연구

우리 대학 생명화학공학과 이상엽 특훈교수와 김현욱 교수의 초세대 협업연구실 공동연구팀이 딥러닝(deep learning) 기술을 이용해 효소의 기능을 신속하고 정확하게 예측할 수 있는 컴퓨터 방법론 DeepEC를 개발했다.
공동연구팀의 류재용 박사가 1 저자로 참여한 이번 연구결과는 국제학술지 ‘미국 국립과학원 회보(PNAS)’ 6월 20일 자 온라인판에 게재됐다. (논문명 : Deep learning enables high-quality and high-throughput prediction of enzyme commission numbers)
효소는 세포 내의 생화학반응들을 촉진하는 단백질 촉매로 이들의 기능을 정확히 이해하는 것은 세포의 대사(metabolism) 과정을 이해하는 데에 매우 중요하다.
특히 효소들은 다양한 질병 발생 원리 및 산업 생명공학과 밀접한 연관이 있어 방대한 게놈 정보에서 효소들의 기능을 빠르고 정확하게 예측하는 기술은 응용기술 측면에서도 중요하다.
효소의 기능을 표기하는 시스템 중 대표적인 것이 EC 번호(enzyme commission number)이다. EC 번호는 ‘EC 3.4.11.4’처럼 효소가 매개하는 생화학반응들의 종류에 따라 총 4개의 숫자로 구성돼 있다.
중요한 것은 특정 효소에 주어진 EC 번호를 통해서 해당 효소가 어떠한 종류의 생화학반응을 매개하는지 알 수 있다는 것이다. 따라서 게놈으로부터 얻을 수 있는 효소 단백질 서열의 EC 번호를 빠르고 정확하게 예측할 수 있는 기술은 효소 및 대사 관련 문제를 해결하는 데 중요한 역할을 한다.
작년까지 여러 해에 걸쳐 EC 번호를 예측해주는 컴퓨터 방법론들이 최소 10개 이상 개발됐다. 그러나 이들 모두 예측 속도, 예측 정확성 및 예측 가능 범위 측면에서 발전 필요성이 있었다. 특히 현대 생명과학 및 생명공학에서 이뤄지는 연구의 속도와 규모를 고려했을 때 이러한 방법론의 성능은 충분하지 않았다.
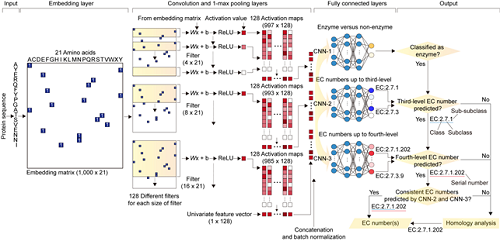
공동연구팀은 1,388,606개의 단백질 서열과 이들에게 신뢰성 있게 부여된 EC 번호를 담고 있는 바이오 빅데이터에 딥러닝 기술을 적용해 EC 번호를 빠르고 정확하게 예측할 수 있는 DeepEC를 개발했다.
DeepEC는 주어진 단백질 서열의 EC 번호를 예측하기 위해서 3개의 합성곱 신경망(Convolutional neural network)을 주요 예측기술로 사용하며, 합성곱 신경망으로 EC 번호를 예측하지 못했을 경우 서열정렬(sequence alignment)을 통해서 EC 번호를 예측한다.
연구팀은 더 나아가 단백질 서열의 도메인(domain)과 기질 결합 부위 잔기(binding site residue)에 변이를 인위적으로 주었을 때, DeepEC가 가장 민감하게 해당 변이의 영향을 감지하는 것을 확인했다.
김현욱 교수는 “DeepEC의 성능을 평가하기 위해서 이전에 발표된 5개의 대표적인 EC 번호 예측 방법론과 비교해보니 DeepEC가 가장 빠르고 정확하게 주어진 단백질의 EC 번호를 예측하는 것으로 나타났다”라며 “효소 기능 연구에 크게 이바지할 것으로 기대한다”라고 말했다.
이상엽 특훈교수는 “이번에 개발한 DeepEC를 통해서 지속해서 재생되는 게놈 및 메타 게놈에 존재하는 방대한 효소 단백질 서열의 기능을 보다 효율적이고 정확하게 알아내는 것이 가능해졌다”라고 말했다.
이번 연구는 과학기술정보통신부가 지원하는 기후변화대응기술개발사업의 바이오리파이너리를 위한 시스템대사공학 원천기술개발 과제 및 바이오·의료기술 개발 Korea Bio Grand Challenge 사업의 지원을 받아 수행됐다.
□ 그림 설명
그림1. 인공지능 기반의 DeepEC를 이용한 효소 기능 EC 번호 예측
-
행사 KAIST-머크社, 글로벌 바이오산업 선도 위한 업무협약 체결
우리 대학이 글로벌 과학기술 선도기업인 머크 라이프사이언스(대표 마티아스 하인젤, 이하 머크사)와 첨단바이오 분야 혁신과 기술 창출을 위한 업무 협약(MOU)을 29일 체결했다. 지난해 5월부터 다차원적인 혁신 프로그램을 논의해 온 두 기관은 이번 업무협약을 발판 삼아 바이오산업 혁신을 위한 도전과제를 중심으로 산학협력을 수행할 예정이다. 우리 대학은 머크사가 제공한 화학 및 바이오 분야 포트폴리오를 활용해 합성생물학, mRNA, 세포주 엔지니어링, 오가노이드 등 다양한 첨단바이오 분야의 공동연구를 진행한다. 이와 함께, 신소재공학과 및 의과학대학원과의 협력으로 익스피리언스 랩(Experience lab) 설치해 재료과학 및 생물학 분야의 후보물질 발견 및 분석 솔루션을 지원할 예정이다. 연구진 역량 강화를 위한 프로그램도 제공된다. 대학원생을 위한 장학 제도를 시행하고 교수진을 위한 연구 분야 포상도 제정된다. 또한, 머크사가 개최하는 세계적인 학술행사 및 교육
2024-05-29 -
행사 KAIST 연구자들의 축제, 2024 리서치데이 개최
우리 대학이 '2024년 KAIST 리서치데이(Research Day)'를 21일 대전 본원 학술문화관(E9)에서 개최했다. 2016년부터 매년 개최하고 있는 'KAIST 리서치데이'는 탁월한 성과를 배출한 연구자를 포상하고 우수 연구성과를 공유해 연구개발(R&D) 정보를 교류하는 자리다. 최고 연구상인 '연구대상'은 방효충(항공우주공학과) 교수가 수상했다. 방 교수는 2001년 부임 이래 다양한 형태의 자율화 드론과 인공위성 자세제어기술을 연구해 왔다. 이를 통해, 초소형위성을 세 차례 우주로 발사하는 데 성공하고, 항공우주 연구와 교육을 선도한 업적을 높이 평가받았다. 이날 행사에서 방 교수는 수상을 기념해 '소형 드론의 자율화와 인공위성 유도․항법․제어 시스템 연구'를 주제로 강연한다. 소형 드론 기반의 자율 비행과 인공지능 기술을 결합한 자율화 연구가 민간 및 국방 분야에 적용된 사례와 초소형위성 시스템의 기술 자립화를 위한 연구 활동을 소개할 예정이다.방
2024-05-21 -
행사 네이버·인텔과 AI 반도체 신 생태계 조성 공동 협력
챗GPT가 촉발한 생성형 인공지능(AI)*이 세계적으로 열풍을 일으키는 가운데 새로운 인공지능 반도체의 생태계 구축을 위해 KAIST(총장 이광형)가 네이버(NAVER) 및 인텔(intel)과 손잡고 상호 보유 중인 역량과 강점을 한 곳에 집중한 ‘NAVER · intel · KAIST AI 공동연구센터(NIK AI Research Center)’를 설립한다. 업계에서는 이들 세 기관의 전략적인 제휴가 인공지능 반도체·인공지능 서버와 데이터센터의 운영에 필요한 오픈소스용 소프트웨어 개발 등 인공지능 분야에서 각자 보유하고 있는 하드웨어 및 소프트웨어 기술과 역량을 융합해서 새로운 인공지능 반도체 생태계를 구축하는 한편 시장과 기술 주도권 확보를 위해 선제적인 도전에 나선 것으로 보고 있다. 특히 첨단 반도체 CPU 설계부터 파운드리까지 하는 세계적인 반도체 기업 인텔이 기존의 중앙처리장치(CPU)를 넘어 인공지능 반
2024-04-30 -
행사 KAIST-서울시, 인공지능 안부 확인 서비스 개발
우리 대학이 서울시 · 서울시복지재단과 'AI안부확인서비스 데이터 활용연구를 위한 업무협약'을 29일 서면 교환 방식으로 체결한다. 이번 업무협약은 서울시가 2022년 10월부터 제공해 온 인공지능을 활용한 안부 확인 서비스를 고도화하기 위해 추진된다. 안부 대상자의 심리상태와 고립 위험 신호를 탐지할 수 있는 대화형 'AI안부확인서비스'를 개발해 고립가구 돌봄서비스에 활용하는 것이 목표다. 우리 대학은 이번 연구를 위해 인공지능-사회복지-HCI(인간컴퓨터상호작용)를 아우르는 융합연구팀을 구성했다. 차미영 전산학부 교수와 최문정 과학기술정책대학원 교수 및 IBS 수리 및 계산과학 연구단 데이터사이언스 그룹 진효진 박사가 참여한다. 연구팀은 서울시가 'AI안부확인서비스'를 운영하며 축적해 온 대화 데이터를 제공받아 ▴고립 위험 대상자를 찾아낼 수 있는 지표 개발 ▴고립감 해소 및 심리적 안정을 위한 시나리오 개발과 이를 반영한 대화형 인공지능 개발 ▴고령자 및
2024-03-29 -
행사 인공지능·우주·수리 ′초세대 협업연구실′ 개소
우리 대학이 '초세대 협업연구실'을 추가 개소하고 27일 오전 현판식을 개최했다. 권인소 전기및전자공학부 교수의 '비전중심 범용인공지능 연구실', 김천곤 항공우주공학과 교수의 '우주·극한 환경 재료 및 차세대 공정 연구실', 변재형 수리과학과 교수의 '편미분방정식 통합 연구실'이 새롭게 문을 연다. 초세대 협업연구실은 은퇴를 앞둔 교수가 오랜 시간 축적해 온 학문의 성과와 노하우를 후배 교수와 협업하며 이어가는 우리 대학의 독자적인 연구제도다. 2018년 도입한 이후 지난해 말까지 7개 연구실을 운영하고 있으며, 이번 추가 개소로 총 10개의 초세대 협업연구실을 보유하게 됐다. 특히 권인소, 김천곤 책임교수는 65세 은퇴 후 70세까지 강의와 연구 논문 지도를 이어가는 정년후 교수의 신분으로 초세대 협업연구실을 개소했다. 권인소 교수가 책임교수를 맡은 '비전중심 범용인공지능 연구실'은 같은 학과 김준모 교수 협업하고 딥러닝 분야의 신임 교수가 추후 합류
2024-02-27