIST announced on May 20th the completion of the expansion building for its School of Computing, the "KRAFTON Building." The project began in June 2021 with an ₩11 billion donation from KRAFTON and its employees, eventually growing to ₩11.7 billion with contributions from 204 donors.
Designed as a "Pay It Forward" space, the building aims to enable alumni to pass on the gratitude they received from the school to their juniors and foster connection. Byung-Gyu Chang, Chairman of KRAFTON and a KAIST alumnus, expressed his joy, stating, "I am very pleased that the first building created by alumni donations within KAIST is now complete, and I hope it will continue to be a space for communication, challenges, and growth that connects to the next generation."
The completion ceremony, held today at 3 PM in front of the KRAFTON SoC (School of Computing) Building at KAIST's main campus, was attended by over 100 people, including Chairman Byung-Gyu Chang, KAIST President Kwang-Hyung Lee, and Dean Seok-Young Ryu of the KAIST School of Computing.
The building's inception dates back to June 2021, with an ₩11 billion donation from the gaming company KRAFTON and its current and former members, dedicated to nurturing future software talent at KAIST. Four alumni, including KRAFTON Chairman Byung-Gyu Chang, who graduated from the KAIST School of Computing, were the first to pledge donations. This initial act inspired more participants, leading to ₩5.5 billion in individual donations from a total of 11 people. KRAFTON Inc. then matched this amount, bringing the total donation to ₩11 billion.
Since 2021, KRAFTON Inc. has operated a "Matching Grant" program, a donation culture initiative driven by its members. This system allows the company to match funds voluntarily raised by its employees, aiming to encourage active social participation and the creation of social value among its members.
Following this, another 11 KAIST alumni from Devsisters Inc., famous for the Cookie Run series, joined the donation effort. This wave of generosity expanded to include a total of 204 participants, comprising graduates, alumni professors, and current students, acting as a catalyst for the spread of a donation culture within the campus. To date, approximately ₩11.7 billion has been raised for the expansion of the School of Computing building. Furthermore, small donations, including those from alumni and the general public, have continuously grown, reaching over 50,000 instances from 2021 to May 2025.
The funds raised through donations were used to construct a 2,000-pyeong (approximately 6,600 square meters) building for individuals who, like Chairman Byung-Gyu Chang, will unleash their potential and become global leaders. The building was named "KRAFTON SoC (KRAFTON SoC)," and KRAFTON Inc. has further pledged additional donations for the building's maintenance over the next 10 years.
The newly completed KRAFTON Building is a six-story structure. From the second floor up, it features research labs for 20 professors and graduate students to freely pursue their research, along with large lecture halls. The first floor is designed as a meeting place for current students, alumni, and seniors, serving as a space to remember those who came before them.
The four lecture halls on the first floor are designated as "Immersion Camp Classrooms." During the summer and winter sessions, these rooms will be used for intensive month-long courses focused on improving coding and collaboration skills. During regular semesters, they will be utilized for other lectures.
Additionally, to support the physical and mental well-being of those weary from study and research, the building includes a small café on the first floor, a fitness center on the second floor, a Pilates studio on the fifth floor, and a soundproof band practice room in the basement.
Dean Seok-Young Ryu of the School of Computing explained, "The motivation for this wave of donations began with gratitude for the excellent professors and wonderful students, the free and open communication, the comfortable acceptance of diversity among various members, and the time when we could fearlessly dream. We cannot fully repay those who provided us with such precious time and space, but instead, this will be a 'Pay It Forward' space, a space of connection, where we share this gratitude with our juniors."
Alumnus Byung-Gyu Chang shared, "KAIST is more than just an academic foundation for me; it's a meaningful place that helped me set the direction for my life. I am very happy that this space, born from the desire of KRAFTON's members and myself to give back the opportunities and learning we received to the next generation, is completed today. I hope this space becomes a small but warm echo for KAIST members who freely communicate, challenge themselves, and grow."
< Congratulatory speech by alumnus Byung-Gyu Chang >
President Kwang-Hyung Lee stated, "The KRAFTON SoC, the expanded building for the School of Computing, is not just a space; it is the culmination of the KAIST community spirit created by alumni, current students, and faculty. I sincerely thank everyone who participated in this meaningful donation, which demonstrates the power of sharing and connection."
< Commemorative speech by President Kwang-Hyung Lee >
On a related note, the KAIST Development Foundation is actively promoting the "TeamKAIST" campaign for the general public and KAIST alumni to meet more "Daddy Long-Legs" (benefactors) for KAIST.
Website: https://giving.kaist.ac.kr/ko/sub01/sub0103_1.php
2025.05.21 View 2049
KAIST School of Computing Unveils 'KRAFTON Building,' A Symbol of Collective Generosity
< (From the fifth from the left) Provost and Executive Vice President Gyun Min Lee, Auditor Eun Woo Lee, President Kwang-Hyung Lee, Dean of the School of Computing Seok-Young Ryu, former Krafton member and donor Woong-Hee Cho, Krafton Chairman Byung-Gyu Chang >
KAIST announced on May 20th the completion of the expansion building for its School of Computing, the "KRAFTON Building." The project began in June 2021 with an ₩11 billion donation from KRAFTON and its employees, eventually growing to ₩11.7 billion with contributions from 204 donors.
Designed as a "Pay It Forward" space, the building aims to enable alumni to pass on the gratitude they received from the school to their juniors and foster connection. Byung-Gyu Chang, Chairman of KRAFTON and a KAIST alumnus, expressed his joy, stating, "I am very pleased that the first building created by alumni donations within KAIST is now complete, and I hope it will continue to be a space for communication, challenges, and growth that connects to the next generation."
The completion ceremony, held today at 3 PM in front of the KRAFTON SoC (School of Computing) Building at KAIST's main campus, was attended by over 100 people, including Chairman Byung-Gyu Chang, KAIST President Kwang-Hyung Lee, and Dean Seok-Young Ryu of the KAIST School of Computing.
The building's inception dates back to June 2021, with an ₩11 billion donation from the gaming company KRAFTON and its current and former members, dedicated to nurturing future software talent at KAIST. Four alumni, including KRAFTON Chairman Byung-Gyu Chang, who graduated from the KAIST School of Computing, were the first to pledge donations. This initial act inspired more participants, leading to ₩5.5 billion in individual donations from a total of 11 people. KRAFTON Inc. then matched this amount, bringing the total donation to ₩11 billion.
Since 2021, KRAFTON Inc. has operated a "Matching Grant" program, a donation culture initiative driven by its members. This system allows the company to match funds voluntarily raised by its employees, aiming to encourage active social participation and the creation of social value among its members.
Following this, another 11 KAIST alumni from Devsisters Inc., famous for the Cookie Run series, joined the donation effort. This wave of generosity expanded to include a total of 204 participants, comprising graduates, alumni professors, and current students, acting as a catalyst for the spread of a donation culture within the campus. To date, approximately ₩11.7 billion has been raised for the expansion of the School of Computing building. Furthermore, small donations, including those from alumni and the general public, have continuously grown, reaching over 50,000 instances from 2021 to May 2025.
The funds raised through donations were used to construct a 2,000-pyeong (approximately 6,600 square meters) building for individuals who, like Chairman Byung-Gyu Chang, will unleash their potential and become global leaders. The building was named "KRAFTON SoC (KRAFTON SoC)," and KRAFTON Inc. has further pledged additional donations for the building's maintenance over the next 10 years.
The newly completed KRAFTON Building is a six-story structure. From the second floor up, it features research labs for 20 professors and graduate students to freely pursue their research, along with large lecture halls. The first floor is designed as a meeting place for current students, alumni, and seniors, serving as a space to remember those who came before them.
The four lecture halls on the first floor are designated as "Immersion Camp Classrooms." During the summer and winter sessions, these rooms will be used for intensive month-long courses focused on improving coding and collaboration skills. During regular semesters, they will be utilized for other lectures.
Additionally, to support the physical and mental well-being of those weary from study and research, the building includes a small café on the first floor, a fitness center on the second floor, a Pilates studio on the fifth floor, and a soundproof band practice room in the basement.
Dean Seok-Young Ryu of the School of Computing explained, "The motivation for this wave of donations began with gratitude for the excellent professors and wonderful students, the free and open communication, the comfortable acceptance of diversity among various members, and the time when we could fearlessly dream. We cannot fully repay those who provided us with such precious time and space, but instead, this will be a 'Pay It Forward' space, a space of connection, where we share this gratitude with our juniors."
Alumnus Byung-Gyu Chang shared, "KAIST is more than just an academic foundation for me; it's a meaningful place that helped me set the direction for my life. I am very happy that this space, born from the desire of KRAFTON's members and myself to give back the opportunities and learning we received to the next generation, is completed today. I hope this space becomes a small but warm echo for KAIST members who freely communicate, challenge themselves, and grow."
< Congratulatory speech by alumnus Byung-Gyu Chang >
President Kwang-Hyung Lee stated, "The KRAFTON SoC, the expanded building for the School of Computing, is not just a space; it is the culmination of the KAIST community spirit created by alumni, current students, and faculty. I sincerely thank everyone who participated in this meaningful donation, which demonstrates the power of sharing and connection."
< Commemorative speech by President Kwang-Hyung Lee >
On a related note, the KAIST Development Foundation is actively promoting the "TeamKAIST" campaign for the general public and KAIST alumni to meet more "Daddy Long-Legs" (benefactors) for KAIST.
Website: https://giving.kaist.ac.kr/ko/sub01/sub0103_1.php
2025.05.21 View 2049 -
 KAIST Develops Insect-Eye-Inspired Camera Capturing 9,120 Frames Per Second
< (From left) Bio and Brain Engineering PhD Student Jae-Myeong Kwon, Professor Ki-Hun Jeong, PhD Student Hyun-Kyung Kim, PhD Student Young-Gil Cha, and Professor Min H. Kim of the School of Computing >
The compound eyes of insects can detect fast-moving objects in parallel and, in low-light conditions, enhance sensitivity by integrating signals over time to determine motion. Inspired by these biological mechanisms, KAIST researchers have successfully developed a low-cost, high-speed camera that overcomes the limitations of frame rate and sensitivity faced by conventional high-speed cameras.
KAIST (represented by President Kwang Hyung Lee) announced on the 16th of January that a research team led by Professors Ki-Hun Jeong (Department of Bio and Brain Engineering) and Min H. Kim (School of Computing) has developed a novel bio-inspired camera capable of ultra-high-speed imaging with high sensitivity by mimicking the visual structure of insect eyes.
High-quality imaging under high-speed and low-light conditions is a critical challenge in many applications. While conventional high-speed cameras excel in capturing fast motion, their sensitivity decreases as frame rates increase because the time available to collect light is reduced.
To address this issue, the research team adopted an approach similar to insect vision, utilizing multiple optical channels and temporal summation. Unlike traditional monocular camera systems, the bio-inspired camera employs a compound-eye-like structure that allows for the parallel acquisition of frames from different time intervals.
< Figure 1. (A) Vision in a fast-eyed insect. Reflected light from swiftly moving objects sequentially stimulates the photoreceptors along the individual optical channels called ommatidia, of which the visual signals are separately and parallelly processed via the lamina and medulla. Each neural response is temporally summed to enhance the visual signals. The parallel processing and temporal summation allow fast and low-light imaging in dim light. (B) High-speed and high-sensitivity microlens array camera (HS-MAC). A rolling shutter image sensor is utilized to simultaneously acquire multiple frames by channel division, and temporal summation is performed in parallel to realize high speed and sensitivity even in a low-light environment. In addition, the frame components of a single fragmented array image are stitched into a single blurred frame, which is subsequently deblurred by compressive image reconstruction. >
During this process, light is accumulated over overlapping time periods for each frame, increasing the signal-to-noise ratio. The researchers demonstrated that their bio-inspired camera could capture objects up to 40 times dimmer than those detectable by conventional high-speed cameras.
The team also introduced a "channel-splitting" technique to significantly enhance the camera's speed, achieving frame rates thousands of times faster than those supported by the image sensors used in packaging. Additionally, a "compressed image restoration" algorithm was employed to eliminate blur caused by frame integration and reconstruct sharp images.
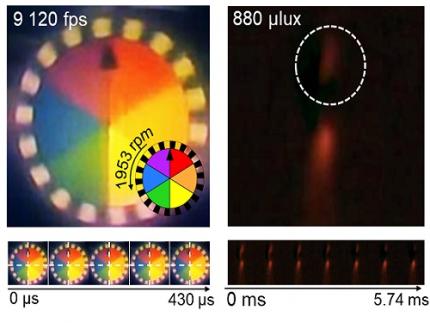
The resulting bio-inspired camera is less than one millimeter thick and extremely compact, capable of capturing 9,120 frames per second while providing clear images in low-light conditions.
< Figure 2. A high-speed, high-sensitivity biomimetic camera packaged in an image sensor. It is made small enough to fit on a finger, with a thickness of less than 1 mm. >
The research team plans to extend this technology to develop advanced image processing algorithms for 3D imaging and super-resolution imaging, aiming for applications in biomedical imaging, mobile devices, and various other camera technologies.
Hyun-Kyung Kim, a doctoral student in the Department of Bio and Brain Engineering at KAIST and the study's first author, stated, “We have experimentally validated that the insect-eye-inspired camera delivers outstanding performance in high-speed and low-light imaging despite its small size. This camera opens up possibilities for diverse applications in portable camera systems, security surveillance, and medical imaging.”
< Figure 3. Rotating plate and flame captured using the high-speed, high-sensitivity biomimetic camera. The rotating plate at 1,950 rpm was accurately captured at 9,120 fps. In addition, the pinch-off of the flame with a faint intensity of 880 µlux was accurately captured at 1,020 fps. >
This research was published in the international journal Science Advances in January 2025 (Paper Title: “Biologically-inspired microlens array camera for high-speed and high-sensitivity imaging”).
DOI: https://doi.org/10.1126/sciadv.ads3389
This study was supported by the Korea Research Institute for Defense Technology Planning and Advancement (KRIT) of the Defense Acquisition Program Administration (DAPA), the Ministry of Science and ICT, and the Ministry of Trade, Industry and Energy (MOTIE).
2025.01.16 View 7499
KAIST Develops Insect-Eye-Inspired Camera Capturing 9,120 Frames Per Second
< (From left) Bio and Brain Engineering PhD Student Jae-Myeong Kwon, Professor Ki-Hun Jeong, PhD Student Hyun-Kyung Kim, PhD Student Young-Gil Cha, and Professor Min H. Kim of the School of Computing >
The compound eyes of insects can detect fast-moving objects in parallel and, in low-light conditions, enhance sensitivity by integrating signals over time to determine motion. Inspired by these biological mechanisms, KAIST researchers have successfully developed a low-cost, high-speed camera that overcomes the limitations of frame rate and sensitivity faced by conventional high-speed cameras.
KAIST (represented by President Kwang Hyung Lee) announced on the 16th of January that a research team led by Professors Ki-Hun Jeong (Department of Bio and Brain Engineering) and Min H. Kim (School of Computing) has developed a novel bio-inspired camera capable of ultra-high-speed imaging with high sensitivity by mimicking the visual structure of insect eyes.
High-quality imaging under high-speed and low-light conditions is a critical challenge in many applications. While conventional high-speed cameras excel in capturing fast motion, their sensitivity decreases as frame rates increase because the time available to collect light is reduced.
To address this issue, the research team adopted an approach similar to insect vision, utilizing multiple optical channels and temporal summation. Unlike traditional monocular camera systems, the bio-inspired camera employs a compound-eye-like structure that allows for the parallel acquisition of frames from different time intervals.
< Figure 1. (A) Vision in a fast-eyed insect. Reflected light from swiftly moving objects sequentially stimulates the photoreceptors along the individual optical channels called ommatidia, of which the visual signals are separately and parallelly processed via the lamina and medulla. Each neural response is temporally summed to enhance the visual signals. The parallel processing and temporal summation allow fast and low-light imaging in dim light. (B) High-speed and high-sensitivity microlens array camera (HS-MAC). A rolling shutter image sensor is utilized to simultaneously acquire multiple frames by channel division, and temporal summation is performed in parallel to realize high speed and sensitivity even in a low-light environment. In addition, the frame components of a single fragmented array image are stitched into a single blurred frame, which is subsequently deblurred by compressive image reconstruction. >
During this process, light is accumulated over overlapping time periods for each frame, increasing the signal-to-noise ratio. The researchers demonstrated that their bio-inspired camera could capture objects up to 40 times dimmer than those detectable by conventional high-speed cameras.
The team also introduced a "channel-splitting" technique to significantly enhance the camera's speed, achieving frame rates thousands of times faster than those supported by the image sensors used in packaging. Additionally, a "compressed image restoration" algorithm was employed to eliminate blur caused by frame integration and reconstruct sharp images.
The resulting bio-inspired camera is less than one millimeter thick and extremely compact, capable of capturing 9,120 frames per second while providing clear images in low-light conditions.
< Figure 2. A high-speed, high-sensitivity biomimetic camera packaged in an image sensor. It is made small enough to fit on a finger, with a thickness of less than 1 mm. >
The research team plans to extend this technology to develop advanced image processing algorithms for 3D imaging and super-resolution imaging, aiming for applications in biomedical imaging, mobile devices, and various other camera technologies.
Hyun-Kyung Kim, a doctoral student in the Department of Bio and Brain Engineering at KAIST and the study's first author, stated, “We have experimentally validated that the insect-eye-inspired camera delivers outstanding performance in high-speed and low-light imaging despite its small size. This camera opens up possibilities for diverse applications in portable camera systems, security surveillance, and medical imaging.”
< Figure 3. Rotating plate and flame captured using the high-speed, high-sensitivity biomimetic camera. The rotating plate at 1,950 rpm was accurately captured at 9,120 fps. In addition, the pinch-off of the flame with a faint intensity of 880 µlux was accurately captured at 1,020 fps. >
This research was published in the international journal Science Advances in January 2025 (Paper Title: “Biologically-inspired microlens array camera for high-speed and high-sensitivity imaging”).
DOI: https://doi.org/10.1126/sciadv.ads3389
This study was supported by the Korea Research Institute for Defense Technology Planning and Advancement (KRIT) of the Defense Acquisition Program Administration (DAPA), the Ministry of Science and ICT, and the Ministry of Trade, Industry and Energy (MOTIE).
2025.01.16 View 7499 -
 KAIST Professor Uichin Lee Receives Distinguished Paper Award from ACM
< Photo. Professor Uichin Lee (left) receiving the award >
KAIST (President Kwang Hyung Lee) announced on the 25th of October that Professor Uichin Lee’s research team from the School of Computing received the Distinguished Paper Award at the International Joint Conference on Pervasive and Ubiquitous Computing and International Symposium on Wearable Computing (Ubicomp / ISWC) hosted by the Association for Computing Machinery (ACM) in Melbourne, Australia on October 8.
The ACM Ubiquitous Computing Conference is the most prestigious international conference where leading universities and global companies from around the world present the latest research results on ubiquitous computing and wearable technologies in the field of human-computer interaction (HCI).
The main conference program is composed of invited papers published in the Proceedings of the ACM (PACM) on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT), which covers the latest research in the field of ubiquitous and wearable computing.
The Distinguished Paper Award Selection Committee selected eight papers among 205 papers published in Vol. 7 of the ACM Proceedings (PACM IMWUT) that made outstanding and exemplary contributions to the research community. The committee consists of 16 prominent experts who are current and former members of the journal's editorial board which made the selection after a rigorous review of all papers for a period that stretched over a month.
< Figure 1. BeActive mobile app to promote physical activity to form active lifestyle habits >
The research that won the Distinguished Paper Award was conducted by Dr. Junyoung Park, a graduate of the KAIST Graduate School of Data Science, as the 1st author, and was titled “Understanding Disengagement in Just-in-Time Mobile Health Interventions”
Professor Uichin Lee’s research team explored user engagement of ‘Just-in-Time Mobile Health Interventions’ that actively provide interventions in opportune situations by utilizing sensor data collected from health management apps, based on the premise that these apps are aptly in use to ensure effectiveness.
< Figure 2. Traditional user-requested digital behavior change intervention (DBCI) delivery (Pull) vs. Automatic transmission (Push) for Just-in-Time (JIT) mobile DBCI using smartphone sensing technologies >
The research team conducted a systematic analysis of user disengagement or the decline in user engagement in digital behavior change interventions. They developed the BeActive system, an app that promotes physical activities designed to help forming active lifestyle habits, and systematically analyzed the effects of users’ self-control ability and boredom-proneness on compliance with behavioral interventions over time.
The results of an 8-week field trial revealed that even if just-in-time interventions are provided according to the user’s situation, it is impossible to avoid a decline in participation. However, for users with high self-control and low boredom tendency, the compliance with just-in-time interventions delivered through the app was significantly higher than that of users in other groups.
In particular, users with high boredom proneness easily got tired of the repeated push interventions, and their compliance with the app decreased more quickly than in other groups.
< Figure 3. Just-in-time Mobile Health Intervention: a demonstrative case of the BeActive system: When a user is identified to be sitting for more than 50 mins, an automatic push notification is sent to recommend a short active break to complete for reward points. >
Professor Uichin Lee explained, “As the first study on user engagement in digital therapeutics and wellness services utilizing mobile just-in-time health interventions, this research provides a foundation for exploring ways to empower user engagement.” He further added, “By leveraging large language models (LLMs) and comprehensive context-aware technologies, it will be possible to develop user-centered AI technologies that can significantly boost engagement."
< Figure 4. A conceptual illustration of user engagement in digital health apps. Engagement in digital health apps consists of (1) engagement in using digital health apps and (2) engagement in behavioral interventions provided by digital health apps, i.e., compliance with behavioral interventions. Repeated adherences to behavioral interventions recommended by digital health apps can help achieve the distal health goals. >
This study was conducted with the support of the 2021 Biomedical Technology Development Program and the 2022 Basic Research and Development Program of the National Research Foundation of Korea funded by the Ministry of Science and ICT.
< Figure 5. A conceptual illustration of user disengagement and engagement of digital behavior change intervention (DBCI) apps. In general, user engagement of digital health intervention apps consists of two components: engagement in digital health apps and engagement in behavioral interventions recommended by such apps (known as behavioral compliance or intervention adherence). The distinctive stages of user can be divided into adoption, abandonment, and attrition. >
< Figure 6. Trends of changes in frequency of app usage and adherence to behavioral intervention over 8 weeks, ● SC: Self-Control Ability (High-SC: user group with high self-control, Low-SC: user group with low self-control) ● BD: Boredom-Proneness (High-BD: user group with high boredom-proneness, Low-BD: user group with low boredom-proneness). The app usage frequencies were declined over time, but the adherence rates of those participants with High-SC and Low-BD were significantly higher than other groups. >
2024.10.25 View 8093
KAIST Professor Uichin Lee Receives Distinguished Paper Award from ACM
< Photo. Professor Uichin Lee (left) receiving the award >
KAIST (President Kwang Hyung Lee) announced on the 25th of October that Professor Uichin Lee’s research team from the School of Computing received the Distinguished Paper Award at the International Joint Conference on Pervasive and Ubiquitous Computing and International Symposium on Wearable Computing (Ubicomp / ISWC) hosted by the Association for Computing Machinery (ACM) in Melbourne, Australia on October 8.
The ACM Ubiquitous Computing Conference is the most prestigious international conference where leading universities and global companies from around the world present the latest research results on ubiquitous computing and wearable technologies in the field of human-computer interaction (HCI).
The main conference program is composed of invited papers published in the Proceedings of the ACM (PACM) on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT), which covers the latest research in the field of ubiquitous and wearable computing.
The Distinguished Paper Award Selection Committee selected eight papers among 205 papers published in Vol. 7 of the ACM Proceedings (PACM IMWUT) that made outstanding and exemplary contributions to the research community. The committee consists of 16 prominent experts who are current and former members of the journal's editorial board which made the selection after a rigorous review of all papers for a period that stretched over a month.
< Figure 1. BeActive mobile app to promote physical activity to form active lifestyle habits >
The research that won the Distinguished Paper Award was conducted by Dr. Junyoung Park, a graduate of the KAIST Graduate School of Data Science, as the 1st author, and was titled “Understanding Disengagement in Just-in-Time Mobile Health Interventions”
Professor Uichin Lee’s research team explored user engagement of ‘Just-in-Time Mobile Health Interventions’ that actively provide interventions in opportune situations by utilizing sensor data collected from health management apps, based on the premise that these apps are aptly in use to ensure effectiveness.
< Figure 2. Traditional user-requested digital behavior change intervention (DBCI) delivery (Pull) vs. Automatic transmission (Push) for Just-in-Time (JIT) mobile DBCI using smartphone sensing technologies >
The research team conducted a systematic analysis of user disengagement or the decline in user engagement in digital behavior change interventions. They developed the BeActive system, an app that promotes physical activities designed to help forming active lifestyle habits, and systematically analyzed the effects of users’ self-control ability and boredom-proneness on compliance with behavioral interventions over time.
The results of an 8-week field trial revealed that even if just-in-time interventions are provided according to the user’s situation, it is impossible to avoid a decline in participation. However, for users with high self-control and low boredom tendency, the compliance with just-in-time interventions delivered through the app was significantly higher than that of users in other groups.
In particular, users with high boredom proneness easily got tired of the repeated push interventions, and their compliance with the app decreased more quickly than in other groups.
< Figure 3. Just-in-time Mobile Health Intervention: a demonstrative case of the BeActive system: When a user is identified to be sitting for more than 50 mins, an automatic push notification is sent to recommend a short active break to complete for reward points. >
Professor Uichin Lee explained, “As the first study on user engagement in digital therapeutics and wellness services utilizing mobile just-in-time health interventions, this research provides a foundation for exploring ways to empower user engagement.” He further added, “By leveraging large language models (LLMs) and comprehensive context-aware technologies, it will be possible to develop user-centered AI technologies that can significantly boost engagement."
< Figure 4. A conceptual illustration of user engagement in digital health apps. Engagement in digital health apps consists of (1) engagement in using digital health apps and (2) engagement in behavioral interventions provided by digital health apps, i.e., compliance with behavioral interventions. Repeated adherences to behavioral interventions recommended by digital health apps can help achieve the distal health goals. >
This study was conducted with the support of the 2021 Biomedical Technology Development Program and the 2022 Basic Research and Development Program of the National Research Foundation of Korea funded by the Ministry of Science and ICT.
< Figure 5. A conceptual illustration of user disengagement and engagement of digital behavior change intervention (DBCI) apps. In general, user engagement of digital health intervention apps consists of two components: engagement in digital health apps and engagement in behavioral interventions recommended by such apps (known as behavioral compliance or intervention adherence). The distinctive stages of user can be divided into adoption, abandonment, and attrition. >
< Figure 6. Trends of changes in frequency of app usage and adherence to behavioral intervention over 8 weeks, ● SC: Self-Control Ability (High-SC: user group with high self-control, Low-SC: user group with low self-control) ● BD: Boredom-Proneness (High-BD: user group with high boredom-proneness, Low-BD: user group with low boredom-proneness). The app usage frequencies were declined over time, but the adherence rates of those participants with High-SC and Low-BD were significantly higher than other groups. >
2024.10.25 View 8093 -
 North Korea and Beyond: AI-Powered Satellite Analysis Reveals the Unseen Economic Landscape of Underdeveloped Nations
- A joint research team in computer science, economics, and geography has developed an artificial intelligence (AI) technology to measure grid-level economic development within six-square-kilometer regions.
- This AI technology is applicable in regions with limited statistical data (e.g., North Korea), supporting international efforts to propose policies for economic growth and poverty reduction in underdeveloped countries.
- The research team plans to make this technology freely available for use to contribute to the United Nations' Sustainable Development Goals (SDGs).
The United Nations reports that more than 700 million people are in extreme poverty, earning less than two dollars a day. However, an accurate assessment of poverty remains a global challenge. For example, 53 countries have not conducted agricultural surveys in the past 15 years, and 17 countries have not published a population census. To fill this data gap, new technologies are being explored to estimate poverty using alternative sources such as street views, aerial photos, and satellite images.
The paper published in Nature Communications demonstrates how artificial intelligence (AI) can help analyze economic conditions from daytime satellite imagery. This new technology can even apply to the least developed countries - such as North Korea - that do not have reliable statistical data for typical machine learning training.
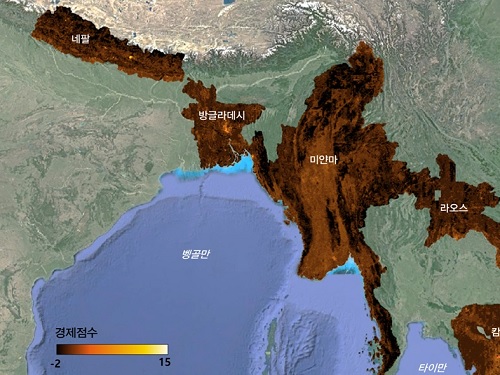
The researchers used Sentinel-2 satellite images from the European Space Agency (ESA) that are publicly available. They split these images into small six-square-kilometer grids. At this zoom level, visual information such as buildings, roads, and greenery can be used to quantify economic indicators. As a result, the team obtained the first ever fine-grained economic map of regions like North Korea. The same algorithm was applied to other underdeveloped countries in Asia: North Korea, Nepal, Laos, Myanmar, Bangladesh, and Cambodia (see Image 1).
The key feature of their research model is the "human-machine collaborative approach," which lets researchers combine human input with AI predictions for areas with scarce data. In this research, ten human experts compared satellite images and judged the economic conditions in the area, with the AI learning from this human data and giving economic scores to each image. The results showed that the Human-AI collaborative approach outperformed machine-only learning algorithms.
< Image 1. Nightlight satellite images of North Korea (Top-left: Background photo provided by NASA's Earth Observatory). South Korea appears brightly lit compared to North Korea, which is mostly dark except for Pyongyang. In contrast, the model developed by the research team uses daytime satellite imagery to predict more detailed economic predictions for North Korea (top-right) and five Asian countries (Bottom: Background photo from Google Earth). >
The research was led by an interdisciplinary team of computer scientists, economists, and a geographer from KAIST & IBS (Donghyun Ahn, Meeyoung Cha, Jihee Kim), Sogang University (Hyunjoo Yang), HKUST (Sangyoon Park), and NUS (Jeasurk Yang). Dr Charles Axelsson, Associate Editor at Nature Communications, handled this paper during the peer review process at the journal.
The research team found that the scores showed a strong correlation with traditional socio-economic metrics such as population density, employment, and number of businesses. This demonstrates the wide applicability and scalability of the approach, particularly in data-scarce countries. Furthermore, the model's strength lies in its ability to detect annual changes in economic conditions at a more detailed geospatial level without using any survey data (see Image 2).
< Image 2. Differences in satellite imagery and economic scores in North Korea between 2016 and 2019. Significant development was found in the Wonsan Kalma area (top), one of the tourist development zones, but no changes were observed in the Wiwon Industrial Development Zone (bottom). (Background photo: Sentinel-2 satellite imagery provided by the European Space Agency (ESA)). >
This model would be especially valuable for rapidly monitoring the progress of Sustainable Development Goals such as reducing poverty and promoting more equitable and sustainable growth on an international scale. The model can also be adapted to measure various social and environmental indicators. For example, it can be trained to identify regions with high vulnerability to climate change and disasters to provide timely guidance on disaster relief efforts.
As an example, the researchers explored how North Korea changed before and after the United Nations sanctions against the country. By applying the model to satellite images of North Korea both in 2016 and in 2019, the researchers discovered three key trends in the country's economic development between 2016 and 2019. First, economic growth in North Korea became more concentrated in Pyongyang and major cities, exacerbating the urban-rural divide. Second, satellite imagery revealed significant changes in areas designated for tourism and economic development, such as new building construction and other meaningful alterations. Third, traditional industrial and export development zones showed relatively minor changes.
Meeyoung Cha, a data scientist in the team explained, "This is an important interdisciplinary effort to address global challenges like poverty. We plan to apply our AI algorithm to other international issues, such as monitoring carbon emissions, disaster damage detection, and the impact of climate change."
An economist on the research team, Jihee Kim, commented that this approach would enable detailed examinations of economic conditions in the developing world at a low cost, reducing data disparities between developed and developing nations. She further emphasized that this is most essential because many public policies require economic measurements to achieve their goals, whether they are for growth, equality, or sustainability.
The research team has made the source code publicly available via GitHub and plans to continue improving the technology, applying it to new satellite images updated annually. The results of this study, with Ph.D. candidate Donghyun Ahn at KAIST and Ph.D. candidate Jeasurk Yang at NUS as joint first authors, were published in Nature Communications under the title "A human-machine collaborative approach measures economic development using satellite imagery."
< Photos of the main authors. 1. Donghyun Ahn, PhD candidate at KAIST School of Computing 2. Jeasurk Yang, PhD candidate at the Department of Geography of National University of Singapore 3. Meeyoung Cha, Professor of KAIST School of Computing and CI at IBS 4. Jihee Kim, Professor of KAIST School of Business and Technology Management 5. Sangyoon Park, Professor of the Division of Social Science at Hong Kong University of Science and Technology 6. Hyunjoo Yang, Professor of the Department of Economics at Sogang University >
2023.12.07 View 9144
North Korea and Beyond: AI-Powered Satellite Analysis Reveals the Unseen Economic Landscape of Underdeveloped Nations
- A joint research team in computer science, economics, and geography has developed an artificial intelligence (AI) technology to measure grid-level economic development within six-square-kilometer regions.
- This AI technology is applicable in regions with limited statistical data (e.g., North Korea), supporting international efforts to propose policies for economic growth and poverty reduction in underdeveloped countries.
- The research team plans to make this technology freely available for use to contribute to the United Nations' Sustainable Development Goals (SDGs).
The United Nations reports that more than 700 million people are in extreme poverty, earning less than two dollars a day. However, an accurate assessment of poverty remains a global challenge. For example, 53 countries have not conducted agricultural surveys in the past 15 years, and 17 countries have not published a population census. To fill this data gap, new technologies are being explored to estimate poverty using alternative sources such as street views, aerial photos, and satellite images.
The paper published in Nature Communications demonstrates how artificial intelligence (AI) can help analyze economic conditions from daytime satellite imagery. This new technology can even apply to the least developed countries - such as North Korea - that do not have reliable statistical data for typical machine learning training.
The researchers used Sentinel-2 satellite images from the European Space Agency (ESA) that are publicly available. They split these images into small six-square-kilometer grids. At this zoom level, visual information such as buildings, roads, and greenery can be used to quantify economic indicators. As a result, the team obtained the first ever fine-grained economic map of regions like North Korea. The same algorithm was applied to other underdeveloped countries in Asia: North Korea, Nepal, Laos, Myanmar, Bangladesh, and Cambodia (see Image 1).
The key feature of their research model is the "human-machine collaborative approach," which lets researchers combine human input with AI predictions for areas with scarce data. In this research, ten human experts compared satellite images and judged the economic conditions in the area, with the AI learning from this human data and giving economic scores to each image. The results showed that the Human-AI collaborative approach outperformed machine-only learning algorithms.
< Image 1. Nightlight satellite images of North Korea (Top-left: Background photo provided by NASA's Earth Observatory). South Korea appears brightly lit compared to North Korea, which is mostly dark except for Pyongyang. In contrast, the model developed by the research team uses daytime satellite imagery to predict more detailed economic predictions for North Korea (top-right) and five Asian countries (Bottom: Background photo from Google Earth). >
The research was led by an interdisciplinary team of computer scientists, economists, and a geographer from KAIST & IBS (Donghyun Ahn, Meeyoung Cha, Jihee Kim), Sogang University (Hyunjoo Yang), HKUST (Sangyoon Park), and NUS (Jeasurk Yang). Dr Charles Axelsson, Associate Editor at Nature Communications, handled this paper during the peer review process at the journal.
The research team found that the scores showed a strong correlation with traditional socio-economic metrics such as population density, employment, and number of businesses. This demonstrates the wide applicability and scalability of the approach, particularly in data-scarce countries. Furthermore, the model's strength lies in its ability to detect annual changes in economic conditions at a more detailed geospatial level without using any survey data (see Image 2).
< Image 2. Differences in satellite imagery and economic scores in North Korea between 2016 and 2019. Significant development was found in the Wonsan Kalma area (top), one of the tourist development zones, but no changes were observed in the Wiwon Industrial Development Zone (bottom). (Background photo: Sentinel-2 satellite imagery provided by the European Space Agency (ESA)). >
This model would be especially valuable for rapidly monitoring the progress of Sustainable Development Goals such as reducing poverty and promoting more equitable and sustainable growth on an international scale. The model can also be adapted to measure various social and environmental indicators. For example, it can be trained to identify regions with high vulnerability to climate change and disasters to provide timely guidance on disaster relief efforts.
As an example, the researchers explored how North Korea changed before and after the United Nations sanctions against the country. By applying the model to satellite images of North Korea both in 2016 and in 2019, the researchers discovered three key trends in the country's economic development between 2016 and 2019. First, economic growth in North Korea became more concentrated in Pyongyang and major cities, exacerbating the urban-rural divide. Second, satellite imagery revealed significant changes in areas designated for tourism and economic development, such as new building construction and other meaningful alterations. Third, traditional industrial and export development zones showed relatively minor changes.
Meeyoung Cha, a data scientist in the team explained, "This is an important interdisciplinary effort to address global challenges like poverty. We plan to apply our AI algorithm to other international issues, such as monitoring carbon emissions, disaster damage detection, and the impact of climate change."
An economist on the research team, Jihee Kim, commented that this approach would enable detailed examinations of economic conditions in the developing world at a low cost, reducing data disparities between developed and developing nations. She further emphasized that this is most essential because many public policies require economic measurements to achieve their goals, whether they are for growth, equality, or sustainability.
The research team has made the source code publicly available via GitHub and plans to continue improving the technology, applying it to new satellite images updated annually. The results of this study, with Ph.D. candidate Donghyun Ahn at KAIST and Ph.D. candidate Jeasurk Yang at NUS as joint first authors, were published in Nature Communications under the title "A human-machine collaborative approach measures economic development using satellite imagery."
< Photos of the main authors. 1. Donghyun Ahn, PhD candidate at KAIST School of Computing 2. Jeasurk Yang, PhD candidate at the Department of Geography of National University of Singapore 3. Meeyoung Cha, Professor of KAIST School of Computing and CI at IBS 4. Jihee Kim, Professor of KAIST School of Business and Technology Management 5. Sangyoon Park, Professor of the Division of Social Science at Hong Kong University of Science and Technology 6. Hyunjoo Yang, Professor of the Department of Economics at Sogang University >
2023.12.07 View 9144 -
 KAIST researchers find sleep delays more prevalent in countries of particular culture than others
Sleep has a huge impact on health, well-being and productivity, but how long and how well people sleep these days has not been accurately reported. Previous research on how much and how well we sleep has mostly relied on self-reports or was confined within the data from the unnatural environments of the sleep laboratories.
So, the questions remained: Is the amount and quality of sleep purely a personal choice? Could they be independent from social factors such as culture and geography?
< From left to right, Sungkyu Park of Kangwon National University, South Korea; Assem Zhunis of KAIST and IBS, South Korea; Marios Constantinides of Nokia Bell Labs, UK; Luca Maria Aiello of the IT University of Copenhagen, Denmark; Daniele Quercia of Nokia Bell Labs and King's College London, UK; and Meeyoung Cha of IBS and KAIST, South Korea >
A new study led by researchers at Korea Advanced Institute of Science and Technology (KAIST) and Nokia Bell Labs in the United Kingdom investigated the cultural and individual factors that influence sleep. In contrast to previous studies that relied on surveys or controlled experiments at labs, the team used commercially available smartwatches for extensive data collection, analyzing 52 million logs collected over a four-year period from 30,082 individuals in 11 countries. These people wore Nokia smartwatches, which allowed the team to investigate country-specific sleep patterns based on the digital logs from the devices.
< Figure comparing survey and smartwatch logs on average sleep-time, wake-time, and sleep durations. Digital logs consistently recorded delayed hours of wake- and sleep-time, resulting in shorter sleep durations. >
Digital logs collected from the smartwatches revealed discrepancies in wake-up times and sleep-times, sometimes by tens of minutes to an hour, from the data previously collected from self-report assessments. The average sleep-time overall was calculated to be around midnight, and the average wake-up time was 7:42 AM. The team discovered, however, that individuals' sleep is heavily linked to their geographical location and cultural factors. While wake-up times were similar, sleep-time varied by country. Individuals in higher GDP countries had more records of delayed bedtime. Those in collectivist culture, compared to individualist culture, also showed more records of delayed bedtime. Among the studied countries, Japan had the shortest total sleep duration, averaging a duration of under 7 hours, while Finland had the longest, averaging 8 hours.
Researchers calculated essential sleep metrics used in clinical studies, such as sleep efficiency, sleep duration, and overslept hours on weekends, to analyze the extensive sleep patterns. Using Principal Component Analysis (PCA), they further condensed these metrics into two major sleep dimensions representing sleep quality and quantity. A cross-country comparison revealed that societal factors account for 55% of the variation in sleep quality and 63% of the variation in sleep quantity.
Countries with a higher individualism index (IDV), which placed greater emphasis on individual achievements and relationships, had significantly longer sleep durations, which could be attributed to such societies having a norm of going to bed early. Spain and Japan, on the other hand, had the bedtime scheduled at the latest hours despite having the highest collectivism scores (low IDV). The study also discovered a moderate relationship between a higher uncertainty avoidance index (UAI), which measures implementation of general laws and regulation in daily lives of regular citizens, and better sleep quality.
Researchers also investigated how physical activity can affect sleep quantity and quality to see if individuals can counterbalance cultural influences through personal interventions. They discovered that increasing daily activity can improve sleep quality in terms of shortened time needed in falling asleep and waking up. Individuals who exercise more, however, did not sleep longer. The effect of exercise differed by country, with more pronounced effects observed in some countries, such as the United States and Finland. Interestingly, in Japan, no obvious effect of exercise could be observed. These findings suggest that the relationship between daily activity and sleep may differ by country and that different exercise regimens may be more effective in different cultures.
This research published on the Scientific Reports by the international journal, Nature, sheds light on the influence of social factors on sleep. (Paper Title "Social dimensions impact individual sleep quantity and quality" Article number: 9681)
One of the co-authors, Daniele Quercia, commented: “Excessive work schedules, long working hours, and late bedtime in high-income countries and social engagement due to high collectivism may cause bedtimes to be delayed.”
Commenting on the research, the first author Shaun Sungkyu Park said, "While it is intriguing to see that a society can play a role in determining the quantity and quality of an individual's sleep with large-scale data, the significance of this study is that it quantitatively shows that even within the same culture (country), individual efforts such as daily exercise can have a positive impact on sleep quantity and quality."
"Sleep not only has a great impact on one’s well-being but it is also known to be associated with health issues such as obesity and dementia," said the lead author, Meeyoung Cha. "In order to ensure adequate sleep and improve sleep quality in an aging society, not only individual efforts but also a social support must be provided to work together," she said. The research team will contribute to the development of the high-tech sleep industry by making a code that easily calculates the sleep indicators developed in this study available free of charge, as well as providing the benchmark data for various types of sleep research to follow.
2023.07.07 View 8737
KAIST researchers find sleep delays more prevalent in countries of particular culture than others
Sleep has a huge impact on health, well-being and productivity, but how long and how well people sleep these days has not been accurately reported. Previous research on how much and how well we sleep has mostly relied on self-reports or was confined within the data from the unnatural environments of the sleep laboratories.
So, the questions remained: Is the amount and quality of sleep purely a personal choice? Could they be independent from social factors such as culture and geography?
< From left to right, Sungkyu Park of Kangwon National University, South Korea; Assem Zhunis of KAIST and IBS, South Korea; Marios Constantinides of Nokia Bell Labs, UK; Luca Maria Aiello of the IT University of Copenhagen, Denmark; Daniele Quercia of Nokia Bell Labs and King's College London, UK; and Meeyoung Cha of IBS and KAIST, South Korea >
A new study led by researchers at Korea Advanced Institute of Science and Technology (KAIST) and Nokia Bell Labs in the United Kingdom investigated the cultural and individual factors that influence sleep. In contrast to previous studies that relied on surveys or controlled experiments at labs, the team used commercially available smartwatches for extensive data collection, analyzing 52 million logs collected over a four-year period from 30,082 individuals in 11 countries. These people wore Nokia smartwatches, which allowed the team to investigate country-specific sleep patterns based on the digital logs from the devices.
< Figure comparing survey and smartwatch logs on average sleep-time, wake-time, and sleep durations. Digital logs consistently recorded delayed hours of wake- and sleep-time, resulting in shorter sleep durations. >
Digital logs collected from the smartwatches revealed discrepancies in wake-up times and sleep-times, sometimes by tens of minutes to an hour, from the data previously collected from self-report assessments. The average sleep-time overall was calculated to be around midnight, and the average wake-up time was 7:42 AM. The team discovered, however, that individuals' sleep is heavily linked to their geographical location and cultural factors. While wake-up times were similar, sleep-time varied by country. Individuals in higher GDP countries had more records of delayed bedtime. Those in collectivist culture, compared to individualist culture, also showed more records of delayed bedtime. Among the studied countries, Japan had the shortest total sleep duration, averaging a duration of under 7 hours, while Finland had the longest, averaging 8 hours.
Researchers calculated essential sleep metrics used in clinical studies, such as sleep efficiency, sleep duration, and overslept hours on weekends, to analyze the extensive sleep patterns. Using Principal Component Analysis (PCA), they further condensed these metrics into two major sleep dimensions representing sleep quality and quantity. A cross-country comparison revealed that societal factors account for 55% of the variation in sleep quality and 63% of the variation in sleep quantity.
Countries with a higher individualism index (IDV), which placed greater emphasis on individual achievements and relationships, had significantly longer sleep durations, which could be attributed to such societies having a norm of going to bed early. Spain and Japan, on the other hand, had the bedtime scheduled at the latest hours despite having the highest collectivism scores (low IDV). The study also discovered a moderate relationship between a higher uncertainty avoidance index (UAI), which measures implementation of general laws and regulation in daily lives of regular citizens, and better sleep quality.
Researchers also investigated how physical activity can affect sleep quantity and quality to see if individuals can counterbalance cultural influences through personal interventions. They discovered that increasing daily activity can improve sleep quality in terms of shortened time needed in falling asleep and waking up. Individuals who exercise more, however, did not sleep longer. The effect of exercise differed by country, with more pronounced effects observed in some countries, such as the United States and Finland. Interestingly, in Japan, no obvious effect of exercise could be observed. These findings suggest that the relationship between daily activity and sleep may differ by country and that different exercise regimens may be more effective in different cultures.
This research published on the Scientific Reports by the international journal, Nature, sheds light on the influence of social factors on sleep. (Paper Title "Social dimensions impact individual sleep quantity and quality" Article number: 9681)
One of the co-authors, Daniele Quercia, commented: “Excessive work schedules, long working hours, and late bedtime in high-income countries and social engagement due to high collectivism may cause bedtimes to be delayed.”
Commenting on the research, the first author Shaun Sungkyu Park said, "While it is intriguing to see that a society can play a role in determining the quantity and quality of an individual's sleep with large-scale data, the significance of this study is that it quantitatively shows that even within the same culture (country), individual efforts such as daily exercise can have a positive impact on sleep quantity and quality."
"Sleep not only has a great impact on one’s well-being but it is also known to be associated with health issues such as obesity and dementia," said the lead author, Meeyoung Cha. "In order to ensure adequate sleep and improve sleep quality in an aging society, not only individual efforts but also a social support must be provided to work together," she said. The research team will contribute to the development of the high-tech sleep industry by making a code that easily calculates the sleep indicators developed in this study available free of charge, as well as providing the benchmark data for various types of sleep research to follow.
2023.07.07 View 8737 -
 Shaping the AI Semiconductor Ecosystem
- As the marriage of AI and semiconductor being highlighted as the strategic technology of national enthusiasm, KAIST's achievements in the related fields accumulated through top-class education and research capabilities that surpass that of peer universities around the world are standing far apart from the rest of the pack.
As Artificial Intelligence Semiconductor, or a system of semiconductors designed for specifically for highly complicated computation need for AI to conduct its learning and deducing calculations, (hereafter AI semiconductors) stand out as a national strategic technology, the related achievements of KAIST, headed by President Kwang Hyung Lee, are also attracting attention. The Ministry of Science, ICT and Future Planning (MSIT) of Korea initiated a program to support the advancement of AI semiconductor last year with the goal of occupying 20% of the global AI semiconductor market by 2030. This year, through industry-university-research discussions, the Ministry expanded to the program with the addition of 1.2 trillion won of investment over five years through 'Support Plan for AI Semiconductor Industry Promotion'. Accordingly, major universities began putting together programs devised to train students to develop expertise in AI semiconductors.
KAIST has accumulated top-notch educational and research capabilities in the two core fields of AI semiconductor - Semiconductor and Artificial Intelligence. Notably, in the field of semiconductors, the International Solid-State Circuit Conference (ISSCC) is the world's most prestigious conference about designing of semiconductor integrated circuit. Established in 1954, with more than 60% of the participants coming from companies including Samsung, Qualcomm, TSMC, and Intel, the conference naturally focuses on practical value of the studies from the industrial point-of-view, earning the nickname the ‘Semiconductor Design Olympics’. At such conference of legacy and influence, KAIST kept its presence widely visible over other participating universities, leading in terms of the number of accepted papers over world-class schools such as Massachusetts Institute of Technology (MIT) and Stanford for the past 17 years.
Number of papers published at the InternationalSolid-State Circuit Conference (ISSCC) in 2022 sorted by nations and by institutions
Number of papers by universities presented at the International Solid-State Circuit Conference (ISCCC) in 2006~2022
In terms of the number of papers accepted at the ISSCC, KAIST ranked among top two universities each year since 2006. Looking at the average number of accepted papers over the past 17 years, KAIST stands out as an unparalleled leader. The average number of KAIST papers adopted during the period of 17 years from 2006 through 2022, was 8.4, which is almost double of that of competitors like MIT (4.6) and UCLA (3.6). In Korea, it maintains the second place overall after Samsung, the undisputed number one in the semiconductor design field. Also, this year, KAIST was ranked first among universities participating at the Symposium on VLSI Technology and Circuits, an academic conference in the field of integrated circuits that rivals the ISSCC.
Number of papers adopted by the Symposium on VLSI Technology and Circuits in 2022 submitted from the universities
With KAIST researchers working and presenting new technologies at the frontiers of all key areas of the semiconductor industry, the quality of KAIST research is also maintained at the highest level. Professor Myoungsoo Jung's research team in the School of Electrical Engineering is actively working to develop heterogeneous computing environment with high energy efficiency in response to the industry's demand for high performance at low power. In the field of materials, a research team led by Professor Byong-Guk Park of the Department of Materials Science and Engineering developed the Spin Orbit Torque (SOT)-based Magnetic RAM (MRAM) memory that operates at least 10 times faster than conventional memories to suggest a way to overcome the limitations of the existing 'von Neumann structure'.
As such, while providing solutions to major challenges in the current semiconductor industry, the development of new technologies necessary to preoccupy new fields in the semiconductor industry are also very actively pursued. In the field of Quantum Computing, which is attracting attention as next-generation computing technology needed in order to take the lead in the fields of cryptography and nonlinear computation, Professor Sanghyeon Kim's research team in the School of Electrical Engineering presented the world's first 3D integrated quantum computing system at 2021 VLSI Symposium. In Neuromorphic Computing, which is expected to bring remarkable advancements in the field of artificial intelligence by utilizing the principles of the neurology, the research team of Professor Shinhyun Choi of School of Electrical Engineering is developing a next-generation memristor that mimics neurons.
The number of papers by the International Conference on Machine Learning (ICML) and the Conference on Neural Information Processing Systems (NeurIPS), two of the world’s most prestigious academic societies in the field of artificial intelligence (KAIST 6th in the world, 1st in Asia, in 2020)
The field of artificial intelligence has also grown rapidly. Based on the number of papers from the International Conference on Machine Learning (ICML) and the Conference on Neural Information Processing Systems (NeurIPS), two of the world's most prestigious conferences in the field of artificial intelligence, KAIST ranked 6th in the world in 2020 and 1st in Asia. Since 2012, KAIST's ranking steadily inclined from 37th to 6th, climbing 31 steps over the period of eight years. In 2021, 129 papers, or about 40%, of Korean papers published at 11 top artificial intelligence conferences were presented by KAIST. Thanks to KAIST's efforts, in 2021, Korea ranked sixth after the United States, China, United Kingdom, Canada, and Germany in terms of the number of papers published by global AI academic societies.
Number of papers from Korea (and by KAIST) published at 11 top conferences in the field of artificial intelligence in 2021
In terms of content, KAIST's AI research is also at the forefront. Professor Hoi-Jun Yoo's research team in the School of Electrical Engineering compensated for the shortcomings of the “edge networks” by implementing artificial intelligence real-time learning networks on mobile devices. In order to materialize artificial intelligence, data accumulation and a huge amount of computation is required. For this, a high-performance server takes care of massive computation, and for the user terminals, the “edge network” that collects data and performs simple computations are used. Professor Yoo's research greatly increased AI’s processing speed and performance by allotting the learning task to the user terminal as well.
In June, a research team led by Professor Min-Soo Kim of the School of Computing presented a solution that is essential for processing super-scale artificial intelligence models. The super-scale machine learning system developed by the research team is expected to achieve speeds up to 8.8 times faster than Google's Tensorflow or IBM's System DS, which are mainly used in the industry.
KAIST is also making remarkable achievements in the field of AI semiconductors. In 2020, Professor Minsoo Rhu's research team in the School of Electrical Engineering succeeded in developing the world's first AI semiconductor optimized for AI recommendation systems. Due to the nature of the AI recommendation system having to handle vast amounts of contents and user information, it quickly meets its limitation because of the information bottleneck when the process is operated through a general-purpose artificial intelligence system. Professor Minsoo Rhu's team developed a semiconductor that can achieve a speed that is 21 times faster than existing systems using the 'Processing-In-Memory (PIM)' technology. PIM is a technology that improves efficiency by performing the calculations in 'RAM', or random-access memory, which is usually only used to store data temporarily just before they are processed. When PIM technology is put out on the market, it is expected that fortify competitiveness of Korean companies in the AI semiconductor market drastically, as they already hold great strength in the memory area.
KAIST does not plan to be complacent with its achievements, but is making various plans to further the distance from the competitors catching on in the fields of artificial intelligence, semiconductors, and AI semiconductors. Following the establishment of the first artificial intelligence research center in Korea in 1990, the Kim Jaechul AI Graduate School was opened in 2019 to sustain the supply chain of the experts in the field. In 2020, Artificial Intelligence Semiconductor System Research Center was launched to conduct convergent research on AI and semiconductors, which was followed by the establishment of the AI Institutes to promote “AI+X” research efforts.
Based on the internal capabilities accumulated through these efforts, KAIST is also making efforts to train human resources needed in these areas. KAIST established joint research centers with companies such as Naver, while collaborating with local governments such as Hwaseong City to simultaneously nurture professional manpower. Back in 2021, KAIST signed an agreement to establish the Semiconductor System Engineering Department with Samsung Electronics and are preparing a new semiconductor specialist training program. The newly established Department of Semiconductor System Engineering will select around 100 new students every year from 2023 and provide special scholarships to all students so that they can develop their professional skills. In addition, through close cooperation with the industry, they will receive special support which includes field trips and internships at Samsung Electronics, and joint workshops and on-site training.
KAIST has made a significant contribution to the growth of the Korean semiconductor industry ecosystem, producing 25% of doctoral workers in the domestic semiconductor field and 20% of CEOs of mid-sized and venture companies with doctoral degrees. With the dawn coming up on the AI semiconductor ecosystem, whether KAIST will reprise the pivotal role seems to be the crucial point of business.
2022.08.05 View 13512
Shaping the AI Semiconductor Ecosystem
- As the marriage of AI and semiconductor being highlighted as the strategic technology of national enthusiasm, KAIST's achievements in the related fields accumulated through top-class education and research capabilities that surpass that of peer universities around the world are standing far apart from the rest of the pack.
As Artificial Intelligence Semiconductor, or a system of semiconductors designed for specifically for highly complicated computation need for AI to conduct its learning and deducing calculations, (hereafter AI semiconductors) stand out as a national strategic technology, the related achievements of KAIST, headed by President Kwang Hyung Lee, are also attracting attention. The Ministry of Science, ICT and Future Planning (MSIT) of Korea initiated a program to support the advancement of AI semiconductor last year with the goal of occupying 20% of the global AI semiconductor market by 2030. This year, through industry-university-research discussions, the Ministry expanded to the program with the addition of 1.2 trillion won of investment over five years through 'Support Plan for AI Semiconductor Industry Promotion'. Accordingly, major universities began putting together programs devised to train students to develop expertise in AI semiconductors.
KAIST has accumulated top-notch educational and research capabilities in the two core fields of AI semiconductor - Semiconductor and Artificial Intelligence. Notably, in the field of semiconductors, the International Solid-State Circuit Conference (ISSCC) is the world's most prestigious conference about designing of semiconductor integrated circuit. Established in 1954, with more than 60% of the participants coming from companies including Samsung, Qualcomm, TSMC, and Intel, the conference naturally focuses on practical value of the studies from the industrial point-of-view, earning the nickname the ‘Semiconductor Design Olympics’. At such conference of legacy and influence, KAIST kept its presence widely visible over other participating universities, leading in terms of the number of accepted papers over world-class schools such as Massachusetts Institute of Technology (MIT) and Stanford for the past 17 years.
Number of papers published at the InternationalSolid-State Circuit Conference (ISSCC) in 2022 sorted by nations and by institutions
Number of papers by universities presented at the International Solid-State Circuit Conference (ISCCC) in 2006~2022
In terms of the number of papers accepted at the ISSCC, KAIST ranked among top two universities each year since 2006. Looking at the average number of accepted papers over the past 17 years, KAIST stands out as an unparalleled leader. The average number of KAIST papers adopted during the period of 17 years from 2006 through 2022, was 8.4, which is almost double of that of competitors like MIT (4.6) and UCLA (3.6). In Korea, it maintains the second place overall after Samsung, the undisputed number one in the semiconductor design field. Also, this year, KAIST was ranked first among universities participating at the Symposium on VLSI Technology and Circuits, an academic conference in the field of integrated circuits that rivals the ISSCC.
Number of papers adopted by the Symposium on VLSI Technology and Circuits in 2022 submitted from the universities
With KAIST researchers working and presenting new technologies at the frontiers of all key areas of the semiconductor industry, the quality of KAIST research is also maintained at the highest level. Professor Myoungsoo Jung's research team in the School of Electrical Engineering is actively working to develop heterogeneous computing environment with high energy efficiency in response to the industry's demand for high performance at low power. In the field of materials, a research team led by Professor Byong-Guk Park of the Department of Materials Science and Engineering developed the Spin Orbit Torque (SOT)-based Magnetic RAM (MRAM) memory that operates at least 10 times faster than conventional memories to suggest a way to overcome the limitations of the existing 'von Neumann structure'.
As such, while providing solutions to major challenges in the current semiconductor industry, the development of new technologies necessary to preoccupy new fields in the semiconductor industry are also very actively pursued. In the field of Quantum Computing, which is attracting attention as next-generation computing technology needed in order to take the lead in the fields of cryptography and nonlinear computation, Professor Sanghyeon Kim's research team in the School of Electrical Engineering presented the world's first 3D integrated quantum computing system at 2021 VLSI Symposium. In Neuromorphic Computing, which is expected to bring remarkable advancements in the field of artificial intelligence by utilizing the principles of the neurology, the research team of Professor Shinhyun Choi of School of Electrical Engineering is developing a next-generation memristor that mimics neurons.
The number of papers by the International Conference on Machine Learning (ICML) and the Conference on Neural Information Processing Systems (NeurIPS), two of the world’s most prestigious academic societies in the field of artificial intelligence (KAIST 6th in the world, 1st in Asia, in 2020)
The field of artificial intelligence has also grown rapidly. Based on the number of papers from the International Conference on Machine Learning (ICML) and the Conference on Neural Information Processing Systems (NeurIPS), two of the world's most prestigious conferences in the field of artificial intelligence, KAIST ranked 6th in the world in 2020 and 1st in Asia. Since 2012, KAIST's ranking steadily inclined from 37th to 6th, climbing 31 steps over the period of eight years. In 2021, 129 papers, or about 40%, of Korean papers published at 11 top artificial intelligence conferences were presented by KAIST. Thanks to KAIST's efforts, in 2021, Korea ranked sixth after the United States, China, United Kingdom, Canada, and Germany in terms of the number of papers published by global AI academic societies.
Number of papers from Korea (and by KAIST) published at 11 top conferences in the field of artificial intelligence in 2021
In terms of content, KAIST's AI research is also at the forefront. Professor Hoi-Jun Yoo's research team in the School of Electrical Engineering compensated for the shortcomings of the “edge networks” by implementing artificial intelligence real-time learning networks on mobile devices. In order to materialize artificial intelligence, data accumulation and a huge amount of computation is required. For this, a high-performance server takes care of massive computation, and for the user terminals, the “edge network” that collects data and performs simple computations are used. Professor Yoo's research greatly increased AI’s processing speed and performance by allotting the learning task to the user terminal as well.
In June, a research team led by Professor Min-Soo Kim of the School of Computing presented a solution that is essential for processing super-scale artificial intelligence models. The super-scale machine learning system developed by the research team is expected to achieve speeds up to 8.8 times faster than Google's Tensorflow or IBM's System DS, which are mainly used in the industry.
KAIST is also making remarkable achievements in the field of AI semiconductors. In 2020, Professor Minsoo Rhu's research team in the School of Electrical Engineering succeeded in developing the world's first AI semiconductor optimized for AI recommendation systems. Due to the nature of the AI recommendation system having to handle vast amounts of contents and user information, it quickly meets its limitation because of the information bottleneck when the process is operated through a general-purpose artificial intelligence system. Professor Minsoo Rhu's team developed a semiconductor that can achieve a speed that is 21 times faster than existing systems using the 'Processing-In-Memory (PIM)' technology. PIM is a technology that improves efficiency by performing the calculations in 'RAM', or random-access memory, which is usually only used to store data temporarily just before they are processed. When PIM technology is put out on the market, it is expected that fortify competitiveness of Korean companies in the AI semiconductor market drastically, as they already hold great strength in the memory area.
KAIST does not plan to be complacent with its achievements, but is making various plans to further the distance from the competitors catching on in the fields of artificial intelligence, semiconductors, and AI semiconductors. Following the establishment of the first artificial intelligence research center in Korea in 1990, the Kim Jaechul AI Graduate School was opened in 2019 to sustain the supply chain of the experts in the field. In 2020, Artificial Intelligence Semiconductor System Research Center was launched to conduct convergent research on AI and semiconductors, which was followed by the establishment of the AI Institutes to promote “AI+X” research efforts.
Based on the internal capabilities accumulated through these efforts, KAIST is also making efforts to train human resources needed in these areas. KAIST established joint research centers with companies such as Naver, while collaborating with local governments such as Hwaseong City to simultaneously nurture professional manpower. Back in 2021, KAIST signed an agreement to establish the Semiconductor System Engineering Department with Samsung Electronics and are preparing a new semiconductor specialist training program. The newly established Department of Semiconductor System Engineering will select around 100 new students every year from 2023 and provide special scholarships to all students so that they can develop their professional skills. In addition, through close cooperation with the industry, they will receive special support which includes field trips and internships at Samsung Electronics, and joint workshops and on-site training.
KAIST has made a significant contribution to the growth of the Korean semiconductor industry ecosystem, producing 25% of doctoral workers in the domestic semiconductor field and 20% of CEOs of mid-sized and venture companies with doctoral degrees. With the dawn coming up on the AI semiconductor ecosystem, whether KAIST will reprise the pivotal role seems to be the crucial point of business.
2022.08.05 View 13512 -
 An AI-based, Indoor/Outdoor-Integrated (IOI) GPS System to Bring Seismic Waves in the Terrains of Positioning Technology
KAIST breaks new grounds in positioning technology with an AI-integrated GPS board that works both indoors and out
KAIST (President Kwang Hyung Lee) announced on the 8th that Professor Dong-Soo Han's research team (Intelligent Service Integration Lab) from the School of Computing has developed a GPS system that works both indoors and outdoors with quality precision regardless of the environment.
This Indoor/Outdoor-Integrated GPS System, or IOI GPS System, for short, uses the GPS signals outdoors and estimates locations indoors using signals from multiple sources like an inertial sensor, pressure sensors, geomagnetic sensors, and light sensors. To this end, the research team developed techniques to detect environmental changes such as entering a building, and methods to detect entrances, ground floors, stairs, elevators and levels of buildings by utilizing artificial intelligence techniques. Various landmark detecting techniques were also incorporated with pedestrian dead reckoning (PDR), a navigation tool for pedestrians, to devise the so-called “Sensor-Fusion Positioning Algorithm”.
To date, it was common to estimate locations based on wireless LAN signals or base station signals in a space where the GPS signal could not reach. However, the IOI GPS enables positioning even in buildings without signals nor indoor maps.
The algorithm developed by the research team can provide accurate floor information within a building where even big tech companies like Google and Apple's positioning services do not provide. Unlike other positioning methods that rely on visual data, geomagnetic positioning techniques, or wireless LAN, this system also has the advantage of not requiring any prior preparation. In other words, the foundation to enable the usage of a universal GPS system that works both indoors and outdoors anywhere in the world is now ready.
The research team also produced a circuit board for the purpose of operating the IOI GPS System, mounted with chips to receive and process GPS, Wi-Fi, and Bluetooth signals, along with an inertial sensor, a barometer, a magnetometer, and a light sensor. The sensor-fusion positioning algorithm the lab has developed is also incorporated in the board.
When the accuracy of the IOI GPS board was tested in the N1 building of KAIST’s main campus in Daejeon, it achieved an accuracy of about 95% in floor estimation and an accuracy of about 3 to 6 meters in distance estimation. As for the indoor/outdoor transition, the navigational mode change was completed in about 0.3 seconds. When it was combined with the PDR technique, the estimation accuracy improved further down to a scope of one meter.
The research team is now working on assembling a tag with a built-in positioning board and applying it to location-based docent services for visitors at museums, science centers, and art galleries. The IOI GPS tag can be used for the purpose of tracking children and/or the elderly, and it can also be used to locate people or rescue workers lost in disaster-ridden or hazardous sites. On a different note, the sensor-fusion positioning algorithm and positioning board for vehicles are also under development for the tracking of vehicles entering indoor areas like underground parking lots.
When the IOI GPS board for vehicles is manufactured, the research team will work to collaborate with car manufacturers and car rental companies, and will also develop a sensor-fusion positioning algorithm for smartphones. Telecommunication companies seeking to diversify their programs in the field of location-based services will also be interested in the use the IOI GPS.
Professor Dong-Soo Han of the School of Computing, who leads the research team, said, “This is the first time to develop an indoor/outdoor integrated GPS system that can pinpoint locations in a building where there is no wireless signal or an indoor map, and there are an infinite number of areas it can be applied to. When the integration with the Korea Augmentation Satellite System (KASS) and the Korean GPS (KPS) System that began this year, is finally completed, Korea can become the leader in the field of GPS both indoors and outdoors, and we also have plans to manufacture semi-conductor chips for the IOI GPS System to keep the tech-gap between Korea and the followers.”
He added, "The guidance services at science centers, museums, and art galleries that uses IOI GPS tags can provide a set of data that would be very helpful for analyzing the visitors’ viewing traces. It is an essential piece of information required when the time comes to decide when to organize the next exhibit. We will be working on having it applied to the National Science Museum, first.”
The projects to develop the IOI GPS system and the trace analysis system for science centers were supported through Science, Culture, Exhibits and Services Capability Enhancement Program of the Ministry of Science and ICT.
Profile: Dong-Soo Han, Ph.D.Professorddsshhan@kaist.ac.krhttp://isilab.kaist.ac.kr
Intelligent Service Integration Lab.School of Computing
http://kaist.ac.kr/en/
Korea Advanced Institute of Science and Technology (KAIST)Daejeon, Republic of Korea
2022.07.13 View 12832
An AI-based, Indoor/Outdoor-Integrated (IOI) GPS System to Bring Seismic Waves in the Terrains of Positioning Technology
KAIST breaks new grounds in positioning technology with an AI-integrated GPS board that works both indoors and out
KAIST (President Kwang Hyung Lee) announced on the 8th that Professor Dong-Soo Han's research team (Intelligent Service Integration Lab) from the School of Computing has developed a GPS system that works both indoors and outdoors with quality precision regardless of the environment.
This Indoor/Outdoor-Integrated GPS System, or IOI GPS System, for short, uses the GPS signals outdoors and estimates locations indoors using signals from multiple sources like an inertial sensor, pressure sensors, geomagnetic sensors, and light sensors. To this end, the research team developed techniques to detect environmental changes such as entering a building, and methods to detect entrances, ground floors, stairs, elevators and levels of buildings by utilizing artificial intelligence techniques. Various landmark detecting techniques were also incorporated with pedestrian dead reckoning (PDR), a navigation tool for pedestrians, to devise the so-called “Sensor-Fusion Positioning Algorithm”.
To date, it was common to estimate locations based on wireless LAN signals or base station signals in a space where the GPS signal could not reach. However, the IOI GPS enables positioning even in buildings without signals nor indoor maps.
The algorithm developed by the research team can provide accurate floor information within a building where even big tech companies like Google and Apple's positioning services do not provide. Unlike other positioning methods that rely on visual data, geomagnetic positioning techniques, or wireless LAN, this system also has the advantage of not requiring any prior preparation. In other words, the foundation to enable the usage of a universal GPS system that works both indoors and outdoors anywhere in the world is now ready.
The research team also produced a circuit board for the purpose of operating the IOI GPS System, mounted with chips to receive and process GPS, Wi-Fi, and Bluetooth signals, along with an inertial sensor, a barometer, a magnetometer, and a light sensor. The sensor-fusion positioning algorithm the lab has developed is also incorporated in the board.
When the accuracy of the IOI GPS board was tested in the N1 building of KAIST’s main campus in Daejeon, it achieved an accuracy of about 95% in floor estimation and an accuracy of about 3 to 6 meters in distance estimation. As for the indoor/outdoor transition, the navigational mode change was completed in about 0.3 seconds. When it was combined with the PDR technique, the estimation accuracy improved further down to a scope of one meter.
The research team is now working on assembling a tag with a built-in positioning board and applying it to location-based docent services for visitors at museums, science centers, and art galleries. The IOI GPS tag can be used for the purpose of tracking children and/or the elderly, and it can also be used to locate people or rescue workers lost in disaster-ridden or hazardous sites. On a different note, the sensor-fusion positioning algorithm and positioning board for vehicles are also under development for the tracking of vehicles entering indoor areas like underground parking lots.
When the IOI GPS board for vehicles is manufactured, the research team will work to collaborate with car manufacturers and car rental companies, and will also develop a sensor-fusion positioning algorithm for smartphones. Telecommunication companies seeking to diversify their programs in the field of location-based services will also be interested in the use the IOI GPS.
Professor Dong-Soo Han of the School of Computing, who leads the research team, said, “This is the first time to develop an indoor/outdoor integrated GPS system that can pinpoint locations in a building where there is no wireless signal or an indoor map, and there are an infinite number of areas it can be applied to. When the integration with the Korea Augmentation Satellite System (KASS) and the Korean GPS (KPS) System that began this year, is finally completed, Korea can become the leader in the field of GPS both indoors and outdoors, and we also have plans to manufacture semi-conductor chips for the IOI GPS System to keep the tech-gap between Korea and the followers.”
He added, "The guidance services at science centers, museums, and art galleries that uses IOI GPS tags can provide a set of data that would be very helpful for analyzing the visitors’ viewing traces. It is an essential piece of information required when the time comes to decide when to organize the next exhibit. We will be working on having it applied to the National Science Museum, first.”
The projects to develop the IOI GPS system and the trace analysis system for science centers were supported through Science, Culture, Exhibits and Services Capability Enhancement Program of the Ministry of Science and ICT.
Profile: Dong-Soo Han, Ph.D.Professorddsshhan@kaist.ac.krhttp://isilab.kaist.ac.kr
Intelligent Service Integration Lab.School of Computing
http://kaist.ac.kr/en/
Korea Advanced Institute of Science and Technology (KAIST)Daejeon, Republic of Korea
2022.07.13 View 12832 -
 Professor Juho Kim’s Team Wins Best Paper Award at ACM CHI 2022
The research team led by Professor Juho Kim from the KAIST School of Computing won a Best Paper Award and an Honorable Mention Award at the Association for Computing Machinery Conference on Human Factors in Computing Systems (ACM CHI) held between April 30 and May 6.
ACM CHI is the world’s most recognized conference in the field of human computer interactions (HCI), and is ranked number one out of all HCI-related journals and conferences based on Google Scholar’s h-5 index. Best paper awards are given to works that rank in the top one percent, and honorable mention awards are given to the top five percent of the papers accepted by the conference.
Professor Juho Kim presented a total of seven papers at ACM CHI 2022, and tied for the largest number of papers. A total of 19 papers were affiliated with KAIST, putting it fifth out of all participating institutes and thereby proving KAIST’s competence in research.
One of Professor Kim’s research teams composed of Jeongyeon Kim (first author, MS graduate) from the School of Computing, MS candidate Yubin Choi from the School of Electrical Engineering, and Dr. Meng Xia (post-doctoral associate in the School of Computing, currently a post-doctoral associate at Carnegie Mellon University) received a best paper award for their paper, “Mobile-Friendly Content Design for MOOCs: Challenges, Requirements, and Design Opportunities”.
The study analyzed the difficulties experienced by learners watching video-based educational content in a mobile environment and suggests guidelines for solutions. The research team analyzed 134 survey responses and 21 interviews, and revealed that texts that are too small or overcrowded are what mainly brings down the legibility of video contents. Additionally, lighting, noise, and surrounding environments that change frequently are also important factors that may disturb a learning experience.
Based on these findings, the team analyzed the aptness of 41,722 frames from 101 video lectures for mobile environments, and confirmed that they generally show low levels of adequacy. For instance, in the case of text sizes, only 24.5% of the frames were shown to be adequate for learning in mobile environments. To overcome this issue, the research team suggested a guideline that may improve the legibility of video contents and help overcome the difficulties arising from mobile learning environments.
The importance of and dependency on video-based learning continue to rise, especially in the wake of the pandemic, and it is meaningful that this research suggested a means to analyze and tackle the difficulties of users that learn from the small screens of mobile devices. Furthermore, the paper also suggested technology that can solve problems related to video-based learning through human-AI collaborations, enhancing existing video lectures and improving learning experiences. This technology can be applied to various video-based platforms and content creation.
Meanwhile, a research team composed of Ph.D. candidate Tae Soo Kim (first author), MS candidate DaEun Choi, and Ph.D. candidate Yoonseo Choi from the School of Computing received an honorable mention award for their paper, “Stylette: styling the Web with Natural Language”.
The research team developed a novel interface technology that allows nonexperts who are unfamiliar with technical jargon to edit website features through speech. People often find it difficult to use or find the information they need from various websites due to accessibility issues, device-related constraints, inconvenient design, style preferences, etc. However, it is not easy for laymen to edit website features without expertise in programming or design, and most end up just putting up with the inconveniences. But what if the system could read the intentions of its users from their everyday language like “emphasize this part a little more”, or “I want a more modern design”, and edit the features automatically?
Based on this question, Professor Kim’s research team developed ‘Stylette’, a system in which AI analyses its users’ speech expressed in their natural language and automatically recommends a new style that best fits their intentions. The research team created a new system by putting together language AI, visual AI, and user interface technologies. On the linguistic side, a large-scale language model AI converts the intentions of the users expressed through their everyday language into adequate style elements. On the visual side, computer vision AI compares 1.7 million existing web design features and recommends a style adequate for the current website. In an experiment where 40 nonexperts were asked to edit a website design, the subjects that used this system showed double the success rate in a time span that was 35% shorter compared to the control group.
It is meaningful that this research proposed a practical case in which AI technology constructs intuitive interactions with users. The developed technology can be applied to existing design applications and web browsers in a plug-in format, and can be utilized to improve websites or for advertisements by collecting the natural intention data of users on a large scale.
2022.06.13 View 9783
Professor Juho Kim’s Team Wins Best Paper Award at ACM CHI 2022
The research team led by Professor Juho Kim from the KAIST School of Computing won a Best Paper Award and an Honorable Mention Award at the Association for Computing Machinery Conference on Human Factors in Computing Systems (ACM CHI) held between April 30 and May 6.
ACM CHI is the world’s most recognized conference in the field of human computer interactions (HCI), and is ranked number one out of all HCI-related journals and conferences based on Google Scholar’s h-5 index. Best paper awards are given to works that rank in the top one percent, and honorable mention awards are given to the top five percent of the papers accepted by the conference.
Professor Juho Kim presented a total of seven papers at ACM CHI 2022, and tied for the largest number of papers. A total of 19 papers were affiliated with KAIST, putting it fifth out of all participating institutes and thereby proving KAIST’s competence in research.
One of Professor Kim’s research teams composed of Jeongyeon Kim (first author, MS graduate) from the School of Computing, MS candidate Yubin Choi from the School of Electrical Engineering, and Dr. Meng Xia (post-doctoral associate in the School of Computing, currently a post-doctoral associate at Carnegie Mellon University) received a best paper award for their paper, “Mobile-Friendly Content Design for MOOCs: Challenges, Requirements, and Design Opportunities”.
The study analyzed the difficulties experienced by learners watching video-based educational content in a mobile environment and suggests guidelines for solutions. The research team analyzed 134 survey responses and 21 interviews, and revealed that texts that are too small or overcrowded are what mainly brings down the legibility of video contents. Additionally, lighting, noise, and surrounding environments that change frequently are also important factors that may disturb a learning experience.
Based on these findings, the team analyzed the aptness of 41,722 frames from 101 video lectures for mobile environments, and confirmed that they generally show low levels of adequacy. For instance, in the case of text sizes, only 24.5% of the frames were shown to be adequate for learning in mobile environments. To overcome this issue, the research team suggested a guideline that may improve the legibility of video contents and help overcome the difficulties arising from mobile learning environments.
The importance of and dependency on video-based learning continue to rise, especially in the wake of the pandemic, and it is meaningful that this research suggested a means to analyze and tackle the difficulties of users that learn from the small screens of mobile devices. Furthermore, the paper also suggested technology that can solve problems related to video-based learning through human-AI collaborations, enhancing existing video lectures and improving learning experiences. This technology can be applied to various video-based platforms and content creation.
Meanwhile, a research team composed of Ph.D. candidate Tae Soo Kim (first author), MS candidate DaEun Choi, and Ph.D. candidate Yoonseo Choi from the School of Computing received an honorable mention award for their paper, “Stylette: styling the Web with Natural Language”.
The research team developed a novel interface technology that allows nonexperts who are unfamiliar with technical jargon to edit website features through speech. People often find it difficult to use or find the information they need from various websites due to accessibility issues, device-related constraints, inconvenient design, style preferences, etc. However, it is not easy for laymen to edit website features without expertise in programming or design, and most end up just putting up with the inconveniences. But what if the system could read the intentions of its users from their everyday language like “emphasize this part a little more”, or “I want a more modern design”, and edit the features automatically?
Based on this question, Professor Kim’s research team developed ‘Stylette’, a system in which AI analyses its users’ speech expressed in their natural language and automatically recommends a new style that best fits their intentions. The research team created a new system by putting together language AI, visual AI, and user interface technologies. On the linguistic side, a large-scale language model AI converts the intentions of the users expressed through their everyday language into adequate style elements. On the visual side, computer vision AI compares 1.7 million existing web design features and recommends a style adequate for the current website. In an experiment where 40 nonexperts were asked to edit a website design, the subjects that used this system showed double the success rate in a time span that was 35% shorter compared to the control group.
It is meaningful that this research proposed a practical case in which AI technology constructs intuitive interactions with users. The developed technology can be applied to existing design applications and web browsers in a plug-in format, and can be utilized to improve websites or for advertisements by collecting the natural intention data of users on a large scale.
2022.06.13 View 9783 -
 Professor Sang Kil Cha Receives IEEE Test-of-Time Award
Professor Sang Kil Cha from the Graduate School of Information Security (GSIS) in the School of Computing received the Test-of-Time Award from IEEE Security & Privacy, a top conference in the field of information security.
The Test-of-Time Award recognizes the research papers that have influenced the field of information security the most over the past decade. Three papers were selected this year, and Professor Cha is the first Korean winner of the award.
The paper by Professor Cha was published in 2012 under the title, “Unleashing Mayhem on Binary Code”. It was the first to ever suggest an algorithm that automatically finds bugs in binary code and creates exploits that links them to an attack code.
The developed algorithm is a core technique used for world-class cyber security hacking competitions like the Cyber Grand Challenge, an AI hacking contest.
Starting with this research, Professor Cha has carried out various studies to develop technologies that can find bugs and vulnerabilities through binary analyses, and is currently developing B2R2, a Korean platform that can analyze various binary codes.
2022.06.13 View 6350
Professor Sang Kil Cha Receives IEEE Test-of-Time Award
Professor Sang Kil Cha from the Graduate School of Information Security (GSIS) in the School of Computing received the Test-of-Time Award from IEEE Security & Privacy, a top conference in the field of information security.
The Test-of-Time Award recognizes the research papers that have influenced the field of information security the most over the past decade. Three papers were selected this year, and Professor Cha is the first Korean winner of the award.
The paper by Professor Cha was published in 2012 under the title, “Unleashing Mayhem on Binary Code”. It was the first to ever suggest an algorithm that automatically finds bugs in binary code and creates exploits that links them to an attack code.
The developed algorithm is a core technique used for world-class cyber security hacking competitions like the Cyber Grand Challenge, an AI hacking contest.
Starting with this research, Professor Cha has carried out various studies to develop technologies that can find bugs and vulnerabilities through binary analyses, and is currently developing B2R2, a Korean platform that can analyze various binary codes.
2022.06.13 View 6350 -
 Baemin CEO Endows a Scholarship in Honor of the Late Professor Chwa
CEO Beom-Jun Kim of Woowa Brothers also known as ‘Baemin,’ a leading meal delivery app company, made a donation of 100 million KRW in honor of the late Professor Kyong-Yong Chwa from the School of Computing who passed away last year. The fund will be established for the “Kyong-Yong Chwa - Beom-Jun Kim Scholarship” to provide scholarships for four students over five years.
Kim finished his BS in 1997 and MS in 1999 at the School of Computing and Professor Chwa was his advisor. The late Professor Chwa was a pioneering scholar who brought the concept of computer algorithms to Korea. After graduating from Seoul National University in electric engineering, Professor Chwa earned his PhD at Northwestern University and began teaching at KAIST in 1980. Professor Chwa served as the President of the Korean Institute of Information Scientists and Engineers and a fellow emeritus at the Korean Academy of Science and Technology.
Professor Chwa encouraged younger students to participate in international computer programming contests. Under his wing, Team Korea, which was comprised of four high school students, including Kim, placed fourth in the International Olympiad Informatics (IOI). Kim, who participated in the contest as high school junior, won an individual gold medal in the fourth IOI competition in 1992. Since then, Korean students have actively participated in many competitions including the International Collegiate Programming Contest (ICPC) hosted by the Association for Computing Machinery.
Kim said, “I feel fortunate to have met so many good friends and distinguished professors. With them, I had opportunities to grow. I would like to provide such opportunities to my juniors at KAIST. Professor Chwa was a larger than life figure in the field of computer programming. He was always caring and supported us with a warm heart. I want this donation to help carry on his legacy for our students and for them to seek greater challenges and bigger dreams.”
2022.03.25 View 9369
Baemin CEO Endows a Scholarship in Honor of the Late Professor Chwa
CEO Beom-Jun Kim of Woowa Brothers also known as ‘Baemin,’ a leading meal delivery app company, made a donation of 100 million KRW in honor of the late Professor Kyong-Yong Chwa from the School of Computing who passed away last year. The fund will be established for the “Kyong-Yong Chwa - Beom-Jun Kim Scholarship” to provide scholarships for four students over five years.
Kim finished his BS in 1997 and MS in 1999 at the School of Computing and Professor Chwa was his advisor. The late Professor Chwa was a pioneering scholar who brought the concept of computer algorithms to Korea. After graduating from Seoul National University in electric engineering, Professor Chwa earned his PhD at Northwestern University and began teaching at KAIST in 1980. Professor Chwa served as the President of the Korean Institute of Information Scientists and Engineers and a fellow emeritus at the Korean Academy of Science and Technology.
Professor Chwa encouraged younger students to participate in international computer programming contests. Under his wing, Team Korea, which was comprised of four high school students, including Kim, placed fourth in the International Olympiad Informatics (IOI). Kim, who participated in the contest as high school junior, won an individual gold medal in the fourth IOI competition in 1992. Since then, Korean students have actively participated in many competitions including the International Collegiate Programming Contest (ICPC) hosted by the Association for Computing Machinery.
Kim said, “I feel fortunate to have met so many good friends and distinguished professors. With them, I had opportunities to grow. I would like to provide such opportunities to my juniors at KAIST. Professor Chwa was a larger than life figure in the field of computer programming. He was always caring and supported us with a warm heart. I want this donation to help carry on his legacy for our students and for them to seek greater challenges and bigger dreams.”
2022.03.25 View 9369 -
 Alumni Professor Cho at NYU Endows Scholarship for Female Computer Scientists
Alumni Professor Kyunghyun Cho at New York University endowed the “Lim Mi-Sook Scholarship” at KAIST for female computer scientists in honor of his mother.
Professor Cho, a graduate of the School of Computing in 2011 completed his master’s and PhD at Alto University in Finland in 2014. He has been teaching at NYU since 2015 and received the Samsung Ho-Am Prize for Engineering this year in recognition of his outstanding researches in the fields of machine learning and AI.
“I hope this will encourage young female students to continue their studies in computer science and encourage others to join the discipline in the future, thereby contributing to building a more diverse community of computer scientists,” he said in his written message. His parents and President Kwang Hyung Lee attended the donation ceremony held at the Daejeon campus on June 24.
Professor Cho has developed neural network machine learning translation algorithm that is widely being used in translation engines. His contributions to AI-powered translations and innovation in the industry led him to win one of the most prestigious prizes in Korea.
He decided to donate his 300 million KRW prize money to fund two 100 million KRW scholarships named after each of his parents: the Lim Mi-Sook Scholarship is for female computer scientists and the Bae-Gyu Scholarly Award for Classics is in honor of his father, who is a Korean literature professor at Soongsil University in Korea. He will also fund a scholarship at Alto University.
“I recall there were less than five female students out of 70 students in my cohort during my undergraduate studies at KAIST even in later 2000s. Back then, it just felt natural that boys majored computer science and girls in biology.”
He said he wanted to acknowledge his mother, who had to give up her teaching career in the 1980s to take care of her children. “It made all of us think more about the burden of raising children that is placed often disproportionately on mothers and how it should be better distributed among parents, relatives, and society in order to ensure and maximize equity in education as well as career development and advances.”
He added, “As a small step to help build a more diverse environment, I have decided to donate to this fund to provide a small supplement to the small group of female students majoring in computer science.
2021.07.01 View 10590
Alumni Professor Cho at NYU Endows Scholarship for Female Computer Scientists
Alumni Professor Kyunghyun Cho at New York University endowed the “Lim Mi-Sook Scholarship” at KAIST for female computer scientists in honor of his mother.
Professor Cho, a graduate of the School of Computing in 2011 completed his master’s and PhD at Alto University in Finland in 2014. He has been teaching at NYU since 2015 and received the Samsung Ho-Am Prize for Engineering this year in recognition of his outstanding researches in the fields of machine learning and AI.
“I hope this will encourage young female students to continue their studies in computer science and encourage others to join the discipline in the future, thereby contributing to building a more diverse community of computer scientists,” he said in his written message. His parents and President Kwang Hyung Lee attended the donation ceremony held at the Daejeon campus on June 24.
Professor Cho has developed neural network machine learning translation algorithm that is widely being used in translation engines. His contributions to AI-powered translations and innovation in the industry led him to win one of the most prestigious prizes in Korea.
He decided to donate his 300 million KRW prize money to fund two 100 million KRW scholarships named after each of his parents: the Lim Mi-Sook Scholarship is for female computer scientists and the Bae-Gyu Scholarly Award for Classics is in honor of his father, who is a Korean literature professor at Soongsil University in Korea. He will also fund a scholarship at Alto University.
“I recall there were less than five female students out of 70 students in my cohort during my undergraduate studies at KAIST even in later 2000s. Back then, it just felt natural that boys majored computer science and girls in biology.”
He said he wanted to acknowledge his mother, who had to give up her teaching career in the 1980s to take care of her children. “It made all of us think more about the burden of raising children that is placed often disproportionately on mothers and how it should be better distributed among parents, relatives, and society in order to ensure and maximize equity in education as well as career development and advances.”
He added, “As a small step to help build a more diverse environment, I have decided to donate to this fund to provide a small supplement to the small group of female students majoring in computer science.
2021.07.01 View 10590