-
 뉴로모픽 신경망으로 컴퓨팅 난제 해결하다
우리 연구진이 현재 반도체 산업체에서 사용되는 실리콘 소재 및 공정만을 사용해 초소형 진동 신경망을 구축하여 경계선 인식 기능을 구현했으며 난제 중 하나인 그래프 색칠 문제*를 해결했다.
*그래프 색칠 문제: 그래프 이론에서 사용되는 용어로, 그래프의 각 정점에 서로 다른 색을 할당해야 하며, 이러한 색깔 구분 문제는 방송국 주파수가 겹쳐 난시청 지역이 발생하지 않도록 주파수를 할당하는 문제 등과도 유사해 다양하게 응용되고 있음
우리 대학 전기및전자공학부 최양규 교수 연구팀이 실리콘 바이리스터 소자로 생물학적 뉴런의 상호작용을 모방한 뉴로모픽 진동 신경망을 개발했다고 3일 밝혔다.
빅데이터 시대가 도래하면서 인공지능 기술이 예전과 비교할 수 없을 만큼 비약적으로 발전하고 있다. 인간의 뇌 기능을 모사하는 뉴로모픽 컴퓨팅 중 하나인 상호 간 결합된 진동 신경망(oscillatory neural network)은 뉴런의 상호작용을 모방한 인공 신경망이다. 진동 신경망은 기본단위에 해당하는 진동자의 연결 동작을 이용하며 신호의 크기가 아닌 진동을 이용해 연산을 수행하므로 소모 전력 측면에서 이점을 가지고 있다.
연구팀은 실리콘 기반 진동자를 이용해 진동 신경망을 개발했다. 축전기를 이용해 두 개 이상의 실리콘 진동자를 연결하면, 각각의 진동 신호가 상호작용해 시간이 경과하면서 동기화(synchronization) 된다. 연구팀은 진동 신경망으로 영상 처리에 사용되는 경계선 인식(edge detection) 기능을 구현했으며 난제 중 하나인 그래프 색칠 문제(vertex coloring problem)를 해결했다.
또한 이번 연구는 제조 관점에서, 복잡한 회로나 기존 반도체 공정과 호환성이 낮은 소재 및 구조 대신, 현재 반도체 산업체에서 사용되는 실리콘 관련 소재 및 공정만으로 진동 신경망을 구축했기 때문에, 양산에 바로 적용 가능하다는 장점이 있다.
연구를 주도한 윤성윤 박사과정, 서강대학교 한준규 교수는 "개발된 진동 신경망은 복잡한 컴퓨팅 난제를 계산할 수 있는 뉴로모픽 컴퓨팅 하드웨어로, 자원 분배, 신약 개발, 반도체 회로 설계 및 스케줄링 등에 유용하게 사용될 수 있을 것으로 기대된다ˮ고 연구의 의의를 설명했다.
윤성윤 박사과정과 한준규 교수가 공동 제1 저자로 참여한 이번 연구는 나노과학 분야 저명 국제 학술지 ‘나노 레터스(Nano Letters)’에 2024년 3월 24권 9호에 출판되었으며, 추가 표지 논문(Supplementary Cover)으로 선정됐다.
(논문명 : A Nanoscale Bistable Resistor for an Oscillatory Neural Network)
(https://pubs.acs.org/doi/full/10.1021/acs.nanolett.3c04539).
한편 이번 연구는 한국연구재단 차세대지능형반도체기술개발사업 및 국가반도체연구실지원핵심기술개발사업의 지원을 받아 수행됐다.
뉴로모픽 신경망으로 컴퓨팅 난제 해결하다
우리 연구진이 현재 반도체 산업체에서 사용되는 실리콘 소재 및 공정만을 사용해 초소형 진동 신경망을 구축하여 경계선 인식 기능을 구현했으며 난제 중 하나인 그래프 색칠 문제*를 해결했다.
*그래프 색칠 문제: 그래프 이론에서 사용되는 용어로, 그래프의 각 정점에 서로 다른 색을 할당해야 하며, 이러한 색깔 구분 문제는 방송국 주파수가 겹쳐 난시청 지역이 발생하지 않도록 주파수를 할당하는 문제 등과도 유사해 다양하게 응용되고 있음
우리 대학 전기및전자공학부 최양규 교수 연구팀이 실리콘 바이리스터 소자로 생물학적 뉴런의 상호작용을 모방한 뉴로모픽 진동 신경망을 개발했다고 3일 밝혔다.
빅데이터 시대가 도래하면서 인공지능 기술이 예전과 비교할 수 없을 만큼 비약적으로 발전하고 있다. 인간의 뇌 기능을 모사하는 뉴로모픽 컴퓨팅 중 하나인 상호 간 결합된 진동 신경망(oscillatory neural network)은 뉴런의 상호작용을 모방한 인공 신경망이다. 진동 신경망은 기본단위에 해당하는 진동자의 연결 동작을 이용하며 신호의 크기가 아닌 진동을 이용해 연산을 수행하므로 소모 전력 측면에서 이점을 가지고 있다.
연구팀은 실리콘 기반 진동자를 이용해 진동 신경망을 개발했다. 축전기를 이용해 두 개 이상의 실리콘 진동자를 연결하면, 각각의 진동 신호가 상호작용해 시간이 경과하면서 동기화(synchronization) 된다. 연구팀은 진동 신경망으로 영상 처리에 사용되는 경계선 인식(edge detection) 기능을 구현했으며 난제 중 하나인 그래프 색칠 문제(vertex coloring problem)를 해결했다.
또한 이번 연구는 제조 관점에서, 복잡한 회로나 기존 반도체 공정과 호환성이 낮은 소재 및 구조 대신, 현재 반도체 산업체에서 사용되는 실리콘 관련 소재 및 공정만으로 진동 신경망을 구축했기 때문에, 양산에 바로 적용 가능하다는 장점이 있다.
연구를 주도한 윤성윤 박사과정, 서강대학교 한준규 교수는 "개발된 진동 신경망은 복잡한 컴퓨팅 난제를 계산할 수 있는 뉴로모픽 컴퓨팅 하드웨어로, 자원 분배, 신약 개발, 반도체 회로 설계 및 스케줄링 등에 유용하게 사용될 수 있을 것으로 기대된다ˮ고 연구의 의의를 설명했다.
윤성윤 박사과정과 한준규 교수가 공동 제1 저자로 참여한 이번 연구는 나노과학 분야 저명 국제 학술지 ‘나노 레터스(Nano Letters)’에 2024년 3월 24권 9호에 출판되었으며, 추가 표지 논문(Supplementary Cover)으로 선정됐다.
(논문명 : A Nanoscale Bistable Resistor for an Oscillatory Neural Network)
(https://pubs.acs.org/doi/full/10.1021/acs.nanolett.3c04539).
한편 이번 연구는 한국연구재단 차세대지능형반도체기술개발사업 및 국가반도체연구실지원핵심기술개발사업의 지원을 받아 수행됐다.
2024.04.03
조회수 844
-
 반도체가 곤충처럼 사물 움직임 감지한다
곤충의 시신경계를 모방하여 초고속, 저전력 동작이 가능한 신개념 ‘지능형 센서’ 반도체의 개발로 다양한 혁신적 기술로 확장가능한 기술이 개발되었다. 이 기술은 교통, 안전, 보안 시스템 등 다양한 분야에 응용되어 산업과 사회에 기여할 것으로 보인다.
우리 대학 신소재공학과 김경민 교수 연구팀이 다양한 멤리스터* 소자를 융합해 곤충의 시신경에서의 시각 지능*을 모사하는 지능형 동작인식 소자를 개발하는데 성공했다고 19일 밝혔다.
*멤리스터 (Memristor): 메모리(Memory)와 저항(Resistor)의 합성어로, 입력 신호에 따라 소자의 저항 상태가 변하는 전자소자.
*시각 지능 (Visual Intelligence): 시신경 내에서 시각 정보를 해석하고 연산을 수행하는 기능.
최근 인공지능(AI) 기술의 발전과 함께, 비전 시스템은 이미지 인식, 객체 탐지 및 동작 분석과 같은 다양한 작업에서 AI를 활용해 핵심적인 역할을 수행하고 있다. 하지만 기존 비전 시스템은 이미지 센서에서 수신된 신호를 복잡한 알고리즘을 이용해 물체와 그 동작을 인식하는 것이 일반적이다. 이러한 방식은 상당한 양의 데이터 트래픽과 높은 전력 소모가 필요하여 모바일 또는 사물인터넷 장치에 적용되기 어렵다.
한편, 곤충은 기본 동작 감지기(Elementary Motion Detector) 라는 시신경 회로를 통해 시각 정보를 효과적으로 처리해 물체를 탐지하고 그 동작을 인식하는데 탁월한 능력을 보인다. <그림1> 이를 구현하는 데 있어 기존 실리콘 집적회로(CMOS) 기술에서는 복잡한 회로가 요구되기 때문에, 실제 소자로 제작하기 어려운 한계가 있었다.
김경민 교수 연구팀은 다양한 기능의 멤리스터 소자들을 집적하여 고효율⋅초고속 동작 인식이 가능한 지능형 동작인식 소자를 개발했다. 동작인식 소자는 자체 개발한 두 종류의 멤리스터 소자와 저항 만으로 구성된 단순한 구조를 가지고 있다. 두 종류의 서로 다른 멤리스터는 각각 신호 지연 기능과 신호 통합 및 발화 기능을 수행하며, 이를 통해 곤충의 시신경을 직접 모사하여 사물의 움직임을 판단할 수 있음을 확인했다. <그림2>
연구팀은 개발된 동작인식 소자의 실질적인 활용에 대한 가능성을 입증하기 위해 차량 경로를 예측하는 뉴로모픽 컴퓨팅 시스템을 설계하였으며, 여기에 개발한 동작인식 소자를 적용하였다. <그림3> 그 결과 기존 기술 대비 에너지 소비를 92.9 % 감소하여 더 정확히 사물의 움직임을 예측할 수 있음을 검증하였다.
신소재공학과 김경민 교수는 “곤충은 매우 간단한 시각 지능을 활용해 놀랍도록 민첩하게 물체의 동작을 인지하는데, 이번 연구는 신경의 기능을 재현할 수 있는 멤리스터 소자를 활용해 이를 구현할 수 있었다는 점에 큰 의의가 있다”며, “최근 AI가 탑재된 휴대폰과 같이 에지(edge)형 인공지능 소자의 중요성이 매우 커지고 있는데, 이 연구는 동작 인식을 위한 효율적인 비전 시스템 구현에 기여할 수 있어, 향후 자율주행 자동차, 차량 운송 시스템, 로봇, 머신 비전 등과 같은 다양한 분야에 적용될 수 있을 것으로 기대된다”고 밝혔다.
이번 연구는 신소재공학과 송한찬 박사과정, 이민구 박사과정 학생이 공동 제1 저자로 참여했으며, 국제 학술지 ‘어드밴스드 머티리얼즈(Advanced Materials, IF: 29.4)’에 지난 1월 29일 字 온라인 게재됐다.
한편 이번 연구는 한국연구재단 중견연구사업, 차세대지능형반도체기술개발사업, PIM인공지능반도체핵심기술개발사업, 나노종합기술원 및 KAIST 도약연구사업의 지원을 받아 수행됐다. (논문명: Fully Memristive Elementary Motion Detectors for A Maneuver Prediction, 논문링크: https://doi.org/10.1002/adma.202309708)
반도체가 곤충처럼 사물 움직임 감지한다
곤충의 시신경계를 모방하여 초고속, 저전력 동작이 가능한 신개념 ‘지능형 센서’ 반도체의 개발로 다양한 혁신적 기술로 확장가능한 기술이 개발되었다. 이 기술은 교통, 안전, 보안 시스템 등 다양한 분야에 응용되어 산업과 사회에 기여할 것으로 보인다.
우리 대학 신소재공학과 김경민 교수 연구팀이 다양한 멤리스터* 소자를 융합해 곤충의 시신경에서의 시각 지능*을 모사하는 지능형 동작인식 소자를 개발하는데 성공했다고 19일 밝혔다.
*멤리스터 (Memristor): 메모리(Memory)와 저항(Resistor)의 합성어로, 입력 신호에 따라 소자의 저항 상태가 변하는 전자소자.
*시각 지능 (Visual Intelligence): 시신경 내에서 시각 정보를 해석하고 연산을 수행하는 기능.
최근 인공지능(AI) 기술의 발전과 함께, 비전 시스템은 이미지 인식, 객체 탐지 및 동작 분석과 같은 다양한 작업에서 AI를 활용해 핵심적인 역할을 수행하고 있다. 하지만 기존 비전 시스템은 이미지 센서에서 수신된 신호를 복잡한 알고리즘을 이용해 물체와 그 동작을 인식하는 것이 일반적이다. 이러한 방식은 상당한 양의 데이터 트래픽과 높은 전력 소모가 필요하여 모바일 또는 사물인터넷 장치에 적용되기 어렵다.
한편, 곤충은 기본 동작 감지기(Elementary Motion Detector) 라는 시신경 회로를 통해 시각 정보를 효과적으로 처리해 물체를 탐지하고 그 동작을 인식하는데 탁월한 능력을 보인다. <그림1> 이를 구현하는 데 있어 기존 실리콘 집적회로(CMOS) 기술에서는 복잡한 회로가 요구되기 때문에, 실제 소자로 제작하기 어려운 한계가 있었다.
김경민 교수 연구팀은 다양한 기능의 멤리스터 소자들을 집적하여 고효율⋅초고속 동작 인식이 가능한 지능형 동작인식 소자를 개발했다. 동작인식 소자는 자체 개발한 두 종류의 멤리스터 소자와 저항 만으로 구성된 단순한 구조를 가지고 있다. 두 종류의 서로 다른 멤리스터는 각각 신호 지연 기능과 신호 통합 및 발화 기능을 수행하며, 이를 통해 곤충의 시신경을 직접 모사하여 사물의 움직임을 판단할 수 있음을 확인했다. <그림2>
연구팀은 개발된 동작인식 소자의 실질적인 활용에 대한 가능성을 입증하기 위해 차량 경로를 예측하는 뉴로모픽 컴퓨팅 시스템을 설계하였으며, 여기에 개발한 동작인식 소자를 적용하였다. <그림3> 그 결과 기존 기술 대비 에너지 소비를 92.9 % 감소하여 더 정확히 사물의 움직임을 예측할 수 있음을 검증하였다.
신소재공학과 김경민 교수는 “곤충은 매우 간단한 시각 지능을 활용해 놀랍도록 민첩하게 물체의 동작을 인지하는데, 이번 연구는 신경의 기능을 재현할 수 있는 멤리스터 소자를 활용해 이를 구현할 수 있었다는 점에 큰 의의가 있다”며, “최근 AI가 탑재된 휴대폰과 같이 에지(edge)형 인공지능 소자의 중요성이 매우 커지고 있는데, 이 연구는 동작 인식을 위한 효율적인 비전 시스템 구현에 기여할 수 있어, 향후 자율주행 자동차, 차량 운송 시스템, 로봇, 머신 비전 등과 같은 다양한 분야에 적용될 수 있을 것으로 기대된다”고 밝혔다.
이번 연구는 신소재공학과 송한찬 박사과정, 이민구 박사과정 학생이 공동 제1 저자로 참여했으며, 국제 학술지 ‘어드밴스드 머티리얼즈(Advanced Materials, IF: 29.4)’에 지난 1월 29일 字 온라인 게재됐다.
한편 이번 연구는 한국연구재단 중견연구사업, 차세대지능형반도체기술개발사업, PIM인공지능반도체핵심기술개발사업, 나노종합기술원 및 KAIST 도약연구사업의 지원을 받아 수행됐다. (논문명: Fully Memristive Elementary Motion Detectors for A Maneuver Prediction, 논문링크: https://doi.org/10.1002/adma.202309708)
2024.02.19
조회수 1505
-
 차세대 XR 초정밀 위치 인식기술 최초 개발
초정밀 위치 인식기술로 사물인터넷 기기와 로봇의 미세한 움직임을 조종하고, 나아가서는 초실감형 XR 및 초정밀 스마트 팩토리 등 가상 세계에서 현실과 연결을 시키게 하는 인식기술을 세계 최초로 개발해서 화제다.
우리 대학 전기및전자공학부 김성민 교수 연구팀이 무전원 태그를 통해 세계 최초로 160m 장거리에서 7mm(5m 단거리 0.35mm)의 정확도와 1,000개 이상의 위치를 동시 인식하는 초정밀·대규모 사물인터넷(IoT) 위치인식 시스템을 개발했다고 8일 밝혔다.
연구진이 최초 개발한 무선 태그는, 그 신호가 방해 신호와 주파수 영역에서 완전히 분리되어 신호의 질을 100만 배 이상 향상시킨다. 이를 이용하여 초정밀 위치 인식이 가능해지는 원리다. 해당 기술을 접목하면 XR에서 다량의 사물인터넷을 손가락의 미세한 움직임만으로 쉽게 제어할 수 있는 등, 몰입감을 크게 높일 수 있다. 또한 1,000개 이상의 태그를 0.5초 이하에 동시 인식할 수 있어, 수많은 기기를 실시간 조작할 수 있다.
이 기술은 현존하는 실내외 위치인식 기술 중 작동 범위, 정확도 및 규모에서 성능이 월등하여 그 의미가 깊다. 특히, 최신 실내 측위 기술인 차세대무선기술(UWB, Ultra Wide Band)에 비해 300배의 정확도, 10배의 탐지 거리, 100배의 확장성을 갖는다. 즉, 현재에 비해 훨씬 많은 기기를 정밀하게 다룰 수 있음을 의미한다. 또한, 실외 측위에 한정되는 GPS 위치 인식 기술과 달리 다양한 실내외 환경에서 활용될 수 있다.
본 기술의 태그는 스스로 무선 신호를 생성하는 대신, 주변의 신호를 반사하여 통신한다. 마치 거울과 같은 원리로, 신호 생성에 필요한 전력을 아낄 수 있어 초저전력으로 동작한다. 이에 태양전지 등 무전원으로 동작하거나 코인 전지 하나로 40년 이상 구동할 수 있어, 대량 운용에 적합하다.
전기및전자공학부 배강민 박사과정과 문한결 박사과정이 공동 주 저자로 참여한 이번 연구는 모바일 시스템 분야의 최고 권위 국제 학술대회인 `ACM 모비시스(ACM MobiSys)' 2023에 지난 6월 발표됐다. (논문명: Hawkeye: Hectometer-range Subcentimeter Localization for Large-scale mmWave Backscatter)
김성민 교수는 “이번 성과를 통해 스마트팩토리 등 산업체를 넘어, XR(확장현실) 등 민간에서도 포괄적으로 사용가능한 IoT(사물인터넷) 상호적용 기술로, 전방위적인 위치인식 기술의 보급을 가능하게 할 것으로 기대된다”고 말했다.
한편 이번 연구는 삼성미래기술육성사업과 정보통신기획평가원의 지원을 받아 수행됐다.
차세대 XR 초정밀 위치 인식기술 최초 개발
초정밀 위치 인식기술로 사물인터넷 기기와 로봇의 미세한 움직임을 조종하고, 나아가서는 초실감형 XR 및 초정밀 스마트 팩토리 등 가상 세계에서 현실과 연결을 시키게 하는 인식기술을 세계 최초로 개발해서 화제다.
우리 대학 전기및전자공학부 김성민 교수 연구팀이 무전원 태그를 통해 세계 최초로 160m 장거리에서 7mm(5m 단거리 0.35mm)의 정확도와 1,000개 이상의 위치를 동시 인식하는 초정밀·대규모 사물인터넷(IoT) 위치인식 시스템을 개발했다고 8일 밝혔다.
연구진이 최초 개발한 무선 태그는, 그 신호가 방해 신호와 주파수 영역에서 완전히 분리되어 신호의 질을 100만 배 이상 향상시킨다. 이를 이용하여 초정밀 위치 인식이 가능해지는 원리다. 해당 기술을 접목하면 XR에서 다량의 사물인터넷을 손가락의 미세한 움직임만으로 쉽게 제어할 수 있는 등, 몰입감을 크게 높일 수 있다. 또한 1,000개 이상의 태그를 0.5초 이하에 동시 인식할 수 있어, 수많은 기기를 실시간 조작할 수 있다.
이 기술은 현존하는 실내외 위치인식 기술 중 작동 범위, 정확도 및 규모에서 성능이 월등하여 그 의미가 깊다. 특히, 최신 실내 측위 기술인 차세대무선기술(UWB, Ultra Wide Band)에 비해 300배의 정확도, 10배의 탐지 거리, 100배의 확장성을 갖는다. 즉, 현재에 비해 훨씬 많은 기기를 정밀하게 다룰 수 있음을 의미한다. 또한, 실외 측위에 한정되는 GPS 위치 인식 기술과 달리 다양한 실내외 환경에서 활용될 수 있다.
본 기술의 태그는 스스로 무선 신호를 생성하는 대신, 주변의 신호를 반사하여 통신한다. 마치 거울과 같은 원리로, 신호 생성에 필요한 전력을 아낄 수 있어 초저전력으로 동작한다. 이에 태양전지 등 무전원으로 동작하거나 코인 전지 하나로 40년 이상 구동할 수 있어, 대량 운용에 적합하다.
전기및전자공학부 배강민 박사과정과 문한결 박사과정이 공동 주 저자로 참여한 이번 연구는 모바일 시스템 분야의 최고 권위 국제 학술대회인 `ACM 모비시스(ACM MobiSys)' 2023에 지난 6월 발표됐다. (논문명: Hawkeye: Hectometer-range Subcentimeter Localization for Large-scale mmWave Backscatter)
김성민 교수는 “이번 성과를 통해 스마트팩토리 등 산업체를 넘어, XR(확장현실) 등 민간에서도 포괄적으로 사용가능한 IoT(사물인터넷) 상호적용 기술로, 전방위적인 위치인식 기술의 보급을 가능하게 할 것으로 기대된다”고 말했다.
한편 이번 연구는 삼성미래기술육성사업과 정보통신기획평가원의 지원을 받아 수행됐다.
2023.08.08
조회수 2070
-
 사진에서 3차원 정보를 추론하는 인공지능 반도체 IP(지식재산권) 세계 최초 개발
우리 대학 전기및전자공학부 유회준 교수가 이끄는 PIM 반도체 설계 연구센터(AI-PIM)가 유수 학계에서 인정한 5종의 최첨단 인공지능 반도체 IP(지식재산권)를 개발했다고 29일 밝혔다.
대표적으로 심층신경망 추론 기술 및 센서 퓨전* 기술을 통해 사진으로부터 3차원 공간정보 추출하고 물체를 인식해 처리하는 인공지능(AI) 칩은 KAIST에서 세계 최초로 개발해 SRAM PIM** 시스템에 필요한 기술을 IP(지식재산권)화 한 것이다.
* 센서 퓨전 : 카메라, 거리센서 등의 각종 센서로부터 얻은 데이터를 결합하여보다 정확한 데이터를 얻는 방식
** SRAM PIM : 기존 메모리 SRAM과 DRAM 중 SRAM에 연산기를 결합한 PIM반도체
이 IP는 올해 2월 20일부터 28일까지 개최된 국제고체회로설계학회(ISSCC)에서 현장 시연을 통해 많은 주목을 받았으며, 이를 누구라도 편리하게 활용할 수 있도록 한 것이다. (웹사이트 : www.ai-pim.org)
KAIST PIM 반도체 설계연구센터는 해당 IP를 포함해 ADC*, PLL** 등 총 5가지의 PIM IP를 확보했으며, 지난 28일 웹사이트를 오픈해 연구자들이 공유할 수 있는 환경을 제공하고 있다.
* ADC(Analog to Digital Converter) : 아날로그 데이터를 디지털 데이터로 변환시키는 회로
** PLL(Phase-Locked Loop) : 내부 신호의 위상과 외부 신호의 위상을 동기화할 수 있도록 설계된 회로
기존 물체 인식 인공지능 반도체는 사진과 같은 2차원 정보를 인식하는 `사진인식기술'에 불과하다. 하지만 현실 세계의 물체들은 3차원 구조물이기 때문에 3차원 공간정보를 활용해야만 정확한 `물체인식'이 가능하다.
3차원 공간정보는 사진과 같은 2차원 정보에 거리정보를 포함시켜 실제 3차원 공간을 표현한 것으로, 3차원 공간정보에 물체를 식별해 해당 물체의 위치 및 각도를 추적하는 3차원 물체인식 기술이다. 이는 자율주행, 자동화 기술, 개인용 증강현실 (AR)과 가상현실(VR) 등과 같은 3D 어플리케이션에서 사용하는 핵심기술이다.
기존 ToF 센서*를 활용해 센서 뷰 내에 있는 모든 물체에 대한 정밀한 3차원 정보를 추출하는 것은 전력 소모가 매우 크기 때문에 배터리 기반 모바일 장치(스마트폰, 태블릿 등)에서는 사용하기 어렵다.
* ToF 센서 : 3차원 공간정보를 추출하는 Time-of-Flight 센서로, 레이저를 방출하고 반사된 레이저가 검출되는 시간을 측정하여 거리를 계산, 대표적인 센서로 3D 라이다 (LiDAR) 센서가 있음
또한, ToF 센서는 특정 측정 환경에서 3차원 정보가 손실되는 문제와 데이터 전처리 과정에 많은 시간이 소요된다는 문제점이 있다.
3차원 물체인식 기술은 데이터가 복잡해 기존 인공지능 2차원 사진인식 가속 프로세서로 처리하기 어렵다. 이는 3차원 포인트 클라우드 데이터를 어떻게 선택하고 그룹화하느냐에 따라 메모리 접근량이 달라진다.
따라서 3차원 포인트 클라우드 기반 인공지능 추론은 연산 능력이 제한적이고 메모리가 작은 모바일 장치에서는 소프트웨어만으로 구현할 수 없었다.
이에 연구팀은 카메라와 저전력 거리센서 (64픽셀)를 사용하여 3차원 공간정보를 생성했고, 모바일에서도 3차원 어플리케이션 구현이 가능한 반도체 (DSPU: Depth Signal Processing Unit)를 개발함으로써 인공지능 반도체의 활용범위를 넓혔다.
모바일 기기에서 저전력 센서를 활용한 3차원 정보 처리 시스템을 구동하면서, 실시간 심층신경망 추론과 센서 퓨전 기술을 가속하기 위해서는 다양한 핵심기술이 필요하다. 인공지능 핵심기술이 적용된 DSPU는 단순 ToF센서에 의존했던 3차원 물체인식 가속기 반도체 대비 63.4% 낮춘 전력 소모와 53.6% 낮춘 지연시간을 달성했다.
PIM반도체 설계연구센터(AI-PIM)의 소장인 유회준 교수는 “이번 연구는 저가의 거리센서와 카메라를 융합해 3차원 데이터 처리를 가능하게 한 인공지능 반도체를 IP화했다는 점에서 의미가 크며, 모바일 기기에서 인공지능 활용 영역을 크게 넓혀 다양한 분야에 응용 및 기술이전을 기대하고 있다”고 연구의 의의를 설명했다.
한편, 이번 연구는 과학기술정보통신부와 정보통신기획평가원의 PIM인공지능반도체핵심기술개발사업을 통해 개발되었으며, 이와 관련해 PIM 반도체 관련 기업과 연구기관에 개발된 IP들의 기술이전 및 활용을 돕고 있다.
사진에서 3차원 정보를 추론하는 인공지능 반도체 IP(지식재산권) 세계 최초 개발
우리 대학 전기및전자공학부 유회준 교수가 이끄는 PIM 반도체 설계 연구센터(AI-PIM)가 유수 학계에서 인정한 5종의 최첨단 인공지능 반도체 IP(지식재산권)를 개발했다고 29일 밝혔다.
대표적으로 심층신경망 추론 기술 및 센서 퓨전* 기술을 통해 사진으로부터 3차원 공간정보 추출하고 물체를 인식해 처리하는 인공지능(AI) 칩은 KAIST에서 세계 최초로 개발해 SRAM PIM** 시스템에 필요한 기술을 IP(지식재산권)화 한 것이다.
* 센서 퓨전 : 카메라, 거리센서 등의 각종 센서로부터 얻은 데이터를 결합하여보다 정확한 데이터를 얻는 방식
** SRAM PIM : 기존 메모리 SRAM과 DRAM 중 SRAM에 연산기를 결합한 PIM반도체
이 IP는 올해 2월 20일부터 28일까지 개최된 국제고체회로설계학회(ISSCC)에서 현장 시연을 통해 많은 주목을 받았으며, 이를 누구라도 편리하게 활용할 수 있도록 한 것이다. (웹사이트 : www.ai-pim.org)
KAIST PIM 반도체 설계연구센터는 해당 IP를 포함해 ADC*, PLL** 등 총 5가지의 PIM IP를 확보했으며, 지난 28일 웹사이트를 오픈해 연구자들이 공유할 수 있는 환경을 제공하고 있다.
* ADC(Analog to Digital Converter) : 아날로그 데이터를 디지털 데이터로 변환시키는 회로
** PLL(Phase-Locked Loop) : 내부 신호의 위상과 외부 신호의 위상을 동기화할 수 있도록 설계된 회로
기존 물체 인식 인공지능 반도체는 사진과 같은 2차원 정보를 인식하는 `사진인식기술'에 불과하다. 하지만 현실 세계의 물체들은 3차원 구조물이기 때문에 3차원 공간정보를 활용해야만 정확한 `물체인식'이 가능하다.
3차원 공간정보는 사진과 같은 2차원 정보에 거리정보를 포함시켜 실제 3차원 공간을 표현한 것으로, 3차원 공간정보에 물체를 식별해 해당 물체의 위치 및 각도를 추적하는 3차원 물체인식 기술이다. 이는 자율주행, 자동화 기술, 개인용 증강현실 (AR)과 가상현실(VR) 등과 같은 3D 어플리케이션에서 사용하는 핵심기술이다.
기존 ToF 센서*를 활용해 센서 뷰 내에 있는 모든 물체에 대한 정밀한 3차원 정보를 추출하는 것은 전력 소모가 매우 크기 때문에 배터리 기반 모바일 장치(스마트폰, 태블릿 등)에서는 사용하기 어렵다.
* ToF 센서 : 3차원 공간정보를 추출하는 Time-of-Flight 센서로, 레이저를 방출하고 반사된 레이저가 검출되는 시간을 측정하여 거리를 계산, 대표적인 센서로 3D 라이다 (LiDAR) 센서가 있음
또한, ToF 센서는 특정 측정 환경에서 3차원 정보가 손실되는 문제와 데이터 전처리 과정에 많은 시간이 소요된다는 문제점이 있다.
3차원 물체인식 기술은 데이터가 복잡해 기존 인공지능 2차원 사진인식 가속 프로세서로 처리하기 어렵다. 이는 3차원 포인트 클라우드 데이터를 어떻게 선택하고 그룹화하느냐에 따라 메모리 접근량이 달라진다.
따라서 3차원 포인트 클라우드 기반 인공지능 추론은 연산 능력이 제한적이고 메모리가 작은 모바일 장치에서는 소프트웨어만으로 구현할 수 없었다.
이에 연구팀은 카메라와 저전력 거리센서 (64픽셀)를 사용하여 3차원 공간정보를 생성했고, 모바일에서도 3차원 어플리케이션 구현이 가능한 반도체 (DSPU: Depth Signal Processing Unit)를 개발함으로써 인공지능 반도체의 활용범위를 넓혔다.
모바일 기기에서 저전력 센서를 활용한 3차원 정보 처리 시스템을 구동하면서, 실시간 심층신경망 추론과 센서 퓨전 기술을 가속하기 위해서는 다양한 핵심기술이 필요하다. 인공지능 핵심기술이 적용된 DSPU는 단순 ToF센서에 의존했던 3차원 물체인식 가속기 반도체 대비 63.4% 낮춘 전력 소모와 53.6% 낮춘 지연시간을 달성했다.
PIM반도체 설계연구센터(AI-PIM)의 소장인 유회준 교수는 “이번 연구는 저가의 거리센서와 카메라를 융합해 3차원 데이터 처리를 가능하게 한 인공지능 반도체를 IP화했다는 점에서 의미가 크며, 모바일 기기에서 인공지능 활용 영역을 크게 넓혀 다양한 분야에 응용 및 기술이전을 기대하고 있다”고 연구의 의의를 설명했다.
한편, 이번 연구는 과학기술정보통신부와 정보통신기획평가원의 PIM인공지능반도체핵심기술개발사업을 통해 개발되었으며, 이와 관련해 PIM 반도체 관련 기업과 연구기관에 개발된 IP들의 기술이전 및 활용을 돕고 있다.
2022.12.29
조회수 3826
-
 인공지능으로 정확한 세포 이미지 분석..세계 AI 생명과학 분야 대회 우승
우리 대학 김재철AI대학원 윤세영 교수 연구팀이 세계 최고 수준의 인공지능(AI) 학회인 `뉴립스(NeurIPS, 신경정보처리시스템학회) 2022'에서 개최된 `세포 인식기술 경진대회'에서 취리히 리서치센터, 베이징대, 칭화대, 미시간대 등 다수의 세계 연구팀을 모두 제치고 1위로 우승을 달성했다고 28일 밝혔다.
뉴립스는 국제머신러닝학회(ICML), 표현학습국제학회(ICLR)와 함께 세계적인 권위의 기계학습 및 인공지능 분야 학회로 꼽힌다. 뛰어난 연구자들이 제출하는 논문들도 승인될 확률이 25%에 불과할 정도로 학회의 심사를 통과하기 어려운 것으로 알려져 있다.
윤세영 교수 연구팀은 이번 학회에서 `세포 인식기술 경진대회(Cell Segmentation Challenge)'에 참가했다. 이기훈(박사과정), 김상묵(박사과정), 김준기(석사과정)의 3명의 연구원으로 구성된 OSILAB 팀은 초고해상도의 현미경 이미지에서 인공지능이 자동으로 세포를 인식하는 MEDIAR(메디아) 기술을 개발해 2위 팀과 큰 성능 격차로 1위를 달성했다.
세포 인식은 생명 및 의료 분야의 시작이 되는 중요한 기반 기술이지만, 현미경의 측정 기술과 세포의 종류 등에 따라 다양한 형태로 관찰될 수 있어 인공지능이 학습하기 어려운 분야로 알려져 있다. 세포 인식기술 경진대회는 이러한 한계를 극복하기 위해 초고해상도의 현미경 이미지에서 제한된 시간 안에 세포를 인식하는 기술을 주제로 개최됐다.
연구팀은 기계학습에서 소수의 학습 데이터를 더 효과적으로 활용해 성능을 높이는 데이터 기반(Data-Centric) 접근법과 인공신경망의 구조를 개선하는 모델 기반(Model-Centric) 접근법을 종합적으로 활용해 MEDIAR(메디아) 기술을 개발했다. 개발된 인공지능 기술을 통해 정확하게 세포를 인식하고 고해상도 이미지를 빠르게 연산함으로써 대회에서 좋은 성과를 얻을 수 있었다. 지도교수인 KAIST 김재철AI대학원 윤세영 교수는 “MEDIAR는 세포 인식기술 경진대회를 통해 개발됐지만 기상 예측이나 자율주행과 같이 이미지 속 다양한 형태의 개체 인식을 통해 정확한 예측이 필요한 많은 분야에 적용할 수 있다”라고 향후 다양한 활용을 기대했다.
팀을 이끌었던 이기훈 박사과정은 "처음 접하는 분야에서도 성과를 낼 수 있었던 것은 평소 기본기를 중요시하는 교수님의 가르침 덕분ˮ이라며 "새로운 문제에 끊임없이 도전하자는 것이 연구팀의 기본 정신ˮ이라고 강조했다. 이어 같은 연구실 김상묵 박사과정은 "연구 과정에서 많은 실패가 있었지만, 세상에 꼭 필요한 기술이라는 생각으로 끝까지 노력했다ˮ라며 "혼자서라면 절대 해내지 못했던 결과인 만큼 팀원들에게 정말 감사하다ˮ라고 수상 소감을 전했다. 같은 연구실 김준기 석사과정은 "팀원들과 이룬 성과가 의료 분야 인공지능이 겪는 현실의 문제를 해결하는 데 도움이 될 수 있기를 바란다”라고 밝혔다.
연구팀은 생명과학 분야 연구의 발전을 돕기 위해 개발된 기술을 전면 오픈소스로 공개한다고 밝혔다. 학습된 인공지능 모델과 인공지능을 구현하기 위한 프로그램의 소스 코드는 개발자 플랫폼인 깃허브 (GitHub)를 통해 이용할 수 있다.
인공지능으로 정확한 세포 이미지 분석..세계 AI 생명과학 분야 대회 우승
우리 대학 김재철AI대학원 윤세영 교수 연구팀이 세계 최고 수준의 인공지능(AI) 학회인 `뉴립스(NeurIPS, 신경정보처리시스템학회) 2022'에서 개최된 `세포 인식기술 경진대회'에서 취리히 리서치센터, 베이징대, 칭화대, 미시간대 등 다수의 세계 연구팀을 모두 제치고 1위로 우승을 달성했다고 28일 밝혔다.
뉴립스는 국제머신러닝학회(ICML), 표현학습국제학회(ICLR)와 함께 세계적인 권위의 기계학습 및 인공지능 분야 학회로 꼽힌다. 뛰어난 연구자들이 제출하는 논문들도 승인될 확률이 25%에 불과할 정도로 학회의 심사를 통과하기 어려운 것으로 알려져 있다.
윤세영 교수 연구팀은 이번 학회에서 `세포 인식기술 경진대회(Cell Segmentation Challenge)'에 참가했다. 이기훈(박사과정), 김상묵(박사과정), 김준기(석사과정)의 3명의 연구원으로 구성된 OSILAB 팀은 초고해상도의 현미경 이미지에서 인공지능이 자동으로 세포를 인식하는 MEDIAR(메디아) 기술을 개발해 2위 팀과 큰 성능 격차로 1위를 달성했다.
세포 인식은 생명 및 의료 분야의 시작이 되는 중요한 기반 기술이지만, 현미경의 측정 기술과 세포의 종류 등에 따라 다양한 형태로 관찰될 수 있어 인공지능이 학습하기 어려운 분야로 알려져 있다. 세포 인식기술 경진대회는 이러한 한계를 극복하기 위해 초고해상도의 현미경 이미지에서 제한된 시간 안에 세포를 인식하는 기술을 주제로 개최됐다.
연구팀은 기계학습에서 소수의 학습 데이터를 더 효과적으로 활용해 성능을 높이는 데이터 기반(Data-Centric) 접근법과 인공신경망의 구조를 개선하는 모델 기반(Model-Centric) 접근법을 종합적으로 활용해 MEDIAR(메디아) 기술을 개발했다. 개발된 인공지능 기술을 통해 정확하게 세포를 인식하고 고해상도 이미지를 빠르게 연산함으로써 대회에서 좋은 성과를 얻을 수 있었다. 지도교수인 KAIST 김재철AI대학원 윤세영 교수는 “MEDIAR는 세포 인식기술 경진대회를 통해 개발됐지만 기상 예측이나 자율주행과 같이 이미지 속 다양한 형태의 개체 인식을 통해 정확한 예측이 필요한 많은 분야에 적용할 수 있다”라고 향후 다양한 활용을 기대했다.
팀을 이끌었던 이기훈 박사과정은 "처음 접하는 분야에서도 성과를 낼 수 있었던 것은 평소 기본기를 중요시하는 교수님의 가르침 덕분ˮ이라며 "새로운 문제에 끊임없이 도전하자는 것이 연구팀의 기본 정신ˮ이라고 강조했다. 이어 같은 연구실 김상묵 박사과정은 "연구 과정에서 많은 실패가 있었지만, 세상에 꼭 필요한 기술이라는 생각으로 끝까지 노력했다ˮ라며 "혼자서라면 절대 해내지 못했던 결과인 만큼 팀원들에게 정말 감사하다ˮ라고 수상 소감을 전했다. 같은 연구실 김준기 석사과정은 "팀원들과 이룬 성과가 의료 분야 인공지능이 겪는 현실의 문제를 해결하는 데 도움이 될 수 있기를 바란다”라고 밝혔다.
연구팀은 생명과학 분야 연구의 발전을 돕기 위해 개발된 기술을 전면 오픈소스로 공개한다고 밝혔다. 학습된 인공지능 모델과 인공지능을 구현하기 위한 프로그램의 소스 코드는 개발자 플랫폼인 깃허브 (GitHub)를 통해 이용할 수 있다.
2022.12.28
조회수 3957
-
 세계 최초로 사람처럼 사물의 개념을 스스로 학습하는 장면 인식 기술 개발
우리 대학 전산학부 안성진 교수 연구팀이 미국 럿거스(Rutgers) 대학교와 공동연구를 통해 사람의 라벨링 없이 스스로 영상 속 객체를 식별할 수 있는 인공지능 기술을 개발했다고 1일 밝혔다. 이 모델은 복잡한 영상에서 각 장면의 객체들에 대한 명시적인 라벨링 없이도 객체를 식별하는 최초의 인공지능 모델이다.
기계가 주변 환경을 지능적으로 인지하고 추론하기 위해서는 시각적 장면을 구성하는 객체들과 그들의 관계를 파악하는 능력이 필수적이다. 하지만 이 분야의 연구는 대부분 영상의 각 픽셀에 대응하는 객체의 라벨을 사람이 일일이 표시해야 하는 지도적 학습 방식을 사용했다. 이 같은 수작업은 오류가 발생하기 쉽고 많은 시간과 비용을 요구한다는 단점이 있다.
이에 반해 이번에 연구팀이 개발한 기술은 인간과 유사하게 환경에 대한 관측만으로 객체의 개념을 스스로 자가 학습하는 방식을 취한다. 이렇게 인간의 지도 없이 스스로 객체의 개념을 학습할 수 있는 인공지능은 차세대 인지 기술의 핵심으로 기대돼왔다.
비지도 학습을 이용한 이전 연구들은 단순한 객체 형태와 배경이 명확히 구분될 수 있는 단순한 장면에서만 객체를 식별하는 단점이 있었다. 이와 달리 이번에 안성진 교수 연구팀이 개발한 기술은 복잡한 형태의 많은 객체가 존재하는 사실적인 장면에도 적용될 수 있는 최초의 모델이다.
이 연구는 그림 인공지능 소프트웨어인 DALL-E와 같이 텍스트 입력을 통해 사실적인 이미지를 생성할 수 있는 이미지 생성 연구에서 영감을 얻었다. 연구팀은 텍스트를 입력하는 대신, 모델이 장면에서 객체를 감지하고 그 객체의 표상(representation)으로부터 이미지를 생성하는 방식으로 모델을 학습시켰다. 또한, 모델에 DALL-E와 유사한 트랜스포머 디코더를 사용하는 것이 사실적이고 복잡한 영상을 처리할 수 있게 한 주요 요인이라고 밝혔다.
연구팀은 복잡하고 정제되지 않은 영상뿐만 아니라, 많은 물고기가 있는 수족관과 교통이 혼잡한 도로의 상황을 담은 유튜브 영상과 같이 복잡한 실제 영상에서도 모델의 성능을 측정했다. 그 결과, 제시된 모델이 기존 모델보다 객체를 훨씬 더 정확하게 분할하고 일반화하는 것을 확인할 수 있었다.
연구팀을 이끈 안성진 교수는 "인간과 유사한 자가 학습 방식으로 상황을 인지하고 해석하는 혁신적인 기술ˮ이라며 "시각적 상황인지 능력을 획기적으로 개선해 지능형 로봇 분야, 자율 주행 분야뿐만 아니라 시각적 인공지능 기술 전반에 비용 절감과 성능향상을 가져올 수 있다ˮ고 말했다.
이번 연구는 미국 뉴올리언스에서 지난 11월 28일부터 개최되어 12월 9일까지 진행 예정인 세계 최고 수준의 기계학습(머신러닝) 학회인 제36회 신경정보처리학회(NeurIPS)에서 발표됐다.
세계 최초로 사람처럼 사물의 개념을 스스로 학습하는 장면 인식 기술 개발
우리 대학 전산학부 안성진 교수 연구팀이 미국 럿거스(Rutgers) 대학교와 공동연구를 통해 사람의 라벨링 없이 스스로 영상 속 객체를 식별할 수 있는 인공지능 기술을 개발했다고 1일 밝혔다. 이 모델은 복잡한 영상에서 각 장면의 객체들에 대한 명시적인 라벨링 없이도 객체를 식별하는 최초의 인공지능 모델이다.
기계가 주변 환경을 지능적으로 인지하고 추론하기 위해서는 시각적 장면을 구성하는 객체들과 그들의 관계를 파악하는 능력이 필수적이다. 하지만 이 분야의 연구는 대부분 영상의 각 픽셀에 대응하는 객체의 라벨을 사람이 일일이 표시해야 하는 지도적 학습 방식을 사용했다. 이 같은 수작업은 오류가 발생하기 쉽고 많은 시간과 비용을 요구한다는 단점이 있다.
이에 반해 이번에 연구팀이 개발한 기술은 인간과 유사하게 환경에 대한 관측만으로 객체의 개념을 스스로 자가 학습하는 방식을 취한다. 이렇게 인간의 지도 없이 스스로 객체의 개념을 학습할 수 있는 인공지능은 차세대 인지 기술의 핵심으로 기대돼왔다.
비지도 학습을 이용한 이전 연구들은 단순한 객체 형태와 배경이 명확히 구분될 수 있는 단순한 장면에서만 객체를 식별하는 단점이 있었다. 이와 달리 이번에 안성진 교수 연구팀이 개발한 기술은 복잡한 형태의 많은 객체가 존재하는 사실적인 장면에도 적용될 수 있는 최초의 모델이다.
이 연구는 그림 인공지능 소프트웨어인 DALL-E와 같이 텍스트 입력을 통해 사실적인 이미지를 생성할 수 있는 이미지 생성 연구에서 영감을 얻었다. 연구팀은 텍스트를 입력하는 대신, 모델이 장면에서 객체를 감지하고 그 객체의 표상(representation)으로부터 이미지를 생성하는 방식으로 모델을 학습시켰다. 또한, 모델에 DALL-E와 유사한 트랜스포머 디코더를 사용하는 것이 사실적이고 복잡한 영상을 처리할 수 있게 한 주요 요인이라고 밝혔다.
연구팀은 복잡하고 정제되지 않은 영상뿐만 아니라, 많은 물고기가 있는 수족관과 교통이 혼잡한 도로의 상황을 담은 유튜브 영상과 같이 복잡한 실제 영상에서도 모델의 성능을 측정했다. 그 결과, 제시된 모델이 기존 모델보다 객체를 훨씬 더 정확하게 분할하고 일반화하는 것을 확인할 수 있었다.
연구팀을 이끈 안성진 교수는 "인간과 유사한 자가 학습 방식으로 상황을 인지하고 해석하는 혁신적인 기술ˮ이라며 "시각적 상황인지 능력을 획기적으로 개선해 지능형 로봇 분야, 자율 주행 분야뿐만 아니라 시각적 인공지능 기술 전반에 비용 절감과 성능향상을 가져올 수 있다ˮ고 말했다.
이번 연구는 미국 뉴올리언스에서 지난 11월 28일부터 개최되어 12월 9일까지 진행 예정인 세계 최고 수준의 기계학습(머신러닝) 학회인 제36회 신경정보처리학회(NeurIPS)에서 발표됐다.
2022.12.02
조회수 3511
-
 위치인식 기술의 혁신, 인공지능 활용한 실내외 통합 GPS 시스템 개발
우리 대학 전산학부 한동수 교수 연구팀(지능형 서비스 통합 연구실)이 실내외 환경 구분 없이 정밀한 위치인식이 가능한 `실내외 통합 GPS 시스템'을 개발했다고 8일 밝혔다.
이번에 개발된 실내외 통합 GPS 시스템은 실외에서는 GPS 신호를 사용해 위치를 추정하고 실내에서는 관성센서, 기압센서, 지자기센서, 조도센서에서 얻어지는 신호를 복합적으로 사용해 위치를 인식한다. 이를 위해 연구팀은 인공지능 기법을 활용한 실내외 탐지, 건물 출입구 탐지, 건물 진입 층 탐지, 계단/엘리베이터 탐지, 층 탐지 기법 등을 개발했다. 아울러 개발된 각종 랜드마크 탐지 기법들을 보행자 항법 기법(PDR)과 연계시킨 소위 센서 퓨전 위치인식 알고리즘도 새롭게 개발했다.
지금까지는 GPS 신호가 도달하지 않는 공간에서는 무선랜 신호나 기지국 신호를 기반으로 위치를 인식하는 것이 보통이었다. 하지만 이번에 개발된 실내외 통합 GPS 시스템은 신호가 존재하지 않고 실내지도가 제공되지 않는 건물에서도 위치인식을 가능하게 하는 최초의 기술이다.
연구팀이 개발한 알고리즘은 구글, 애플의 위치인식 서비스에서는 제공하지 않는 건물 내에서의 정확한 층 정보를 제공할 수 있다. 비전이나 지구 자기장, 무선랜 측위 방식과 달리 사전 준비 작업이 필요치 않은 장점도 있다. 전 세계 어디에서나 사용할 수 있는 범용적인 실내외 통합 GPS 시스템을 구축할 수 있는 기반이 마련됐다.
연구팀은 GPS, 와이파이, 블루투스 신호 수신 칩과 관성센서, 기압센서, 지자기센서, 조도센서 등을 탑재시킨 실내외 통합 GPS 전용 보드도 제작했다. 또한 제작된 하드웨어(HW) 보드에 개발된 센서퓨전 위치인식 알고리즘을 탑재했다. 제작된 실내외 통합 GPS 전용 하드웨어(HW) 보드의 위치인식 정확도를 대전 KAIST 본원 N1 건물에서 측정한 결과, 층 추정에 있어서는 약 95%의 정확도를, 수평 방향으로는 약 3~6미터의 정확도를 달성했다. 실내외 전환에 있어서는 약 0.3초의 전환 속도를 달성했다. 보행자 항법(PDR) 기법을 통합시켰을 때는 1미터 내외의 정확도를 달성하였다.
연구팀은 위치인식 보드가 내장된 태그를 제작하고 박물관, 과학관, 미술관 방문객들을 위한 위치기반 전시 안내 서비스에 적용할 예정이다. 개발된 실내외 통합 GPS 태그는 어린이나 노약자를 보호하는 목적으로도 활용할 수 있으며 소방관 혹은 작업장 작업자의 위치 파악에도 활용할 수 있다. 한편 지하 주차장과 같은 실내로 진입하는 차량의 위치를 추정하는 차량용 센서 퓨전 위치인식 알고리즘과 위치인식 보드도 개발하고 있다.
연구팀은 차량용 실내외 통합 GPS 위치인식 보드가 제작되면 자동차 제조사, 차량 대여 업체들과의 협력을 모색할 예정이며, 스마트폰에 탑재될 센서 퓨전 위치인식 알고리즘도 개발할 예정이다. 개발된 알고리즘이 내장된 실내외 통합 GPS 앱이 개발되면 위치인식 분야에서 다양한 사업화를 모색하는 통신사와의 협력도 가능할 것으로 기대된다.
연구팀을 이끄는 전산학부 한동수 교수는 "무선 신호가 존재하지 않고 실내지도도 주어지지 않는 건물에서 위치인식이 가능한 실내외 통합 GPS 시스템 개발은 이번이 처음이며, 그 응용 분야도 무궁무진하다. 2022년부터 개발이 시작된 한국형 GPS(KPS) 시스템, 한국형 항공위성서비스(Korea Augmentation Satellite System, KASS)와 통합되면 한국이 실내외 통합 GPS 분야에서 선도 국가로 나설 수 있으며 향후 기술 격차를 더 벌릴 수 있도록 실내외 통합 GPS 반도체 칩도 제작할 계획이다ˮ라고 말했다.
또 "개발된 실내외 통합 GPS 태그를 사용한 과학관, 박물관, 미술관 위치기반 안내 서비스는 관람객의 동선 분석에도 유용하게 활용될 수 있다. 전시물 교체를 결정할 때 요구되는 꼭 필요한 유용한 정보다. 국립중앙과학관에 우선 적용될 수 있도록 노력하겠다”라고 말했다.
한편 실내외 통합 GPS 시스템, 그리고 위치기반 관람객 동선 분석 시스템 개발은 과기정통부의 과학문화전시서비스 역량강화지원사업의 지원으로 개발됐다.
위치인식 기술의 혁신, 인공지능 활용한 실내외 통합 GPS 시스템 개발
우리 대학 전산학부 한동수 교수 연구팀(지능형 서비스 통합 연구실)이 실내외 환경 구분 없이 정밀한 위치인식이 가능한 `실내외 통합 GPS 시스템'을 개발했다고 8일 밝혔다.
이번에 개발된 실내외 통합 GPS 시스템은 실외에서는 GPS 신호를 사용해 위치를 추정하고 실내에서는 관성센서, 기압센서, 지자기센서, 조도센서에서 얻어지는 신호를 복합적으로 사용해 위치를 인식한다. 이를 위해 연구팀은 인공지능 기법을 활용한 실내외 탐지, 건물 출입구 탐지, 건물 진입 층 탐지, 계단/엘리베이터 탐지, 층 탐지 기법 등을 개발했다. 아울러 개발된 각종 랜드마크 탐지 기법들을 보행자 항법 기법(PDR)과 연계시킨 소위 센서 퓨전 위치인식 알고리즘도 새롭게 개발했다.
지금까지는 GPS 신호가 도달하지 않는 공간에서는 무선랜 신호나 기지국 신호를 기반으로 위치를 인식하는 것이 보통이었다. 하지만 이번에 개발된 실내외 통합 GPS 시스템은 신호가 존재하지 않고 실내지도가 제공되지 않는 건물에서도 위치인식을 가능하게 하는 최초의 기술이다.
연구팀이 개발한 알고리즘은 구글, 애플의 위치인식 서비스에서는 제공하지 않는 건물 내에서의 정확한 층 정보를 제공할 수 있다. 비전이나 지구 자기장, 무선랜 측위 방식과 달리 사전 준비 작업이 필요치 않은 장점도 있다. 전 세계 어디에서나 사용할 수 있는 범용적인 실내외 통합 GPS 시스템을 구축할 수 있는 기반이 마련됐다.
연구팀은 GPS, 와이파이, 블루투스 신호 수신 칩과 관성센서, 기압센서, 지자기센서, 조도센서 등을 탑재시킨 실내외 통합 GPS 전용 보드도 제작했다. 또한 제작된 하드웨어(HW) 보드에 개발된 센서퓨전 위치인식 알고리즘을 탑재했다. 제작된 실내외 통합 GPS 전용 하드웨어(HW) 보드의 위치인식 정확도를 대전 KAIST 본원 N1 건물에서 측정한 결과, 층 추정에 있어서는 약 95%의 정확도를, 수평 방향으로는 약 3~6미터의 정확도를 달성했다. 실내외 전환에 있어서는 약 0.3초의 전환 속도를 달성했다. 보행자 항법(PDR) 기법을 통합시켰을 때는 1미터 내외의 정확도를 달성하였다.
연구팀은 위치인식 보드가 내장된 태그를 제작하고 박물관, 과학관, 미술관 방문객들을 위한 위치기반 전시 안내 서비스에 적용할 예정이다. 개발된 실내외 통합 GPS 태그는 어린이나 노약자를 보호하는 목적으로도 활용할 수 있으며 소방관 혹은 작업장 작업자의 위치 파악에도 활용할 수 있다. 한편 지하 주차장과 같은 실내로 진입하는 차량의 위치를 추정하는 차량용 센서 퓨전 위치인식 알고리즘과 위치인식 보드도 개발하고 있다.
연구팀은 차량용 실내외 통합 GPS 위치인식 보드가 제작되면 자동차 제조사, 차량 대여 업체들과의 협력을 모색할 예정이며, 스마트폰에 탑재될 센서 퓨전 위치인식 알고리즘도 개발할 예정이다. 개발된 알고리즘이 내장된 실내외 통합 GPS 앱이 개발되면 위치인식 분야에서 다양한 사업화를 모색하는 통신사와의 협력도 가능할 것으로 기대된다.
연구팀을 이끄는 전산학부 한동수 교수는 "무선 신호가 존재하지 않고 실내지도도 주어지지 않는 건물에서 위치인식이 가능한 실내외 통합 GPS 시스템 개발은 이번이 처음이며, 그 응용 분야도 무궁무진하다. 2022년부터 개발이 시작된 한국형 GPS(KPS) 시스템, 한국형 항공위성서비스(Korea Augmentation Satellite System, KASS)와 통합되면 한국이 실내외 통합 GPS 분야에서 선도 국가로 나설 수 있으며 향후 기술 격차를 더 벌릴 수 있도록 실내외 통합 GPS 반도체 칩도 제작할 계획이다ˮ라고 말했다.
또 "개발된 실내외 통합 GPS 태그를 사용한 과학관, 박물관, 미술관 위치기반 안내 서비스는 관람객의 동선 분석에도 유용하게 활용될 수 있다. 전시물 교체를 결정할 때 요구되는 꼭 필요한 유용한 정보다. 국립중앙과학관에 우선 적용될 수 있도록 노력하겠다”라고 말했다.
한편 실내외 통합 GPS 시스템, 그리고 위치기반 관람객 동선 분석 시스템 개발은 과기정통부의 과학문화전시서비스 역량강화지원사업의 지원으로 개발됐다.
2022.07.08
조회수 7380
-
 인간의 촉각 뉴런을 모방한 뉴로모픽 모듈 개발
우리 대학 전기및전자공학부 최양규 교수 연구팀이 지난 2021년 8월에 뉴런과 시냅스를 동일 평면 위에서 동시 집적으로 ‘인간의 뇌를 모방한 뉴로모픽 반도체 모듈’을 개발하고, 연이어서 이번에는 ‘인간의 촉각 뉴런을 모방한 뉴로모픽 모듈’을 개발하는 데에 성공했다고 24일 밝혔다. 개발된 모듈은 인간의 촉각 뉴런과 같이 압력을 인식해 스파이크 신호를 출력할 수 있어, 뉴로모픽 촉각 인식 시스템을 구현할 수 있다.
우리 대학 전기및전자공학부 한준규 박사과정과 초일웅 박사과정이 공동 제1 저자로 참여한 이번 연구는 저명한 국제 학술지 ‘어드밴스드 사이언스(Advanced Science)’ 2022년 1월 온라인판에 출판됐으며, 후면 표지 논문(Back Cover)으로 선정됐다. (논문명 : Self-powered Artificial Mechanoreceptor based on Triboelectrification for a Neuromorphic Tactile System).
인공지능을 이용한 촉각 인식 시스템은 센서 어레이에서 수신된 신호를 인공 신경망을 이용해 높은 정확도로 물체, 패턴, 또는 질감을 인식할 수 있어, 다양한 분야에 걸쳐 유용하게 사용되고 있다. 하지만 이러한 시스템의 대부분은 폰 노이만 컴퓨터가 필요한 소프트웨어를 기반으로 하므로, 높은 전력을 소모할 수밖에 없어 모바일 또는 사물인터넷(IoT) 장치에 적용되기는 어렵다.
한편, 생물학적 촉각 인식 시스템은, 스파이크 형태로 감각 정보를 전달함으로써 낮은 전력 소비만으로 물체, 패턴, 또는 질감을 판별할 수 있다. 따라서 저전력 촉각 인식 시스템을 구축하기 위해, 생물학적 촉각 인식 시스템을 모방한 뉴로모픽 촉각 인식 시스템이 주목을 받고 있다. 뉴로모픽 촉각 인식 시스템을 구현하기 위해서는 인간의 촉각 뉴런처럼 외부 압력 신호를 스파이크 형태의 전기 신호로 변환해주는 구성 요소가 필요하다. 하지만, 일반적인 압력 센서는 이러한 기능을 수행할 수 없다.
연구팀은 마찰대전 발전기(triboelectric nanogenrator, TENG)와 바이리스터(biristor) 소자를 이용해, 압력을 인식해 스파이크 신호를 출력할 수 있는 뉴로모픽 모듈을 개발했다. 제작된 뉴로모픽 모듈은 마찰대전을 이용하기 때문에, 자가 발전이 가능하고 3 킬로파스칼(kPa) 수준의 낮은 압력을 감지할 수 있다. 이는 손가락으로 사물을 만질 때, 피부가 느끼는 압력 정도의 크기다. 연구팀은 제작된 뉴로모픽 모듈을 바탕으로 저전력 호흡 모니터링 시스템을 구축했다. 호흡 모니터링 센서가 코 주위에 설치되면 들숨 및 날숨을 감지하고 복부 주변에 설치되면 복식호흡을 별도로 감지할 수 있다. 따라서 수면 중 무호흡이 일어날 경우, 이를 감지해 경보를 보냄으로써 심각한 상황으로의 진행을 미연에 방지할 수 있다.
연구를 주도한 한준규 박사과정은 "이번에 개발한 뉴로모픽 센서 모듈은 센서 구동에 필요한 에너지를 스스로 생산하는 반영구적 자가 발전형으로 사물인터넷(IoT) 분야, 로봇, 보철, 인공촉수, 의료기기 등에 유용하게 사용될 수 있을 것으로 기대된다ˮ며, "이는 `인-센서 컴퓨팅(In-Sensor Computing)' 시대를 앞당기는 발판이 될 것이다ˮ고 연구의 의의를 설명했다.
한편 이번 연구는 한국연구재단 차세대지능형반도체기술개발사업, 중견연구사업, 미래반도체사업, BK21 사업 및 반도체설계교육센터의 지원을 받아 수행됐다.
인간의 촉각 뉴런을 모방한 뉴로모픽 모듈 개발
우리 대학 전기및전자공학부 최양규 교수 연구팀이 지난 2021년 8월에 뉴런과 시냅스를 동일 평면 위에서 동시 집적으로 ‘인간의 뇌를 모방한 뉴로모픽 반도체 모듈’을 개발하고, 연이어서 이번에는 ‘인간의 촉각 뉴런을 모방한 뉴로모픽 모듈’을 개발하는 데에 성공했다고 24일 밝혔다. 개발된 모듈은 인간의 촉각 뉴런과 같이 압력을 인식해 스파이크 신호를 출력할 수 있어, 뉴로모픽 촉각 인식 시스템을 구현할 수 있다.
우리 대학 전기및전자공학부 한준규 박사과정과 초일웅 박사과정이 공동 제1 저자로 참여한 이번 연구는 저명한 국제 학술지 ‘어드밴스드 사이언스(Advanced Science)’ 2022년 1월 온라인판에 출판됐으며, 후면 표지 논문(Back Cover)으로 선정됐다. (논문명 : Self-powered Artificial Mechanoreceptor based on Triboelectrification for a Neuromorphic Tactile System).
인공지능을 이용한 촉각 인식 시스템은 센서 어레이에서 수신된 신호를 인공 신경망을 이용해 높은 정확도로 물체, 패턴, 또는 질감을 인식할 수 있어, 다양한 분야에 걸쳐 유용하게 사용되고 있다. 하지만 이러한 시스템의 대부분은 폰 노이만 컴퓨터가 필요한 소프트웨어를 기반으로 하므로, 높은 전력을 소모할 수밖에 없어 모바일 또는 사물인터넷(IoT) 장치에 적용되기는 어렵다.
한편, 생물학적 촉각 인식 시스템은, 스파이크 형태로 감각 정보를 전달함으로써 낮은 전력 소비만으로 물체, 패턴, 또는 질감을 판별할 수 있다. 따라서 저전력 촉각 인식 시스템을 구축하기 위해, 생물학적 촉각 인식 시스템을 모방한 뉴로모픽 촉각 인식 시스템이 주목을 받고 있다. 뉴로모픽 촉각 인식 시스템을 구현하기 위해서는 인간의 촉각 뉴런처럼 외부 압력 신호를 스파이크 형태의 전기 신호로 변환해주는 구성 요소가 필요하다. 하지만, 일반적인 압력 센서는 이러한 기능을 수행할 수 없다.
연구팀은 마찰대전 발전기(triboelectric nanogenrator, TENG)와 바이리스터(biristor) 소자를 이용해, 압력을 인식해 스파이크 신호를 출력할 수 있는 뉴로모픽 모듈을 개발했다. 제작된 뉴로모픽 모듈은 마찰대전을 이용하기 때문에, 자가 발전이 가능하고 3 킬로파스칼(kPa) 수준의 낮은 압력을 감지할 수 있다. 이는 손가락으로 사물을 만질 때, 피부가 느끼는 압력 정도의 크기다. 연구팀은 제작된 뉴로모픽 모듈을 바탕으로 저전력 호흡 모니터링 시스템을 구축했다. 호흡 모니터링 센서가 코 주위에 설치되면 들숨 및 날숨을 감지하고 복부 주변에 설치되면 복식호흡을 별도로 감지할 수 있다. 따라서 수면 중 무호흡이 일어날 경우, 이를 감지해 경보를 보냄으로써 심각한 상황으로의 진행을 미연에 방지할 수 있다.
연구를 주도한 한준규 박사과정은 "이번에 개발한 뉴로모픽 센서 모듈은 센서 구동에 필요한 에너지를 스스로 생산하는 반영구적 자가 발전형으로 사물인터넷(IoT) 분야, 로봇, 보철, 인공촉수, 의료기기 등에 유용하게 사용될 수 있을 것으로 기대된다ˮ며, "이는 `인-센서 컴퓨팅(In-Sensor Computing)' 시대를 앞당기는 발판이 될 것이다ˮ고 연구의 의의를 설명했다.
한편 이번 연구는 한국연구재단 차세대지능형반도체기술개발사업, 중견연구사업, 미래반도체사업, BK21 사업 및 반도체설계교육센터의 지원을 받아 수행됐다.
2022.02.25
조회수 7192
-
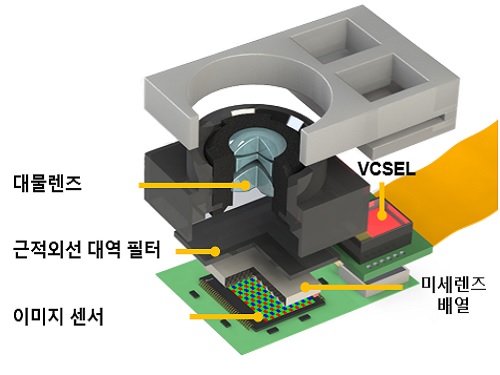 3차원 표정인식용 인공지능 라이트필드 카메라 개발
우리 대학 바이오및뇌공학과 정기훈, 이도헌 교수 공동연구팀이 근적외선 기반 라이트필드 카메라와 인공지능기술을 융합하여 얼굴의 감정표현을 구분하는 기술을 개발했다고 7일 밝혔다.
라이트필드 카메라는 일반적인 카메라와 다르게 미세렌즈 배열(Microlens arrays)을 이미지센서 앞에 삽입해 손에 들 수 있을 정도로 작은 크기이지만 한 번의 촬영으로 빛의 공간 및 방향 정보를 획득한다. 이를 통해 다시점 영상, 디지털 재초점, 3차원 영상 획득 등 다양한 영상 재구성이 가능하고 많은 활용 가능성으로 주목받고 있는 촬영 기술이다.
그러나 기존의 라이트필드 카메라는 실내조명에 의한 그림자와 미세렌즈 사이의 광학 크로스토크(Optical crosstalk)에 의해 이미지의 대비도 및 3차원 재구성의 정확도가 낮아지는 한계점이 있다.
연구팀은 라이트필드 카메라에 근적외선 영역의 수직 공진형 표면 발광 레이저(VCSEL) 광원과 근적외선 대역필터를 적용해 기존 라이트필드 카메라가 갖는 조명 환경에 따라 3차원 재구성의 정확도가 낮아지는 문제를 해결했다. 이를 통해 얼굴 정면 기준 0도, 30도, 60도 각도의 외부 조명에 대해, 근적외선 대역필터를 사용한 경우 최대 54%까지 영상 재구성 오류를 줄일 수 있었다. 또한, 가시광선 및 근적외선 영역을 흡수하는 광 흡수층을 미세렌즈 사이에 제작하면서 광학 크로스토크를 최소화해 원시 영상의 대비도를 기존 대비 약 2.1배 정도로 획기적으로 향상하는 데 성공했다.
이를 통해 기존 라이트필드 카메라의 한계를 극복하고 3차원 표정 영상 재구성에 최적화된 근적외선 기반 라이트필드 카메라(NIR-LFC, NIR-based light-field camera) 개발에 성공했다. 연구팀은 개발한 카메라를 통해 피험자의 다양한 감정표정을 가진 얼굴의 3차원 재구성 이미지를 조명 환경과 관계없이 고품질로 획득할 수 있었다.
획득한 3차원 얼굴 이미지로부터 기계 학습을 통해 성공적으로 표정을 구분할 수 있었고, 분류 결과의 정확도는 평균 85% 정도로 2차원 이미지를 이용했을 때보다 통계적으로 유의미하게 높은 정확도를 보였다. 이뿐만 아니라, 연구팀은 표정에 따른 얼굴의 3차원 거리 정보의 상호의존성을 계산한 결과를 통해, 라이트필드 카메라가 인간이나 기계가 표정을 판독할 때 어떤 정보를 활용하는지에 대한 단서를 제공할 수 있음을 확인했다.
정기훈 교수는 "연구팀이 개발한 초소형 라이트필드 카메라는 정량적으로 인간의 표정과 감정을 분석하기 위한 새로운 플랫폼으로 활용될 수 있을 것으로 기대된다ˮ며 "모바일 헬스케어, 현장 진단, 사회 인지, 인간-기계 상호작용 등의 분야에서 활용될 것ˮ이라고 연구의 의미를 설명했다.
우리 대학 바이오및뇌공학과 배상인 박사과정 졸업생이 주도한 이번 연구 결과는 국제저명학술지 `어드밴스드 인텔리전트 시스템즈(Advanced Intelligent Systems)'에 2021년 12월 16일 온라인 게재됐다. (논문명: Machine-Learned Light-Field Camera that Reads Facial Expression from High-Contrast and Illumination Invariant 3D Facial Images).
한편 이번 연구는 과학기술정보통신부 및 산업통상자원부의 지원을 받아 수행됐다.
3차원 표정인식용 인공지능 라이트필드 카메라 개발
우리 대학 바이오및뇌공학과 정기훈, 이도헌 교수 공동연구팀이 근적외선 기반 라이트필드 카메라와 인공지능기술을 융합하여 얼굴의 감정표현을 구분하는 기술을 개발했다고 7일 밝혔다.
라이트필드 카메라는 일반적인 카메라와 다르게 미세렌즈 배열(Microlens arrays)을 이미지센서 앞에 삽입해 손에 들 수 있을 정도로 작은 크기이지만 한 번의 촬영으로 빛의 공간 및 방향 정보를 획득한다. 이를 통해 다시점 영상, 디지털 재초점, 3차원 영상 획득 등 다양한 영상 재구성이 가능하고 많은 활용 가능성으로 주목받고 있는 촬영 기술이다.
그러나 기존의 라이트필드 카메라는 실내조명에 의한 그림자와 미세렌즈 사이의 광학 크로스토크(Optical crosstalk)에 의해 이미지의 대비도 및 3차원 재구성의 정확도가 낮아지는 한계점이 있다.
연구팀은 라이트필드 카메라에 근적외선 영역의 수직 공진형 표면 발광 레이저(VCSEL) 광원과 근적외선 대역필터를 적용해 기존 라이트필드 카메라가 갖는 조명 환경에 따라 3차원 재구성의 정확도가 낮아지는 문제를 해결했다. 이를 통해 얼굴 정면 기준 0도, 30도, 60도 각도의 외부 조명에 대해, 근적외선 대역필터를 사용한 경우 최대 54%까지 영상 재구성 오류를 줄일 수 있었다. 또한, 가시광선 및 근적외선 영역을 흡수하는 광 흡수층을 미세렌즈 사이에 제작하면서 광학 크로스토크를 최소화해 원시 영상의 대비도를 기존 대비 약 2.1배 정도로 획기적으로 향상하는 데 성공했다.
이를 통해 기존 라이트필드 카메라의 한계를 극복하고 3차원 표정 영상 재구성에 최적화된 근적외선 기반 라이트필드 카메라(NIR-LFC, NIR-based light-field camera) 개발에 성공했다. 연구팀은 개발한 카메라를 통해 피험자의 다양한 감정표정을 가진 얼굴의 3차원 재구성 이미지를 조명 환경과 관계없이 고품질로 획득할 수 있었다.
획득한 3차원 얼굴 이미지로부터 기계 학습을 통해 성공적으로 표정을 구분할 수 있었고, 분류 결과의 정확도는 평균 85% 정도로 2차원 이미지를 이용했을 때보다 통계적으로 유의미하게 높은 정확도를 보였다. 이뿐만 아니라, 연구팀은 표정에 따른 얼굴의 3차원 거리 정보의 상호의존성을 계산한 결과를 통해, 라이트필드 카메라가 인간이나 기계가 표정을 판독할 때 어떤 정보를 활용하는지에 대한 단서를 제공할 수 있음을 확인했다.
정기훈 교수는 "연구팀이 개발한 초소형 라이트필드 카메라는 정량적으로 인간의 표정과 감정을 분석하기 위한 새로운 플랫폼으로 활용될 수 있을 것으로 기대된다ˮ며 "모바일 헬스케어, 현장 진단, 사회 인지, 인간-기계 상호작용 등의 분야에서 활용될 것ˮ이라고 연구의 의미를 설명했다.
우리 대학 바이오및뇌공학과 배상인 박사과정 졸업생이 주도한 이번 연구 결과는 국제저명학술지 `어드밴스드 인텔리전트 시스템즈(Advanced Intelligent Systems)'에 2021년 12월 16일 온라인 게재됐다. (논문명: Machine-Learned Light-Field Camera that Reads Facial Expression from High-Contrast and Illumination Invariant 3D Facial Images).
한편 이번 연구는 과학기술정보통신부 및 산업통상자원부의 지원을 받아 수행됐다.
2022.01.07
조회수 5878
-
 서민준 교수 연구팀, VALUE Challenge 2021 영상검색 트랙 부문 우승
우리 대학 김재철AI대학원 서민준 교수 연구팀(오한석 석사과정)이 마이크로소프트가 주최한 AI 영상 인식 대회(VALUE Challenge 2021, 이하 밸류 챌린지) 영상 검색 트랙(Video Retrieval Track)에서 텐센트, 카카오, 컬럼비아 대학 등 우수한 팀들을 제치고 우승했다. 이 대회에는 영상 AI 분야 스타트업 트웰브랩스(대표 이재성) 이승준 CTO와 함께 참여했다.
이번 밸류 챌린지는 컴퓨터 비전 분야 권위의 학회인 ICCV(International Conference on Computer Vision)의 행사 중 일환으로 진행된 대회로 영상에 대한 인공지능의 이해능력을 평가하는 세계 최초의 비교·평가 대회로, 올해 6월부터 9월까지 진행되었다. 밸류 챌린지에서는 3개의 트랙으로 나뉘어 진행됐다. 이 중 영상 검색 트랙에서는 7만4천 개의 특정 분야에 치우치지 않은 다양한 동영상에 담긴 시각 및 음성 정보를 분석하여, 주어진 문장에 해당되는 영상 내 구간을 정확하게 빨리 찾는 것이 평가 기준이었다.
서민준 교수 연구팀과 트웰브랩스는 시각 정보에 특화된 기존의 영상검색 기술에서 진일보하여 음성과 시간의 흐름 등의 다양한 정보까지 종합적으로 인식할 수 있도록 AI 모델을 학습하여 인식률을 극대화하였다. 또한 다양한 유형의 콘텐츠를 이해할 수 있는 하나의 AI 모델을 독자적으로 개발하여 기술의 범용성을 입증하였다. 특히 마이크로소프트가 기록한 역대 최고 정확도를 앞질렀을 뿐만 아니라, 세계적인 기술 기업인 텐센트 및 카카오브레인과 미국 컬럼비아 대학 연구팀 등을 제치고 전 세계 1위를 차지했다.
위 상을 수상한 서민준 교수는 “자연어 처리 및 문서검색 분야에서 활용되는 최신 기술을 비디오 검색에 응용하고, 클라우드 컴퓨팅을 통한 대규모 실험으로 정확성과 속도를 극대로 끌어 올릴 수 있었다”며, “미디어의 홍수 속에서 유저가 원하는 비디오를 정확하게 찾아주는 제품을 만드는데 기여하길 바란다”고 밝혔다.
서민준 교수 연구팀, VALUE Challenge 2021 영상검색 트랙 부문 우승
우리 대학 김재철AI대학원 서민준 교수 연구팀(오한석 석사과정)이 마이크로소프트가 주최한 AI 영상 인식 대회(VALUE Challenge 2021, 이하 밸류 챌린지) 영상 검색 트랙(Video Retrieval Track)에서 텐센트, 카카오, 컬럼비아 대학 등 우수한 팀들을 제치고 우승했다. 이 대회에는 영상 AI 분야 스타트업 트웰브랩스(대표 이재성) 이승준 CTO와 함께 참여했다.
이번 밸류 챌린지는 컴퓨터 비전 분야 권위의 학회인 ICCV(International Conference on Computer Vision)의 행사 중 일환으로 진행된 대회로 영상에 대한 인공지능의 이해능력을 평가하는 세계 최초의 비교·평가 대회로, 올해 6월부터 9월까지 진행되었다. 밸류 챌린지에서는 3개의 트랙으로 나뉘어 진행됐다. 이 중 영상 검색 트랙에서는 7만4천 개의 특정 분야에 치우치지 않은 다양한 동영상에 담긴 시각 및 음성 정보를 분석하여, 주어진 문장에 해당되는 영상 내 구간을 정확하게 빨리 찾는 것이 평가 기준이었다.
서민준 교수 연구팀과 트웰브랩스는 시각 정보에 특화된 기존의 영상검색 기술에서 진일보하여 음성과 시간의 흐름 등의 다양한 정보까지 종합적으로 인식할 수 있도록 AI 모델을 학습하여 인식률을 극대화하였다. 또한 다양한 유형의 콘텐츠를 이해할 수 있는 하나의 AI 모델을 독자적으로 개발하여 기술의 범용성을 입증하였다. 특히 마이크로소프트가 기록한 역대 최고 정확도를 앞질렀을 뿐만 아니라, 세계적인 기술 기업인 텐센트 및 카카오브레인과 미국 컬럼비아 대학 연구팀 등을 제치고 전 세계 1위를 차지했다.
위 상을 수상한 서민준 교수는 “자연어 처리 및 문서검색 분야에서 활용되는 최신 기술을 비디오 검색에 응용하고, 클라우드 컴퓨팅을 통한 대규모 실험으로 정확성과 속도를 극대로 끌어 올릴 수 있었다”며, “미디어의 홍수 속에서 유저가 원하는 비디오를 정확하게 찾아주는 제품을 만드는데 기여하길 바란다”고 밝혔다.
2021.10.20
조회수 5332
-
 한국인의 자연스러운 감성 인식 인공지능을 위한 공공 DB 구축
기계적 인공지능을 뛰어넘는 감성 지능기술 기반의 미래산업 창출과 효율적인 동영상 요약 서비스 개발을 위한 공공 데이터베이스 구축 사업에 대학이 주도적으로 나선다.
문화기술대학원 박주용 교수 연구팀은 한국인의 감정을 인지할 수 있는 감성 기술과 지능형 영상 요약기술 개발을 위한 인공지능 빅데이터 구축 사업을 통해 코로나 이후 새로운 인공지능산업 창출에 적극적으로 나설 계획이라고 24일 밝혔다.
현재 인공지능은 질병 진단과 자율운전 등 인간의 기계적인 움직임과 판단력을 보완하는 영역에서 활용 폭을 넓히고 있다. 그러나 사람들의 미묘한 감정 표현 인식처럼 기계적으로 판단하기 어려운 문제를 해결하는 '감성 지능' 기술의 국내 수준은 아직 걸음마 단계라고 평가받고 있다. 미국이나 일본과 같은 선진국에서 '험인텔(Humintell)'과 같은 감성 인식 기술기반 서비스가 두각을 보이는 상황에서 이제 우리나라도 사람의 감정을 인지할 수 있는 인공지능 기술 개발을 위해 고품질의 한국인 고유의 감정 표현과 관련된 데이터 수집하고, 또 다양한 응용 서비스 개발에도 더욱 박차를 가해야 한다는 목소리가 커지고 있다.
박주용 교수 연구팀의 '감성 인식 인공지능 공공DB 구축사업'은 COVID-19로 인한 경기침체를 극복하고 코로나19 종식 이후 디지털 시대의 신산업 창출을 위해 과기정통부(장관 최기영)와 한국정보화진흥원(원장 문용식)의 '인공지능 학습용 데이터 구축(2차)' 사업 예산 및 KAIST가 주도하는 컨소시엄의 민간투자금 등 모두 46억 원의 재원으로 운용된다. 이를 위해 일반인과 전문배우 등 약 2,500명의 자발적 참여자로부터 감정 학습을 위한 얼굴 데이터 수집과 함께, K-pop과 K-드라마 등의 세계적 성공으로 수요가 급증하고 있는 환경에서 다양한 동영상 콘텐츠의 효과적인 영상 요약과 맞춤형 마케팅을 가능케 하는 영상 데이터 확보에 나선다.
이 사업은 우리 대학 문화기술대학원이 주관하고 메트릭스리서치(대표 나윤정), 액션파워(공동대표 조홍식/이지화), 소리자바(대표이사 안상현), 데이터헌트(대표이사 김태헌), 아트센터 나비미술관(관장 노소영), 리콘랩스(대표이사 반성훈)가 공동연구기관으로, 그리고 대홍기획(대표이사 홍성현)이 수요기관으로 참여한다. 이밖에 한국 소비자 광고심리학회가 자문하는 이 프로젝트에서 개발되는 데이터베이스, 인공지능 학습모델, 프로그래밍 코드 등 모든 연구결과는 공공재이기 때문에 누구나 연구와 사업에 사용이 가능하다.
특히 문화기술대학원 박주용, 이원재, 남주한 교수팀과 리콘랩스, 아트센터 나비미술관은 사용자의 심리적 건강을 추적할 수 있는 심리 일기장, 음악 영상의 하이라이트 생성을 위한 알고리즘, 서비스 사용자의 반응을 감지할 수 있는 앱 등 이번 사업을 통해 구축예정인 공공 데이터베이스를 활용하는 각종 응용 서비스를 설계하고 실험할 계획이다.
박주용 교수는 "인간을 감정을 이해하는 미래 인공지능 기술발전을 위해서는 고품질의 공공데이터 확보가 필수ˮ라고 전제하면서 "일상 사진을 공유하며 공감대를 찾는 소셜미디어 시대의 문화에 힘입어 새로운 산업을 창출하고 세계적 팬데믹으로 인한 위기 극복에 주도적인 역할을 하는 것은 KAIST의 당연한 책무"라고 강조했다.
한국인의 자연스러운 감성 인식 인공지능을 위한 공공 DB 구축
기계적 인공지능을 뛰어넘는 감성 지능기술 기반의 미래산업 창출과 효율적인 동영상 요약 서비스 개발을 위한 공공 데이터베이스 구축 사업에 대학이 주도적으로 나선다.
문화기술대학원 박주용 교수 연구팀은 한국인의 감정을 인지할 수 있는 감성 기술과 지능형 영상 요약기술 개발을 위한 인공지능 빅데이터 구축 사업을 통해 코로나 이후 새로운 인공지능산업 창출에 적극적으로 나설 계획이라고 24일 밝혔다.
현재 인공지능은 질병 진단과 자율운전 등 인간의 기계적인 움직임과 판단력을 보완하는 영역에서 활용 폭을 넓히고 있다. 그러나 사람들의 미묘한 감정 표현 인식처럼 기계적으로 판단하기 어려운 문제를 해결하는 '감성 지능' 기술의 국내 수준은 아직 걸음마 단계라고 평가받고 있다. 미국이나 일본과 같은 선진국에서 '험인텔(Humintell)'과 같은 감성 인식 기술기반 서비스가 두각을 보이는 상황에서 이제 우리나라도 사람의 감정을 인지할 수 있는 인공지능 기술 개발을 위해 고품질의 한국인 고유의 감정 표현과 관련된 데이터 수집하고, 또 다양한 응용 서비스 개발에도 더욱 박차를 가해야 한다는 목소리가 커지고 있다.
박주용 교수 연구팀의 '감성 인식 인공지능 공공DB 구축사업'은 COVID-19로 인한 경기침체를 극복하고 코로나19 종식 이후 디지털 시대의 신산업 창출을 위해 과기정통부(장관 최기영)와 한국정보화진흥원(원장 문용식)의 '인공지능 학습용 데이터 구축(2차)' 사업 예산 및 KAIST가 주도하는 컨소시엄의 민간투자금 등 모두 46억 원의 재원으로 운용된다. 이를 위해 일반인과 전문배우 등 약 2,500명의 자발적 참여자로부터 감정 학습을 위한 얼굴 데이터 수집과 함께, K-pop과 K-드라마 등의 세계적 성공으로 수요가 급증하고 있는 환경에서 다양한 동영상 콘텐츠의 효과적인 영상 요약과 맞춤형 마케팅을 가능케 하는 영상 데이터 확보에 나선다.
이 사업은 우리 대학 문화기술대학원이 주관하고 메트릭스리서치(대표 나윤정), 액션파워(공동대표 조홍식/이지화), 소리자바(대표이사 안상현), 데이터헌트(대표이사 김태헌), 아트센터 나비미술관(관장 노소영), 리콘랩스(대표이사 반성훈)가 공동연구기관으로, 그리고 대홍기획(대표이사 홍성현)이 수요기관으로 참여한다. 이밖에 한국 소비자 광고심리학회가 자문하는 이 프로젝트에서 개발되는 데이터베이스, 인공지능 학습모델, 프로그래밍 코드 등 모든 연구결과는 공공재이기 때문에 누구나 연구와 사업에 사용이 가능하다.
특히 문화기술대학원 박주용, 이원재, 남주한 교수팀과 리콘랩스, 아트센터 나비미술관은 사용자의 심리적 건강을 추적할 수 있는 심리 일기장, 음악 영상의 하이라이트 생성을 위한 알고리즘, 서비스 사용자의 반응을 감지할 수 있는 앱 등 이번 사업을 통해 구축예정인 공공 데이터베이스를 활용하는 각종 응용 서비스를 설계하고 실험할 계획이다.
박주용 교수는 "인간을 감정을 이해하는 미래 인공지능 기술발전을 위해서는 고품질의 공공데이터 확보가 필수ˮ라고 전제하면서 "일상 사진을 공유하며 공감대를 찾는 소셜미디어 시대의 문화에 힘입어 새로운 산업을 창출하고 세계적 팬데믹으로 인한 위기 극복에 주도적인 역할을 하는 것은 KAIST의 당연한 책무"라고 강조했다.
2020.09.24
조회수 21953
-
 딥러닝 기반 실시간 기침 인식 카메라 개발
우리 대학 기계공학과 박용화 교수 연구팀이 ㈜에스엠 인스트루먼트와 공동으로 실시간으로 기침 소리를 인식하고 기침하는 사람의 위치를 이미지로 표시해주는 '기침 인식 카메라'를 개발했다고 3일 밝혔다.
작년 말부터 시작된 세계적 유행성 전염병인 코로나19가 최근 미국·중국·유럽 등 세계 각국에서 재확산되는 추세로 접어들면서 비접촉방식으로 전염병을 감지하는 기술에 대한 수요가 증가하고 있다.
코로나19의 대표적인 증상이 발열과 기침인데, 현재 발열은 열화상 카메라를 이용해 직접 접촉을 하지 않고도 체온을 쉽게 판별할 수 있다. 문제는 비접촉방식으로는 기침하는 사람의 증상을 쉽사리 파악하기 어렵다는 점이다. 박 교수 연구팀은 이런 문제를 해결하기 위해 기침 소리를 실시간으로 인식하는 딥러닝 기반의 기침 인식 모델을 개발했다. 또한 열화상 카메라와 같은 원리로 기침 소리와 기침하는 사람의 시각화를 위해 기침 인식 모델을 음향 카메라에 적용, 기침 소리와 기침하는 사람의 위치, 심지어 기침 횟수까지를 실시간으로 추적하고 기록이 가능한 '기침 인식 카메라'를 개발했다.
연구팀은 기침 인식 카메라가 사람이 밀집한 공공장소에서 전염병의 유행을 감지하거나 병원에서 환자의 상태를 상시 모니터링 가능한 의료용 장비로 활용될 것으로 기대하고 있다.
연구팀은 기침 인식 모델 개발을 위해 *합성 곱 신경망(convolutional neural network, CNN)을 기반으로 *지도학습(supervised learning)을 적용했다. 1초 길이 음향신호의 특징(feature)을 입력 신호로 받아, 1(기침) 또는 0(그 외)의 2진 신호를 출력하고 학습률의 최적화를 위해 일정 기간 학습률이 정체되면 학습률 값을 낮추도록 설정했다.
이어서 기침 인식 모델의 훈련 및 평가를 위해 구글과 유튜브 등에서 연구용으로 활발히 사용 중인 공개 음성데이터 세트인 `오디오세트(Audioset)'를 비롯해 `디맨드(DEMAND)'와 `이티에스아이(ETSI)', `티미트(TIMIT)' 등에서 데이터 세트를 수집했다. 이 중 `오디오세트'는 훈련 및 평가 데이터 세트 구성을 위해 사용했고 다른 데이터 세트의 경우 기침 인식 모델이 다양한 배경 소음을 학습할 수 있도록 데이터 증강(data augmentation)을 위한 배경 소음으로 사용했다.
☞ 합성 곱 신경망(convolutional neural network): 시각적 이미지를 분석하는 데 사용되는 인공신경망(생물학의 신경망에서 영감을 얻은 통계학적 학습 알고리즘)의 한 종류
☞ 지도학습(Supervised Learning): 훈련 데이터(Training Data)로부터 하나의 함수를 유추해내기 위한 기계 학습(Machine Learning)의 한 방법
데이터 증강을 위해 배경 소음을 15%~75%의 비율로 `오디오세트'에 섞은 후, 다양한 거리에 적응할 수 있게 음량을 0.25~1.0배로 조정했다. 훈련 및 평가 데이터 세트는 증강된 데이터 세트를 9:1 비율로 나눠 구성했으며, 시험 데이터 세트는 따로 사무실에서 녹음한 것을 사용했다.
모델 최적화를 위해서는 '스펙트로그램(spectrogram)' 등 5개의 음향 특징과 7개의 최적화 기기(optimizer)를 사용해 학습을 진행하고 시험 데이터 세트의 정확도를 측정, 성능을 확인한 결과 87.4%의 시험 정확도를 얻을 수 있었다.
연구팀은 이어 학습된 기침 인식 모델을 소리를 수집하는 마이크로폰 어레이와 카메라 모듈로 구성되는 음향 카메라에 적용했다. 그 결과 수집된 데이터는 음원의 위치를 계산하는 빔 형성 과정을 거쳐 기침 인식 모델이 기침 소리로 인식할 경우 기침 소리가 난 위치에 기침 소리임을 나타내는 등고선과 라벨이 각각 표시된다.
박 교수팀은 마지막 단계로 기침 인식 카메라의 예비 테스트를 진행한 결과, 여러 잡음 환경에서도 기침 소리와 그 이외의 소리로 구분이 가능하며 기침하는 사람과 그 사람의 위치, 횟수 등을 실시간으로 추적해 현장에서의 적용 가능성을 확인했다. 이들은 추후 병원 등 실사용 환경에서 추가 학습이 이뤄진다면 정확도는 87.4%보다 더 높아질 것으로 기대하고 있다.
박용화 교수는 "코로나19가 지속적으로 전파되고 있는 상황에서 공공장소와 다수 밀집 시설에 기침 인식 카메라를 활용하면 전염병의 방역 및 조기 감지에 큰 도움이 될 것ˮ이라고 말했다. 박 교수는 이어 "특히 병실에 적용하면 환자의 상태를 24시간 기록해 치료에 활용할 수 있기 때문에 의료진의 수고를 줄이고 환자 상태를 더 정밀하게 파악할 수 있을 것ˮ 이라고 강조했다.
한편, 이번 연구는 에너지기술평가원(산업통상자원부)의 지원을 받아 수행됐다.
딥러닝 기반 실시간 기침 인식 카메라 개발
우리 대학 기계공학과 박용화 교수 연구팀이 ㈜에스엠 인스트루먼트와 공동으로 실시간으로 기침 소리를 인식하고 기침하는 사람의 위치를 이미지로 표시해주는 '기침 인식 카메라'를 개발했다고 3일 밝혔다.
작년 말부터 시작된 세계적 유행성 전염병인 코로나19가 최근 미국·중국·유럽 등 세계 각국에서 재확산되는 추세로 접어들면서 비접촉방식으로 전염병을 감지하는 기술에 대한 수요가 증가하고 있다.
코로나19의 대표적인 증상이 발열과 기침인데, 현재 발열은 열화상 카메라를 이용해 직접 접촉을 하지 않고도 체온을 쉽게 판별할 수 있다. 문제는 비접촉방식으로는 기침하는 사람의 증상을 쉽사리 파악하기 어렵다는 점이다. 박 교수 연구팀은 이런 문제를 해결하기 위해 기침 소리를 실시간으로 인식하는 딥러닝 기반의 기침 인식 모델을 개발했다. 또한 열화상 카메라와 같은 원리로 기침 소리와 기침하는 사람의 시각화를 위해 기침 인식 모델을 음향 카메라에 적용, 기침 소리와 기침하는 사람의 위치, 심지어 기침 횟수까지를 실시간으로 추적하고 기록이 가능한 '기침 인식 카메라'를 개발했다.
연구팀은 기침 인식 카메라가 사람이 밀집한 공공장소에서 전염병의 유행을 감지하거나 병원에서 환자의 상태를 상시 모니터링 가능한 의료용 장비로 활용될 것으로 기대하고 있다.
연구팀은 기침 인식 모델 개발을 위해 *합성 곱 신경망(convolutional neural network, CNN)을 기반으로 *지도학습(supervised learning)을 적용했다. 1초 길이 음향신호의 특징(feature)을 입력 신호로 받아, 1(기침) 또는 0(그 외)의 2진 신호를 출력하고 학습률의 최적화를 위해 일정 기간 학습률이 정체되면 학습률 값을 낮추도록 설정했다.
이어서 기침 인식 모델의 훈련 및 평가를 위해 구글과 유튜브 등에서 연구용으로 활발히 사용 중인 공개 음성데이터 세트인 `오디오세트(Audioset)'를 비롯해 `디맨드(DEMAND)'와 `이티에스아이(ETSI)', `티미트(TIMIT)' 등에서 데이터 세트를 수집했다. 이 중 `오디오세트'는 훈련 및 평가 데이터 세트 구성을 위해 사용했고 다른 데이터 세트의 경우 기침 인식 모델이 다양한 배경 소음을 학습할 수 있도록 데이터 증강(data augmentation)을 위한 배경 소음으로 사용했다.
☞ 합성 곱 신경망(convolutional neural network): 시각적 이미지를 분석하는 데 사용되는 인공신경망(생물학의 신경망에서 영감을 얻은 통계학적 학습 알고리즘)의 한 종류
☞ 지도학습(Supervised Learning): 훈련 데이터(Training Data)로부터 하나의 함수를 유추해내기 위한 기계 학습(Machine Learning)의 한 방법
데이터 증강을 위해 배경 소음을 15%~75%의 비율로 `오디오세트'에 섞은 후, 다양한 거리에 적응할 수 있게 음량을 0.25~1.0배로 조정했다. 훈련 및 평가 데이터 세트는 증강된 데이터 세트를 9:1 비율로 나눠 구성했으며, 시험 데이터 세트는 따로 사무실에서 녹음한 것을 사용했다.
모델 최적화를 위해서는 '스펙트로그램(spectrogram)' 등 5개의 음향 특징과 7개의 최적화 기기(optimizer)를 사용해 학습을 진행하고 시험 데이터 세트의 정확도를 측정, 성능을 확인한 결과 87.4%의 시험 정확도를 얻을 수 있었다.
연구팀은 이어 학습된 기침 인식 모델을 소리를 수집하는 마이크로폰 어레이와 카메라 모듈로 구성되는 음향 카메라에 적용했다. 그 결과 수집된 데이터는 음원의 위치를 계산하는 빔 형성 과정을 거쳐 기침 인식 모델이 기침 소리로 인식할 경우 기침 소리가 난 위치에 기침 소리임을 나타내는 등고선과 라벨이 각각 표시된다.
박 교수팀은 마지막 단계로 기침 인식 카메라의 예비 테스트를 진행한 결과, 여러 잡음 환경에서도 기침 소리와 그 이외의 소리로 구분이 가능하며 기침하는 사람과 그 사람의 위치, 횟수 등을 실시간으로 추적해 현장에서의 적용 가능성을 확인했다. 이들은 추후 병원 등 실사용 환경에서 추가 학습이 이뤄진다면 정확도는 87.4%보다 더 높아질 것으로 기대하고 있다.
박용화 교수는 "코로나19가 지속적으로 전파되고 있는 상황에서 공공장소와 다수 밀집 시설에 기침 인식 카메라를 활용하면 전염병의 방역 및 조기 감지에 큰 도움이 될 것ˮ이라고 말했다. 박 교수는 이어 "특히 병실에 적용하면 환자의 상태를 24시간 기록해 치료에 활용할 수 있기 때문에 의료진의 수고를 줄이고 환자 상태를 더 정밀하게 파악할 수 있을 것ˮ 이라고 강조했다.
한편, 이번 연구는 에너지기술평가원(산업통상자원부)의 지원을 받아 수행됐다.
2020.08.03
조회수 26041