%EB%8C%80%EA%B7%9C%EB%AA%A8
-
 천 개~수천만 개 이상의 대규모 사물인터넷 동시 통신기술 최초 개발
우리 대학 전기및전자공학부 김성민 교수 연구팀이 세계 최초로 천 개에서 수천만 개에 이르는 대규모 사물인터넷(IoT) 동시 통신을 위한 `밀리미터파 후방산란 시스템'을 개발했다고 28일 밝혔다.
밀리미터파 후방산란 기술은 대규모 통신을 지원하기 위한 기술로 주목받고 있다. 밀리미터파 통신은 30~300기가헤르츠(GHz)의 반송파 주파수 대역을 활용하는 통신으로, 5G/6G 등 표준에서 도입을 준비 중인 차세대 통신 기술이다. 이는 넓은 주파수 대역폭(10GHz 이상)을 확보할 수 있어 높은 확장성을 제공한다.
또한, 후방산란 기술은 기기가 직접 무선 신호를 생성하지 않고 공중에 존재하는 무선 신호를 반사해 정보를 전달하는 방식으로, 무선 신호를 생성하는데 전력을 소모하지 않기 때문에 초저전력 통신을 가능하게 할 수 있는 기술이다. 이는 낮은 설치비용으로 대규모 사물인터넷 기기의 광범위한 인터넷 연결성을 제공할 수 있다.
김성민 교수 연구팀은 밀리미터파 후방산란을 이용해 수천만 개의 사물인터넷 기기들이 실내에 배치된 복잡한 통신 환경에서 모든 신호가 동시에 복조되도록 설계하는 데 성공했다.
전기및전자공학부 배강민 박사과정이 제1 저자로 참여한 이번 연구는 모바일 시스템 분야의 최고 권위 국제 학술대회인 `ACM 모비시스(ACM MobiSys)' 2022에 이번 6월 발표됐으며, 최우수논문상을 수상했다. (논문명: OmniScatter: extreme sensitivity mmWave backscattering using commodity FMCW radar). 이는 작년 우리 대학 전기및전자공학부에서 아시아 대학 최초로 ACM 모비시스 2021 최우수논문상을 받은 이후 연속된 수상으로 더욱 의미가 깊다.
5G/6G 네트워크의 핵심 구성 요소 중 하나인 사물인터넷은 기하급수적인 성장세를 보이고 있으며, 2035년까지 1조 개 이상의 기기가 생산될 전망이다. 대규모 사물인터넷 기기들의 인터넷 연결을 지원하기 위해서 5G, 6G 표준 각각 4G 대비 10배 및 100배의 네트워크 밀도를 지원하는 것을 목표로 하고 있다. 따라서, 대규모 통신을 위한 실용적인 시스템의 필요성이 대두되고 있다.
그러나 현재 밀리미터 후방산란 시스템은 밀리미터파의 높은 주파수에 따른 신호 감쇄와 후방산란 시스템의 반사 손실이 합쳐져 제한적인 환경에서만 통신이 가능하다. 즉, 다양한 장애물과 반사체가 설치된 복잡한 통신 환경에서 작동하지 않아 상대적으로 자유로운 설치가 필요한 대규모 사물인터넷 기기에 광범위한 인터넷 연결성을 제공하는 데 한계가 있다.
연구팀은 FMCW(주파수 변조 연속파) 레이더의 높은 코딩 이득에서 해답을 찾았다. 연구팀은 레이더의 코딩 이득을 그대로 유지하는 동시에, 후방산란 신호와 주변 잡음을 원천적으로 분리해내는 신호 처리 방법을 개발해 기존 FMCW 레이더 대비 십만 배 이상 개선된 수신감도를 달성했다. 이는 실용적인 환경에서의 통신을 지원한다. 더욱이, 연구팀은 태그의 물리적인 위치에 따라 복조된 신호의 주파수가 달라지는 레이더 특성을 활용해 위치에 따라 통신 채널을 자연적으로 할당 받는 후방산란 시스템을 설계했다. 이는 초저전력 후방산란 통신이 10GHz 이상의 밀리미터파 주파수 대역폭을 전부 활용할 수 있게 하여 수천만 사물인터넷 기기들의 동시 통신을 지원한다.
개발된 시스템은 상용 기성품 레이더를 게이트웨이로 활용할 수 있어 적용 용이성이 높다. 또한, 연구팀의 후방산란 기술은 10마이크로와트(μW) 이하의 초저전력으로 작동해 코인 전지 하나로 40년 이상 구동 가능해 설치 및 유지보수 비용을 크게 줄일 수 있다.
연구팀은 다양한 장애물과 반사체가 설치된 사무실 환경에 무작위로 설치된 밀리미터파 후방산란 기기들의 통신이 가능함을 확인했다. 나아가 연구팀은 실험을 통해 총 1,100개의 기기가 송신하는 정보를 동시에 수신하는 것이 가능함을 확인하여 대규모 사물인터넷 구동을 검증했다.
이번 성과는 5G/6G 등 차세대 통신에서 요구하는 네트워크 밀도를 훨씬 웃도는 연결성을 자랑한다. 이에, 이번 시스템은 향후 도래할 초연결 시대를 위한 디딤돌 역할을 할 수 있을 것으로 기대된다.
김성민 교수는 "밀리미터파 후방산란은 대규모로 사물인터넷 기기들을 구동할 수 있는 꿈의 기술이며 이는 기존 어떠한 기술보다도 더욱 대규모의 통신을 초저전력으로 구동할 수 있다ˮ라며 "이 기술이 앞으로 도래할 초연결 시대에 사물인터넷의 보급을 위해 적극적으로 활용되길 기대한다ˮ라고 말했다.
한편 이번 연구는 삼성미래기술육성사업과 정보통신기획평가원의 지원을 받아 수행됐다.
2022.07.28 조회수 4470
천 개~수천만 개 이상의 대규모 사물인터넷 동시 통신기술 최초 개발
우리 대학 전기및전자공학부 김성민 교수 연구팀이 세계 최초로 천 개에서 수천만 개에 이르는 대규모 사물인터넷(IoT) 동시 통신을 위한 `밀리미터파 후방산란 시스템'을 개발했다고 28일 밝혔다.
밀리미터파 후방산란 기술은 대규모 통신을 지원하기 위한 기술로 주목받고 있다. 밀리미터파 통신은 30~300기가헤르츠(GHz)의 반송파 주파수 대역을 활용하는 통신으로, 5G/6G 등 표준에서 도입을 준비 중인 차세대 통신 기술이다. 이는 넓은 주파수 대역폭(10GHz 이상)을 확보할 수 있어 높은 확장성을 제공한다.
또한, 후방산란 기술은 기기가 직접 무선 신호를 생성하지 않고 공중에 존재하는 무선 신호를 반사해 정보를 전달하는 방식으로, 무선 신호를 생성하는데 전력을 소모하지 않기 때문에 초저전력 통신을 가능하게 할 수 있는 기술이다. 이는 낮은 설치비용으로 대규모 사물인터넷 기기의 광범위한 인터넷 연결성을 제공할 수 있다.
김성민 교수 연구팀은 밀리미터파 후방산란을 이용해 수천만 개의 사물인터넷 기기들이 실내에 배치된 복잡한 통신 환경에서 모든 신호가 동시에 복조되도록 설계하는 데 성공했다.
전기및전자공학부 배강민 박사과정이 제1 저자로 참여한 이번 연구는 모바일 시스템 분야의 최고 권위 국제 학술대회인 `ACM 모비시스(ACM MobiSys)' 2022에 이번 6월 발표됐으며, 최우수논문상을 수상했다. (논문명: OmniScatter: extreme sensitivity mmWave backscattering using commodity FMCW radar). 이는 작년 우리 대학 전기및전자공학부에서 아시아 대학 최초로 ACM 모비시스 2021 최우수논문상을 받은 이후 연속된 수상으로 더욱 의미가 깊다.
5G/6G 네트워크의 핵심 구성 요소 중 하나인 사물인터넷은 기하급수적인 성장세를 보이고 있으며, 2035년까지 1조 개 이상의 기기가 생산될 전망이다. 대규모 사물인터넷 기기들의 인터넷 연결을 지원하기 위해서 5G, 6G 표준 각각 4G 대비 10배 및 100배의 네트워크 밀도를 지원하는 것을 목표로 하고 있다. 따라서, 대규모 통신을 위한 실용적인 시스템의 필요성이 대두되고 있다.
그러나 현재 밀리미터 후방산란 시스템은 밀리미터파의 높은 주파수에 따른 신호 감쇄와 후방산란 시스템의 반사 손실이 합쳐져 제한적인 환경에서만 통신이 가능하다. 즉, 다양한 장애물과 반사체가 설치된 복잡한 통신 환경에서 작동하지 않아 상대적으로 자유로운 설치가 필요한 대규모 사물인터넷 기기에 광범위한 인터넷 연결성을 제공하는 데 한계가 있다.
연구팀은 FMCW(주파수 변조 연속파) 레이더의 높은 코딩 이득에서 해답을 찾았다. 연구팀은 레이더의 코딩 이득을 그대로 유지하는 동시에, 후방산란 신호와 주변 잡음을 원천적으로 분리해내는 신호 처리 방법을 개발해 기존 FMCW 레이더 대비 십만 배 이상 개선된 수신감도를 달성했다. 이는 실용적인 환경에서의 통신을 지원한다. 더욱이, 연구팀은 태그의 물리적인 위치에 따라 복조된 신호의 주파수가 달라지는 레이더 특성을 활용해 위치에 따라 통신 채널을 자연적으로 할당 받는 후방산란 시스템을 설계했다. 이는 초저전력 후방산란 통신이 10GHz 이상의 밀리미터파 주파수 대역폭을 전부 활용할 수 있게 하여 수천만 사물인터넷 기기들의 동시 통신을 지원한다.
개발된 시스템은 상용 기성품 레이더를 게이트웨이로 활용할 수 있어 적용 용이성이 높다. 또한, 연구팀의 후방산란 기술은 10마이크로와트(μW) 이하의 초저전력으로 작동해 코인 전지 하나로 40년 이상 구동 가능해 설치 및 유지보수 비용을 크게 줄일 수 있다.
연구팀은 다양한 장애물과 반사체가 설치된 사무실 환경에 무작위로 설치된 밀리미터파 후방산란 기기들의 통신이 가능함을 확인했다. 나아가 연구팀은 실험을 통해 총 1,100개의 기기가 송신하는 정보를 동시에 수신하는 것이 가능함을 확인하여 대규모 사물인터넷 구동을 검증했다.
이번 성과는 5G/6G 등 차세대 통신에서 요구하는 네트워크 밀도를 훨씬 웃도는 연결성을 자랑한다. 이에, 이번 시스템은 향후 도래할 초연결 시대를 위한 디딤돌 역할을 할 수 있을 것으로 기대된다.
김성민 교수는 "밀리미터파 후방산란은 대규모로 사물인터넷 기기들을 구동할 수 있는 꿈의 기술이며 이는 기존 어떠한 기술보다도 더욱 대규모의 통신을 초저전력으로 구동할 수 있다ˮ라며 "이 기술이 앞으로 도래할 초연결 시대에 사물인터넷의 보급을 위해 적극적으로 활용되길 기대한다ˮ라고 말했다.
한편 이번 연구는 삼성미래기술육성사업과 정보통신기획평가원의 지원을 받아 수행됐다.
2022.07.28 조회수 4470 -
 초대규모 인공지능 모델 처리하기 위한 세계 최고 성능의 기계학습 시스템 기술 개발
우리 연구진이 오늘날 인공지능 딥러닝 모델들을 처리하기 위해 필수적으로 사용되는 기계학습 시스템을 세계 최고 수준의 성능으로 끌어올렸다.
우리 대학 전산학부 김민수 교수 연구팀이 딥러닝 모델을 비롯한 기계학습 모델을 학습하거나 추론하기 위해 필수적으로 사용되는 기계학습 시스템의 성능을 대폭 높일 수 있는 세계 최고 수준의 행렬 연산자 융합 기술(일명 FuseME)을 개발했다고 20일 밝혔다.
오늘날 광범위한 산업 분야들에서 사용되고 있는 딥러닝 모델들은 대부분 구글 텐서플로우(TensorFlow)나 IBM 시스템DS와 같은 기계학습 시스템을 이용해 처리되는데, 딥러닝 모델의 규모가 점점 더 커지고, 그 모델에 사용되는 데이터의 규모가 점점 더 커짐에 따라, 이들을 원활히 처리할 수 있는 고성능 기계학습 시스템에 대한 중요성도 점점 더 커지고 있다.
일반적으로 딥러닝 모델은 행렬 곱셈, 행렬 합, 행렬 집계 등의 많은 행렬 연산자들로 구성된 방향성 비순환 그래프(Directed Acyclic Graph; 이하 DAG) 형태의 질의 계획으로 표현돼 기계학습 시스템에 의해 처리된다. 모델과 데이터의 규모가 클 때는 일반적으로 DAG 질의 계획은 수많은 컴퓨터로 구성된 클러스터에서 처리된다. 클러스터의 사양에 비해 모델과 데이터의 규모가 커지면 처리에 실패하거나 시간이 오래 걸리는 근본적인 문제가 있었다.
지금까지는 더 큰 규모의 모델이나 데이터를 처리하기 위해 단순히 컴퓨터 클러스터의 규모를 증가시키는 방식을 주로 사용했다. 그러나, 김 교수팀은 DAG 질의 계획을 구성하는 각 행렬 연산자로부터 생성되는 일종의 `중간 데이터'를 메모리에 저장하거나 네트워크 통신을 통해 다른 컴퓨터로 전송하는 것이 문제의 원인임에 착안해, 중간 데이터를 저장하지 않거나 다른 컴퓨터로 전송하지 않도록 여러 행렬 연산자들을 하나의 연산자로 융합(fusion)하는 세계 최고 성능의 융합 기술인 FuseME(Fused Matrix Engine)을 개발해 문제를 해결했다.
현재까지의 기계학습 시스템들은 낮은 수준의 연산자 융합 기술만을 사용하고 있었다. 가장 복잡한 행렬 연산자인 행렬 곱을 제외한 나머지 연산자들만 융합해 성능이 별로 개선되지 않거나, 전체 DAG 질의 계획을 단순히 하나의 연산자처럼 실행해 메모리 부족으로 처리에 실패하는 한계를 지니고 있었다.
김 교수팀이 개발한 FuseME 기술은 수십 개 이상의 행렬 연산자들로 구성되는 DAG 질의 계획에서 어떤 연산자들끼리 서로 융합하는 것이 더 우수한 성능을 내는지 비용 기반으로 판별해 그룹으로 묶고, 클러스터의 사양, 네트워크 통신 속도, 입력 데이터 크기 등을 모두 고려해 각 융합 연산자 그룹을 메모리 부족으로 처리에 실패하지 않으면서 이론적으로 최적 성능을 낼 수 있는 CFO(Cuboid-based Fused Operator)라 불리는 연산자로 융합함으로써 한계를 극복했다. 이때, 행렬 곱 연산자까지 포함해 연산자들을 융합하는 것이 핵심이다.
김민수 교수 연구팀은 FuseME 기술을 종래 최고 기술로 알려진 구글의 텐서플로우나 IBM의 시스템DS와 비교 평가한 결과, 딥러닝 모델의 처리 속도를 최대 8.8배 향상하고, 텐서플로우나 시스템DS가 처리할 수 없는 훨씬 더 큰 규모의 모델 및 데이터를 처리하는 데 성공함을 보였다. 또한, FuseME의 CFO 융합 연산자는 종래의 최고 수준 융합 연산자와 비교해 처리 속도를 최대 238배 향상시키고, 네트워크 통신 비용을 최대 64배 감소시키는 사실을 확인했다.
김 교수팀은 이미 지난 2019년에 초대규모 행렬 곱 연산에 대해 종래 세계 최고 기술이었던 IBM 시스템ML과 슈퍼컴퓨팅 분야의 스칼라팩(ScaLAPACK) 대비 성능과 처리 규모를 훨씬 향상시킨 DistME라는 기술을 개발해 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표한 바 있다. 이번 FuseME 기술은 연산자 융합이 가능하도록 DistME를 한층 더 발전시킨 것으로, 해당 분야를 세계 최고 수준의 기술력을 바탕으로 지속적으로 선도하는 쾌거를 보여준 것이다.
교신저자로 참여한 김민수 교수는 "연구팀이 개발한 새로운 기술은 딥러닝 등 기계학습 모델의 처리 규모와 성능을 획기적으로 높일 수 있어 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 현재 GraphAI(그래파이) 스타트업의 공동 창업자인 한동형 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 16일 미국 필라델피아에서 열린 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표됐다. (논문명 : FuseME: Distributed Matrix Computation Engine based on Cuboid-based Fused Operator and Plan Generation).
한편, 이번 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
2022.06.20 조회수 4956
초대규모 인공지능 모델 처리하기 위한 세계 최고 성능의 기계학습 시스템 기술 개발
우리 연구진이 오늘날 인공지능 딥러닝 모델들을 처리하기 위해 필수적으로 사용되는 기계학습 시스템을 세계 최고 수준의 성능으로 끌어올렸다.
우리 대학 전산학부 김민수 교수 연구팀이 딥러닝 모델을 비롯한 기계학습 모델을 학습하거나 추론하기 위해 필수적으로 사용되는 기계학습 시스템의 성능을 대폭 높일 수 있는 세계 최고 수준의 행렬 연산자 융합 기술(일명 FuseME)을 개발했다고 20일 밝혔다.
오늘날 광범위한 산업 분야들에서 사용되고 있는 딥러닝 모델들은 대부분 구글 텐서플로우(TensorFlow)나 IBM 시스템DS와 같은 기계학습 시스템을 이용해 처리되는데, 딥러닝 모델의 규모가 점점 더 커지고, 그 모델에 사용되는 데이터의 규모가 점점 더 커짐에 따라, 이들을 원활히 처리할 수 있는 고성능 기계학습 시스템에 대한 중요성도 점점 더 커지고 있다.
일반적으로 딥러닝 모델은 행렬 곱셈, 행렬 합, 행렬 집계 등의 많은 행렬 연산자들로 구성된 방향성 비순환 그래프(Directed Acyclic Graph; 이하 DAG) 형태의 질의 계획으로 표현돼 기계학습 시스템에 의해 처리된다. 모델과 데이터의 규모가 클 때는 일반적으로 DAG 질의 계획은 수많은 컴퓨터로 구성된 클러스터에서 처리된다. 클러스터의 사양에 비해 모델과 데이터의 규모가 커지면 처리에 실패하거나 시간이 오래 걸리는 근본적인 문제가 있었다.
지금까지는 더 큰 규모의 모델이나 데이터를 처리하기 위해 단순히 컴퓨터 클러스터의 규모를 증가시키는 방식을 주로 사용했다. 그러나, 김 교수팀은 DAG 질의 계획을 구성하는 각 행렬 연산자로부터 생성되는 일종의 `중간 데이터'를 메모리에 저장하거나 네트워크 통신을 통해 다른 컴퓨터로 전송하는 것이 문제의 원인임에 착안해, 중간 데이터를 저장하지 않거나 다른 컴퓨터로 전송하지 않도록 여러 행렬 연산자들을 하나의 연산자로 융합(fusion)하는 세계 최고 성능의 융합 기술인 FuseME(Fused Matrix Engine)을 개발해 문제를 해결했다.
현재까지의 기계학습 시스템들은 낮은 수준의 연산자 융합 기술만을 사용하고 있었다. 가장 복잡한 행렬 연산자인 행렬 곱을 제외한 나머지 연산자들만 융합해 성능이 별로 개선되지 않거나, 전체 DAG 질의 계획을 단순히 하나의 연산자처럼 실행해 메모리 부족으로 처리에 실패하는 한계를 지니고 있었다.
김 교수팀이 개발한 FuseME 기술은 수십 개 이상의 행렬 연산자들로 구성되는 DAG 질의 계획에서 어떤 연산자들끼리 서로 융합하는 것이 더 우수한 성능을 내는지 비용 기반으로 판별해 그룹으로 묶고, 클러스터의 사양, 네트워크 통신 속도, 입력 데이터 크기 등을 모두 고려해 각 융합 연산자 그룹을 메모리 부족으로 처리에 실패하지 않으면서 이론적으로 최적 성능을 낼 수 있는 CFO(Cuboid-based Fused Operator)라 불리는 연산자로 융합함으로써 한계를 극복했다. 이때, 행렬 곱 연산자까지 포함해 연산자들을 융합하는 것이 핵심이다.
김민수 교수 연구팀은 FuseME 기술을 종래 최고 기술로 알려진 구글의 텐서플로우나 IBM의 시스템DS와 비교 평가한 결과, 딥러닝 모델의 처리 속도를 최대 8.8배 향상하고, 텐서플로우나 시스템DS가 처리할 수 없는 훨씬 더 큰 규모의 모델 및 데이터를 처리하는 데 성공함을 보였다. 또한, FuseME의 CFO 융합 연산자는 종래의 최고 수준 융합 연산자와 비교해 처리 속도를 최대 238배 향상시키고, 네트워크 통신 비용을 최대 64배 감소시키는 사실을 확인했다.
김 교수팀은 이미 지난 2019년에 초대규모 행렬 곱 연산에 대해 종래 세계 최고 기술이었던 IBM 시스템ML과 슈퍼컴퓨팅 분야의 스칼라팩(ScaLAPACK) 대비 성능과 처리 규모를 훨씬 향상시킨 DistME라는 기술을 개발해 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표한 바 있다. 이번 FuseME 기술은 연산자 융합이 가능하도록 DistME를 한층 더 발전시킨 것으로, 해당 분야를 세계 최고 수준의 기술력을 바탕으로 지속적으로 선도하는 쾌거를 보여준 것이다.
교신저자로 참여한 김민수 교수는 "연구팀이 개발한 새로운 기술은 딥러닝 등 기계학습 모델의 처리 규모와 성능을 획기적으로 높일 수 있어 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다ˮ 라고 말했다.
이번 연구에는 김 교수의 제자이자 현재 GraphAI(그래파이) 스타트업의 공동 창업자인 한동형 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 16일 미국 필라델피아에서 열린 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표됐다. (논문명 : FuseME: Distributed Matrix Computation Engine based on Cuboid-based Fused Operator and Plan Generation).
한편, 이번 연구는 한국연구재단 선도연구센터 사업 및 중견연구자 지원사업, 과기정통부 IITP SW스타랩 사업의 지원을 받아 수행됐다.
2022.06.20 조회수 4956 -
 산업및시스템공학과 장영재 교수, 디지털혁신 SW부문 대상(과기부 장관상) 수상
우리 대학 산업및시스템공학과 장영재 교수가 CDE학회(Society for Computational Design and Engineering)에서 주관하는 2022 디지털혁신 SW 공모전에서 대상인 '과기부 장관상'을 수상하였다.
장영재 교수 연구진은 2016년부터 강화학습 기반 대규모 군집 물류 자동화 로봇을 제어하는 SW개발을 진행해왔다. 관련 기술은 2019년 KAIST 10대 기술로 선정되었으며 IEEE SMILE과 CIRP등에서 최고 논문으로 선정되기도 하였다.
KAIST의 원천 기술을 기반으로 장영재 교수 연구실 출신 박사들이 <다임리서치>란 스타트업을 2020년 설립하였으며 작년 SW 개발에 성공 글로벌 반도체, 평판디스플레이, 전기차 베터리 (2차전지)제조 공장에 SW를 공급하고 있다. KAIST 연구소 기업인 <다임리서치>는 인공지능기술과 디지털트윈 기술을 결합한 제조 SW기업으로 성장중이다.
장영재 교수는 "이번 대상수상은 KAIST 기술을 통한 사업화 및 산업계 기여에 의미를 둔다"라 언급하였다.
2022.02.17 조회수 5843
산업및시스템공학과 장영재 교수, 디지털혁신 SW부문 대상(과기부 장관상) 수상
우리 대학 산업및시스템공학과 장영재 교수가 CDE학회(Society for Computational Design and Engineering)에서 주관하는 2022 디지털혁신 SW 공모전에서 대상인 '과기부 장관상'을 수상하였다.
장영재 교수 연구진은 2016년부터 강화학습 기반 대규모 군집 물류 자동화 로봇을 제어하는 SW개발을 진행해왔다. 관련 기술은 2019년 KAIST 10대 기술로 선정되었으며 IEEE SMILE과 CIRP등에서 최고 논문으로 선정되기도 하였다.
KAIST의 원천 기술을 기반으로 장영재 교수 연구실 출신 박사들이 <다임리서치>란 스타트업을 2020년 설립하였으며 작년 SW 개발에 성공 글로벌 반도체, 평판디스플레이, 전기차 베터리 (2차전지)제조 공장에 SW를 공급하고 있다. KAIST 연구소 기업인 <다임리서치>는 인공지능기술과 디지털트윈 기술을 결합한 제조 SW기업으로 성장중이다.
장영재 교수는 "이번 대상수상은 KAIST 기술을 통한 사업화 및 산업계 기여에 의미를 둔다"라 언급하였다.
2022.02.17 조회수 5843 -
 스페이스 허브-KAIST 우주연구센터 설립
우리 대학이 한화의 우주 산업을 총괄하는 스페이스 허브(Space Hub)와 공동으로 우주연구센터를 설립한다. 민간 기업과 대학이 함께 만든 우주 분야 연구센터로는 국내 최대 규모로 17일 오후 3시 우리 대학 본관 제2 회의실에서 관련 MOU가 체결됐다. 스페이스 허브-KAIST 우주연구센터는 연구부총장 직속으로 설립되며, 한화는 100억 원을 투입할 예정이다. 스페이스 허브는 지난 3월 출범한 우주 사업 총괄 본부격으로 한화에어로스페이스, 한화시스템, ㈜한화와 쎄트렉아이 등이 참여하고 있다. 스페이스 허브와 우리 대학의 첫 연구 프로젝트는 저궤도 위성통신 기술 ‘ISL(Inter Satellite Links, 위성 간 통신 기술)’ 개발이다. ISL은 저궤도 위성을 활용한 통신 서비스를 구현하는 필수 기술이다. 위성 간 데이터를 ‘레이저’로 주고 받는 게 핵심이다. 저궤도 위성은 기존의 정지궤도 위성과 달리, ISL 기술을 적용하면 여러 대의 위성이 레이저로 데이터를 주고 받으면서 고용량의 데이터를 빠르게 처리할 수 있다. 또 운항 중인 비행기와 배에서, 또 전기가 들어가지 않는 오지에서도 인터넷 공급이 가능해지며, 한화시스템이 추진하는 위성통신·에어모빌리티 사업에 곧바로 활용될 수 있다.
미국의 스페이스X 등도 ISL 개발에 힘을 쏟고 있다. 천문학적 돈이 들어가는 우주 산업에서 당장 경제 효과를 기대할 수 있다는 점에서다. 민간 우주 개발 부문에서 전 세계적으로 ISL 개발 전쟁이 뜨거운 이유다.
우주연구센터는 ISL 프로젝트와 더불어 민간 우주 개발과 위성 상용화에 속도를 높일 다양한 기술을 함께 연구할 예정이다. 발사체 기술, 위성 자세 제어, 관측 기술, 우주 에너지 기술 등이 여기에 포함된다. 새로운 프로젝트에 필요한 인재 육성도 적극 나선다. KAIST 연구처는 “단순한 산학 협력을 넘어선 실질적인 상용화 기술을 개발한다는 점에서 큰 의미가 있다”면서 “국내 우주 산업이 민간 주도의 뉴 스페이스 시대를 맞는 전환점이 될 것” 라고 밝혔다.
2021.05.18 조회수 15512
스페이스 허브-KAIST 우주연구센터 설립
우리 대학이 한화의 우주 산업을 총괄하는 스페이스 허브(Space Hub)와 공동으로 우주연구센터를 설립한다. 민간 기업과 대학이 함께 만든 우주 분야 연구센터로는 국내 최대 규모로 17일 오후 3시 우리 대학 본관 제2 회의실에서 관련 MOU가 체결됐다. 스페이스 허브-KAIST 우주연구센터는 연구부총장 직속으로 설립되며, 한화는 100억 원을 투입할 예정이다. 스페이스 허브는 지난 3월 출범한 우주 사업 총괄 본부격으로 한화에어로스페이스, 한화시스템, ㈜한화와 쎄트렉아이 등이 참여하고 있다. 스페이스 허브와 우리 대학의 첫 연구 프로젝트는 저궤도 위성통신 기술 ‘ISL(Inter Satellite Links, 위성 간 통신 기술)’ 개발이다. ISL은 저궤도 위성을 활용한 통신 서비스를 구현하는 필수 기술이다. 위성 간 데이터를 ‘레이저’로 주고 받는 게 핵심이다. 저궤도 위성은 기존의 정지궤도 위성과 달리, ISL 기술을 적용하면 여러 대의 위성이 레이저로 데이터를 주고 받으면서 고용량의 데이터를 빠르게 처리할 수 있다. 또 운항 중인 비행기와 배에서, 또 전기가 들어가지 않는 오지에서도 인터넷 공급이 가능해지며, 한화시스템이 추진하는 위성통신·에어모빌리티 사업에 곧바로 활용될 수 있다.
미국의 스페이스X 등도 ISL 개발에 힘을 쏟고 있다. 천문학적 돈이 들어가는 우주 산업에서 당장 경제 효과를 기대할 수 있다는 점에서다. 민간 우주 개발 부문에서 전 세계적으로 ISL 개발 전쟁이 뜨거운 이유다.
우주연구센터는 ISL 프로젝트와 더불어 민간 우주 개발과 위성 상용화에 속도를 높일 다양한 기술을 함께 연구할 예정이다. 발사체 기술, 위성 자세 제어, 관측 기술, 우주 에너지 기술 등이 여기에 포함된다. 새로운 프로젝트에 필요한 인재 육성도 적극 나선다. KAIST 연구처는 “단순한 산학 협력을 넘어선 실질적인 상용화 기술을 개발한다는 점에서 큰 의미가 있다”면서 “국내 우주 산업이 민간 주도의 뉴 스페이스 시대를 맞는 전환점이 될 것” 라고 밝혔다.
2021.05.18 조회수 15512 -
 세계 최대 규모의 3차원 암 게놈 지도 구축
우리 대학 생명과학과 정인경 교수가 한국생명공학연구원 국가생명연구자원정보센터(KOBIC) 이병욱 박사 연구팀과 공동연구를 통해 전 세계 최대 규모의 3차원 암 게놈 지도 데이터베이스를 구축해 공개했다고 28일 밝혔다. (데이터베이스 주소: 3div.kr)
공동연구팀은 인체 정상 조직과 암 조직, 그리고 다양한 세포주 대상 3차원 게놈 지도를 분석 및 데이터베이스화 해, 약 400여 종 이상의 3차원 인간 게놈 지도를 구축했으며, 이를 통해 암세포에서 빈번하게 발생하는 대규모 유전체 구조 변이(structural variation)의 기능을 해독할 수 있는 신규 전략을 제시했다.
정인경 교수, 이병욱 박사가 공동 교신 저자로 참여한 이번 연구 결과는 국제 학술지 `핵산 연구(Nucleic Acid Research)' 저널 11월 27일 字 온라인판에 게재됐다. (논문명 : 3DIV update for 2021: a comprehensive resource of 3D genome and 3D cancer genome)
현재까지 많은 연구를 통해 암세포 유전체에서 발생하는 돌연변이를 규명해 암의 발병 기전을 이해하려는 시도가 있었다. 최근에는 유전자에서 발생하는 점 돌연변이뿐 아니라 대규모 구조 변이에 관한 연구가 활발하게 이루어지고 있으며, 이들을 활용한 신규 암세포의 특이적 유전자 발현 조절 기전 규명의 중요성이 제시되고 있다.
하지만, 대다수의 구조 변이는 DNA가 단백질을 생성하지 않는 비 전사 지역에 존재해, 1차원적 게놈 서열 분석만으로 이들의 기능을 규명하는 데는 한계가 있었다.
한편 지난 10년간 비약적으로 발전한 3차원 게놈 구조 연구는 비 전사 지역에 존재하는 대규모 구조 변이로 인해 생성되거나 소실되는 염색질 고리 구조(chromatin loop)를 3차원 게놈 구조 해독을 통해 규명하면 유전자 조절 기능을 해독할 수 있다는 모델을 제시하고 있다.
이에 정인경 교수 연구팀은 지금까지 공개된 모든 암 유전체의 3차원 게놈 지도를 확보해 전 세계 최대 규모의 3차원 암 유전체 지도를 작성했다. 그리고 대규모 구조 변이와 3차원 게놈 지도를 연결할 수 있는 분석 도구들을 개발했다. 그 결과 연구팀은 대규모 암 유전체 구조 변이에 따른 3차원 게놈 구조의 변화 그리고 이들의 표적 유전자를 규명할 수 있었다.
공동 교신 저자 이병욱 박사는 "최근 세포 내 3차원 게놈 구조 변화가 다양한 질병, 특히 암의 원인이 된다는 것이 밝혀지고 있는데, 이번 연구를 통해 이를 연구할 수 있는 도구들을 세계 최초로 개발했다ˮ라며 "이번 연구 결과를 활용하면 암의 발병 원리를 이해하고 더 나아가 항암제 개발에도 중요한 정보를 제공할 것으로 기대된다ˮ라고 말했다.
정인경 교수는 "암에서 빈번하게 발생하는 대규모 구조 변이의 기능을 3차원 게놈 구조 해독을 통해 정밀하게 규명 가능함을 보여줬다ˮ라며 "이번 연구 결과는 아직 해독이 완벽하게 이루어지고 있지 않은 암 유전체를 정밀하게 해독하는 기술을 한 단계 더 발전시키는 계기가 될 것이다”라고 말했다.
이번 연구는 한국연구재단 기반산업화 인프라 그리고 서경배과학재단의 지원을 통해 수행됐다.
2020.12.28 조회수 48294
세계 최대 규모의 3차원 암 게놈 지도 구축
우리 대학 생명과학과 정인경 교수가 한국생명공학연구원 국가생명연구자원정보센터(KOBIC) 이병욱 박사 연구팀과 공동연구를 통해 전 세계 최대 규모의 3차원 암 게놈 지도 데이터베이스를 구축해 공개했다고 28일 밝혔다. (데이터베이스 주소: 3div.kr)
공동연구팀은 인체 정상 조직과 암 조직, 그리고 다양한 세포주 대상 3차원 게놈 지도를 분석 및 데이터베이스화 해, 약 400여 종 이상의 3차원 인간 게놈 지도를 구축했으며, 이를 통해 암세포에서 빈번하게 발생하는 대규모 유전체 구조 변이(structural variation)의 기능을 해독할 수 있는 신규 전략을 제시했다.
정인경 교수, 이병욱 박사가 공동 교신 저자로 참여한 이번 연구 결과는 국제 학술지 `핵산 연구(Nucleic Acid Research)' 저널 11월 27일 字 온라인판에 게재됐다. (논문명 : 3DIV update for 2021: a comprehensive resource of 3D genome and 3D cancer genome)
현재까지 많은 연구를 통해 암세포 유전체에서 발생하는 돌연변이를 규명해 암의 발병 기전을 이해하려는 시도가 있었다. 최근에는 유전자에서 발생하는 점 돌연변이뿐 아니라 대규모 구조 변이에 관한 연구가 활발하게 이루어지고 있으며, 이들을 활용한 신규 암세포의 특이적 유전자 발현 조절 기전 규명의 중요성이 제시되고 있다.
하지만, 대다수의 구조 변이는 DNA가 단백질을 생성하지 않는 비 전사 지역에 존재해, 1차원적 게놈 서열 분석만으로 이들의 기능을 규명하는 데는 한계가 있었다.
한편 지난 10년간 비약적으로 발전한 3차원 게놈 구조 연구는 비 전사 지역에 존재하는 대규모 구조 변이로 인해 생성되거나 소실되는 염색질 고리 구조(chromatin loop)를 3차원 게놈 구조 해독을 통해 규명하면 유전자 조절 기능을 해독할 수 있다는 모델을 제시하고 있다.
이에 정인경 교수 연구팀은 지금까지 공개된 모든 암 유전체의 3차원 게놈 지도를 확보해 전 세계 최대 규모의 3차원 암 유전체 지도를 작성했다. 그리고 대규모 구조 변이와 3차원 게놈 지도를 연결할 수 있는 분석 도구들을 개발했다. 그 결과 연구팀은 대규모 암 유전체 구조 변이에 따른 3차원 게놈 구조의 변화 그리고 이들의 표적 유전자를 규명할 수 있었다.
공동 교신 저자 이병욱 박사는 "최근 세포 내 3차원 게놈 구조 변화가 다양한 질병, 특히 암의 원인이 된다는 것이 밝혀지고 있는데, 이번 연구를 통해 이를 연구할 수 있는 도구들을 세계 최초로 개발했다ˮ라며 "이번 연구 결과를 활용하면 암의 발병 원리를 이해하고 더 나아가 항암제 개발에도 중요한 정보를 제공할 것으로 기대된다ˮ라고 말했다.
정인경 교수는 "암에서 빈번하게 발생하는 대규모 구조 변이의 기능을 3차원 게놈 구조 해독을 통해 정밀하게 규명 가능함을 보여줬다ˮ라며 "이번 연구 결과는 아직 해독이 완벽하게 이루어지고 있지 않은 암 유전체를 정밀하게 해독하는 기술을 한 단계 더 발전시키는 계기가 될 것이다”라고 말했다.
이번 연구는 한국연구재단 기반산업화 인프라 그리고 서경배과학재단의 지원을 통해 수행됐다.
2020.12.28 조회수 48294 -
 교수학습혁신센터, 투명 보드 시스템 갖춘 스튜디오 오픈
우리 대학 교수학습혁신센터(센터장 권길헌)는 지난 19일(금) 창의학습관 107호실에 칠판의 뒷면에 서서 앞을 보며 글쓰기가 가능한 ‘정면판서 스튜디오’를 새로 오픈했다.
'정면판서 스튜디오'는 기존의 스튜디오와 달리 교수자의 판서모습을 정면에서 촬영이 가능한 시스템으로, 강의내용을 보다 선명하고 효과적으로 표현할 수 있고, 학습자들과의 지속적인 눈맞춤이 가능한 장점이 있다.
이를 위해 △ 특수코팅 및 가공처리한 판서전용 투명보드 △ 판서의 밝기 및 촬영 제어가 가능한 원터치 컨트롤러 △ 전용 강의녹화 소프트웨어 및 카메라 등이 설치되었다.
이 스튜디오는 양방향 학습시스템인 ‘Education 3.0’ 수업 및 ‘대규모 온라인 공개강좌(MOOC: Massive Online Open Course)’ 등을 위한 강의 콘텐츠 제작에 유용하게 활용될 것으로 기대된다.
시연회는 3월 2일(수) ~ 3월 11일(금) 교내 창의학습관(E11) 107호에서 열린다. 끝.
2016.02.23 조회수 9411
교수학습혁신센터, 투명 보드 시스템 갖춘 스튜디오 오픈
우리 대학 교수학습혁신센터(센터장 권길헌)는 지난 19일(금) 창의학습관 107호실에 칠판의 뒷면에 서서 앞을 보며 글쓰기가 가능한 ‘정면판서 스튜디오’를 새로 오픈했다.
'정면판서 스튜디오'는 기존의 스튜디오와 달리 교수자의 판서모습을 정면에서 촬영이 가능한 시스템으로, 강의내용을 보다 선명하고 효과적으로 표현할 수 있고, 학습자들과의 지속적인 눈맞춤이 가능한 장점이 있다.
이를 위해 △ 특수코팅 및 가공처리한 판서전용 투명보드 △ 판서의 밝기 및 촬영 제어가 가능한 원터치 컨트롤러 △ 전용 강의녹화 소프트웨어 및 카메라 등이 설치되었다.
이 스튜디오는 양방향 학습시스템인 ‘Education 3.0’ 수업 및 ‘대규모 온라인 공개강좌(MOOC: Massive Online Open Course)’ 등을 위한 강의 콘텐츠 제작에 유용하게 활용될 것으로 기대된다.
시연회는 3월 2일(수) ~ 3월 11일(금) 교내 창의학습관(E11) 107호에서 열린다. 끝.
2016.02.23 조회수 9411 -
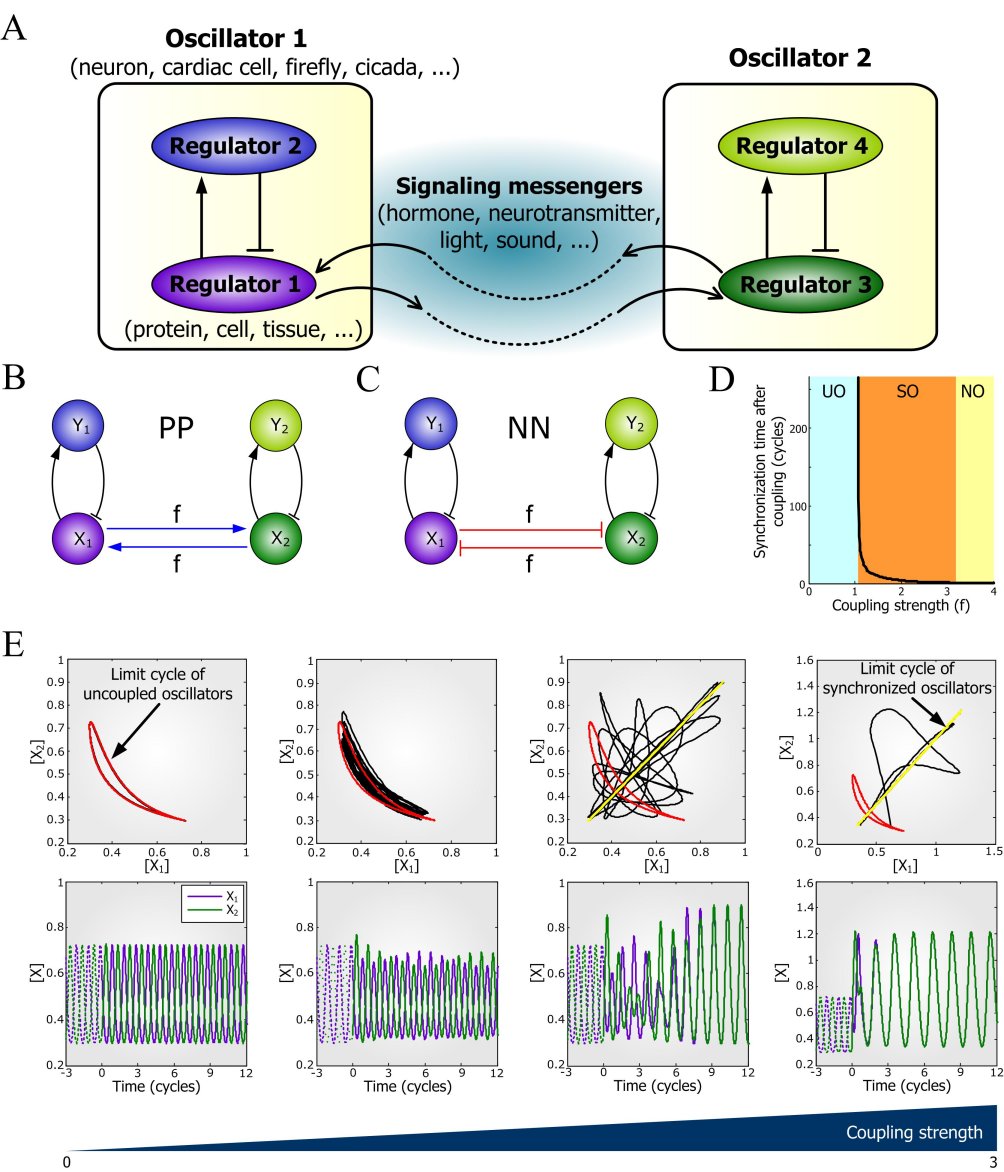 매미와 개구리는 지휘자없이 어떻게 합창할까
나무위의 매미와 논두렁의 개구리는 지휘자 없이 어떻게 합창할까? 이와 관련해서, KAIST 바이오 및 뇌공학과의 조광현 교수는 생명체의 동기화된 주기적 진동신호의 생성원리를 최근 규명했다. 나무에 붙어있는 많은 반딧불들의 동시다발적인 깜빡임, 매미들의 조율된 울음소리, 뇌신경세포들간의 전기신호, 세포내 분자들의 농도변화에 이르기까지 생명체는 다양한 형태의 주기적 진동신호 교환을 통해 정보를 전달하는데, 이들은 놀랍게도 정확히 동일한 위상(phase)으로 동기화되곤 한다. 이는 마치 오케스트라에서 지휘자 없이도 모든 연주가 일정한 박자에 맞춰 이루어지는 것과 같다.
어떻게 생명체의 여러 주기적 진동신호들이 그러한 동기화를 이루는가?
우리학교 바이오및뇌공학과 조광현(曺光鉉) 교수 연구팀이 대규모 가상세포(virtual cell)실험을 통해 생명체의 다양한 주기적 진동(oscillation)신호들이 동기화(synchronization)되는 보편적인 원리를 규명했다.
曺교수팀은 이번 연구를 통해 여러 독립적인 주기적 진동신호들은 양성피드백(positive feedback)을 통해 서로의 위상에 영향을 줘 하나의 동일한 위상으로 수렴되는 현상을 밝혀냈다.
특히 양성피드백은 이중활성(double activation) 또는 이중억제(double inhibition)의 구조로 구현된다. 이중활성피드백은 연결시간지연이 짧을 때, 이중억제피드백은 연결시간지연이 길 때 보다 안정적인 신호동기화를 가능하게 했다.
또한, 노이즈(noise) 교란이 있을 때 이중활성피드백은 진동신호의 주기보다 진폭을 안정적으로 유지하는 반면 이중억제피드백은 연결강도에 불규칙한 변화가 주어졌을 때 일정한 주기와 진폭을 유지시켜줬다. 현존하는 대부분의 현상들이 이러한 원칙을 따르고 있었다.
이번에 규명된 원리는 생체내 주기적 진동신호의 동기화가 교란될 때 발생하는 뇌질환 등 여러 질병의 원인을 새롭게 조명하는 계기를 마련할 것으로 기대된다.
이번 연구는 기존 생명과학의 난제에 대해 IT융합기술인 시스템생물학(Systems Biology) 연구를 통해 해답을 제시할 수 있음을 보여줬으며, 향후 생명과학 연구에 있어서 가상세포실험의 무한한 가능성을 제시했다.
曺교수는 “생명체는 복잡하게 얽혀있는 것으로 보이는 네트워크속에 이와 같이 정교한 진화적 설계원리를 간직하고 있었다”며 “이러한 규칙들은 임의로 수많은 디지털 진동자들을 만들어 인공진화를 통해 신호의 동기화 현상을 관측하였을 때에도 마찬가지로 성립된다는 흥미로운 사실을 확인했다”고 말했다.
이 연구는 교육과학기술부가 지원하는 한국연구재단 연구사업의 일환으로 수행되었으며, 연구결과는 세포생물학 분야 권위지인 세포과학저널(Journal of Cell Science) 2010년 1월 26일자 온라인판에 게재됐다.
세포생물학 실험결과만을 출판하는 이 저널에 순수 컴퓨터시뮬레이션만으로 수행된 가상세포실험 연구결과가 게재된 것은 매우 이례적인 일이다.
인터넷주소: http://jcs.biologists.org/cgi/content/abstract/jcs.060061v1
<용어설명>◯ 양성피드백(positive feedback): 서로 연결되어 있는 두 요소 사이에 어느 하나의 변화가 결과적으로 스스로를 동일한 방향으로 더욱 변화시키는 형태의 연결구조.
<사진설명>◯ 설명: A: 서로 상호작용하는 두 생체신호 진동자(oscillator)들의 예시. B: 이중활성 양성피드백으로 연결된 진동자들. C: 이중억제 양성피드백으로 연결된 진동자들. D: 연결강도에 따라 진동신호 동기화에 소요되는 시간. E: 연결강도 증가에 따라 점차 진동신호 동기화가 되어가는 모습의 예시 (좌측의 비동기화 진동신호들이 점차 우측의 동기화된 진동신호들로 변화되어 가는 과정을 나타냄).
2010.02.02 조회수 18911
매미와 개구리는 지휘자없이 어떻게 합창할까
나무위의 매미와 논두렁의 개구리는 지휘자 없이 어떻게 합창할까? 이와 관련해서, KAIST 바이오 및 뇌공학과의 조광현 교수는 생명체의 동기화된 주기적 진동신호의 생성원리를 최근 규명했다. 나무에 붙어있는 많은 반딧불들의 동시다발적인 깜빡임, 매미들의 조율된 울음소리, 뇌신경세포들간의 전기신호, 세포내 분자들의 농도변화에 이르기까지 생명체는 다양한 형태의 주기적 진동신호 교환을 통해 정보를 전달하는데, 이들은 놀랍게도 정확히 동일한 위상(phase)으로 동기화되곤 한다. 이는 마치 오케스트라에서 지휘자 없이도 모든 연주가 일정한 박자에 맞춰 이루어지는 것과 같다.
어떻게 생명체의 여러 주기적 진동신호들이 그러한 동기화를 이루는가?
우리학교 바이오및뇌공학과 조광현(曺光鉉) 교수 연구팀이 대규모 가상세포(virtual cell)실험을 통해 생명체의 다양한 주기적 진동(oscillation)신호들이 동기화(synchronization)되는 보편적인 원리를 규명했다.
曺교수팀은 이번 연구를 통해 여러 독립적인 주기적 진동신호들은 양성피드백(positive feedback)을 통해 서로의 위상에 영향을 줘 하나의 동일한 위상으로 수렴되는 현상을 밝혀냈다.
특히 양성피드백은 이중활성(double activation) 또는 이중억제(double inhibition)의 구조로 구현된다. 이중활성피드백은 연결시간지연이 짧을 때, 이중억제피드백은 연결시간지연이 길 때 보다 안정적인 신호동기화를 가능하게 했다.
또한, 노이즈(noise) 교란이 있을 때 이중활성피드백은 진동신호의 주기보다 진폭을 안정적으로 유지하는 반면 이중억제피드백은 연결강도에 불규칙한 변화가 주어졌을 때 일정한 주기와 진폭을 유지시켜줬다. 현존하는 대부분의 현상들이 이러한 원칙을 따르고 있었다.
이번에 규명된 원리는 생체내 주기적 진동신호의 동기화가 교란될 때 발생하는 뇌질환 등 여러 질병의 원인을 새롭게 조명하는 계기를 마련할 것으로 기대된다.
이번 연구는 기존 생명과학의 난제에 대해 IT융합기술인 시스템생물학(Systems Biology) 연구를 통해 해답을 제시할 수 있음을 보여줬으며, 향후 생명과학 연구에 있어서 가상세포실험의 무한한 가능성을 제시했다.
曺교수는 “생명체는 복잡하게 얽혀있는 것으로 보이는 네트워크속에 이와 같이 정교한 진화적 설계원리를 간직하고 있었다”며 “이러한 규칙들은 임의로 수많은 디지털 진동자들을 만들어 인공진화를 통해 신호의 동기화 현상을 관측하였을 때에도 마찬가지로 성립된다는 흥미로운 사실을 확인했다”고 말했다.
이 연구는 교육과학기술부가 지원하는 한국연구재단 연구사업의 일환으로 수행되었으며, 연구결과는 세포생물학 분야 권위지인 세포과학저널(Journal of Cell Science) 2010년 1월 26일자 온라인판에 게재됐다.
세포생물학 실험결과만을 출판하는 이 저널에 순수 컴퓨터시뮬레이션만으로 수행된 가상세포실험 연구결과가 게재된 것은 매우 이례적인 일이다.
인터넷주소: http://jcs.biologists.org/cgi/content/abstract/jcs.060061v1
<용어설명>◯ 양성피드백(positive feedback): 서로 연결되어 있는 두 요소 사이에 어느 하나의 변화가 결과적으로 스스로를 동일한 방향으로 더욱 변화시키는 형태의 연결구조.
<사진설명>◯ 설명: A: 서로 상호작용하는 두 생체신호 진동자(oscillator)들의 예시. B: 이중활성 양성피드백으로 연결된 진동자들. C: 이중억제 양성피드백으로 연결된 진동자들. D: 연결강도에 따라 진동신호 동기화에 소요되는 시간. E: 연결강도 증가에 따라 점차 진동신호 동기화가 되어가는 모습의 예시 (좌측의 비동기화 진동신호들이 점차 우측의 동기화된 진동신호들로 변화되어 가는 과정을 나타냄).
2010.02.02 조회수 18911