%EC%8B%A0%EA%B2%BD%EB%A7%9D
-
 스스로 그림 그리는 인공지능 반도체 칩 개발
전기및전자공학부 유회준 교수 연구팀이 생성적 적대 신경망(GAN: Generative Adversarial Network)을 저전력, 효율적으로 처리하는 인공지능(AI: Artificial Intelligent) 반도체를 개발했다.
연구팀이 개발한 인공지능 반도체는 다중-심층 신경망을 처리할 수 있고 이를 저전력의 모바일 기기에서도 학습할 수 있다. 연구팀은 이번 반도체 칩 개발을 통해 이미지 합성, 스타일 변환, 손상 이미지 복원 등의 생성형 인공지능 기술을 모바일 기기에서 구현하는 데 성공했다.
강상훈 박사과정이 1 저자로 참여한 이번 연구결과는 지난 2월 17일 3천여 명 반도체 연구자들이 미국 샌프란시스코에 모여 개최한 국제고체회로설계학회(ISSCC)에서 발표됐다. (논문명 : GANPU: A 135TFLOPS/W Multi-DNN Training Processor for GANs with Speculative Dual-Sparsity Exploitation)
기존에 많이 연구된 인공지능 기술인 분류형 모델(Discriminative Model)은 주어진 질문에 답을 하도록 학습된 인공지능 모델로 물체 인식 및 추적, 음성인식, 얼굴인식 등에 활용된다.
이와 달리 생성적 적대 신경망(GAN)은 새로운 이미지를 생성·재생성할 수 있어 이미지 스타일 변환, 영상 합성, 손상된 이미지 복원 등 광범위한 분야에 활용된다. 또한, 모바일 기기의 다양한 응용 프로그램(영상·이미지 내 사용자의 얼굴 합성)에도 사용돼 학계뿐만 아니라 산업계에서도 주목을 받고 있다.
그러나 생성적 적대 신경망은 기존의 딥러닝 네트워크와는 달리 여러 개의 심층 신경망으로 이루어진 구조로, 개별 심층 신경망마다 다른 요구 조건으로 최적화된 가속을 하는 것이 어렵다.
또한, 고해상도 이미지를 생성하기 위해 기존 심층 신경망 모델보다 수십 배 많은 연산량을 요구한다. 즉, 적대적 생성 신경망은 연산 능력이 제한적이고 사용되는 메모리가 작은 모바일 장치(스마트폰, 태블릿 등)에서는 소프트웨어만으로 구현할 수 없었다.
최근 모바일 기기에서 인공지능을 구현하기 위해 다양한 가속기 개발이 이뤄지고 있지만, 기존 연구들은 추론 단계만 지원하거나 단일-심층 신경망 학습에 한정돼 있다.
연구팀은 단일-심층 신경망뿐만 아니라 생성적 적대 신경망과 같은 다중-심층 신경망을 처리할 수 있으면서 모바일에서 학습도 가능한 인공지능 반도체 GANPU(Generative Adversarial Networks Processing Unit)를 개발해 모바일 장치의 인공지능 활용범위를 넓혔다.
연구팀이 개발한 인공지능 반도체는 서버로 데이터를 보내지 않고 모바일 장치 내에서 생성적 적대 신경망(GAN)을 스스로 학습할 수 있어 사생활을 보호를 가능케 하는 프로세서라는 점에서 그 활용도가 기대된다.
모바일 기기에서 저전력으로 다중-심층 신경망을 가속하기 위해서 다양한 핵심 기술이 필요하다. 연구팀이 개발한 GANPU에 사용된 핵심 기술 중 대표적인 기술 3가지는 ▲적응형 워크로드 할당(ASTM, 처리해야 할 워크로드*를 파악해 칩 상의 다중-심층 신경망의 연산 및 메모리 특성에 맞춰 시간·공간으로 나누어 할당함으로써 효율적으로 가속하는 방법) ▲입출력 희소성 활용 극대화(IOAS, 인공신경망 입력 데이터에서 나타나는 0뿐만 아니라 출력의 0도 예측해 연산에서 제외함으로써 추론 및 학습 과정에서의 속도와 에너지효율 극대화) ▲지수부만을 사용한 0 패턴 추측(EORS, 인공신경망 출력의 0을 예측하기 위한 알고리즘으로 인공신경망 입력과 연결 강도(weight)의 부동소수점 데이터 중 지수 부분만을 사용해 연산을 간단히 수행하는 방법)이다.
위의 기술을 사용함으로써 연구팀의 GANPU는 기존 최고 성능을 보이던 심층 신경망 학습 반도체 대비 4.8배 증가한 에너지효율을 달성했다.
연구팀은 GANPU의 활용 예시로 태블릿 카메라로 찍은 사진을 사용자가 직접 수정할 수 있는 응용 기술을 시연했다. 사진상의 얼굴에서 머리·안경·눈썹 등 17가지 특징에 대해 추가·삭제 및 수정사항을 입력하면 GANPU가 실시간으로 이를 자동으로 완성해 보여 주는 얼굴 수정 시스템을 개발했다.
2020.04.06 조회수 13723
스스로 그림 그리는 인공지능 반도체 칩 개발
전기및전자공학부 유회준 교수 연구팀이 생성적 적대 신경망(GAN: Generative Adversarial Network)을 저전력, 효율적으로 처리하는 인공지능(AI: Artificial Intelligent) 반도체를 개발했다.
연구팀이 개발한 인공지능 반도체는 다중-심층 신경망을 처리할 수 있고 이를 저전력의 모바일 기기에서도 학습할 수 있다. 연구팀은 이번 반도체 칩 개발을 통해 이미지 합성, 스타일 변환, 손상 이미지 복원 등의 생성형 인공지능 기술을 모바일 기기에서 구현하는 데 성공했다.
강상훈 박사과정이 1 저자로 참여한 이번 연구결과는 지난 2월 17일 3천여 명 반도체 연구자들이 미국 샌프란시스코에 모여 개최한 국제고체회로설계학회(ISSCC)에서 발표됐다. (논문명 : GANPU: A 135TFLOPS/W Multi-DNN Training Processor for GANs with Speculative Dual-Sparsity Exploitation)
기존에 많이 연구된 인공지능 기술인 분류형 모델(Discriminative Model)은 주어진 질문에 답을 하도록 학습된 인공지능 모델로 물체 인식 및 추적, 음성인식, 얼굴인식 등에 활용된다.
이와 달리 생성적 적대 신경망(GAN)은 새로운 이미지를 생성·재생성할 수 있어 이미지 스타일 변환, 영상 합성, 손상된 이미지 복원 등 광범위한 분야에 활용된다. 또한, 모바일 기기의 다양한 응용 프로그램(영상·이미지 내 사용자의 얼굴 합성)에도 사용돼 학계뿐만 아니라 산업계에서도 주목을 받고 있다.
그러나 생성적 적대 신경망은 기존의 딥러닝 네트워크와는 달리 여러 개의 심층 신경망으로 이루어진 구조로, 개별 심층 신경망마다 다른 요구 조건으로 최적화된 가속을 하는 것이 어렵다.
또한, 고해상도 이미지를 생성하기 위해 기존 심층 신경망 모델보다 수십 배 많은 연산량을 요구한다. 즉, 적대적 생성 신경망은 연산 능력이 제한적이고 사용되는 메모리가 작은 모바일 장치(스마트폰, 태블릿 등)에서는 소프트웨어만으로 구현할 수 없었다.
최근 모바일 기기에서 인공지능을 구현하기 위해 다양한 가속기 개발이 이뤄지고 있지만, 기존 연구들은 추론 단계만 지원하거나 단일-심층 신경망 학습에 한정돼 있다.
연구팀은 단일-심층 신경망뿐만 아니라 생성적 적대 신경망과 같은 다중-심층 신경망을 처리할 수 있으면서 모바일에서 학습도 가능한 인공지능 반도체 GANPU(Generative Adversarial Networks Processing Unit)를 개발해 모바일 장치의 인공지능 활용범위를 넓혔다.
연구팀이 개발한 인공지능 반도체는 서버로 데이터를 보내지 않고 모바일 장치 내에서 생성적 적대 신경망(GAN)을 스스로 학습할 수 있어 사생활을 보호를 가능케 하는 프로세서라는 점에서 그 활용도가 기대된다.
모바일 기기에서 저전력으로 다중-심층 신경망을 가속하기 위해서 다양한 핵심 기술이 필요하다. 연구팀이 개발한 GANPU에 사용된 핵심 기술 중 대표적인 기술 3가지는 ▲적응형 워크로드 할당(ASTM, 처리해야 할 워크로드*를 파악해 칩 상의 다중-심층 신경망의 연산 및 메모리 특성에 맞춰 시간·공간으로 나누어 할당함으로써 효율적으로 가속하는 방법) ▲입출력 희소성 활용 극대화(IOAS, 인공신경망 입력 데이터에서 나타나는 0뿐만 아니라 출력의 0도 예측해 연산에서 제외함으로써 추론 및 학습 과정에서의 속도와 에너지효율 극대화) ▲지수부만을 사용한 0 패턴 추측(EORS, 인공신경망 출력의 0을 예측하기 위한 알고리즘으로 인공신경망 입력과 연결 강도(weight)의 부동소수점 데이터 중 지수 부분만을 사용해 연산을 간단히 수행하는 방법)이다.
위의 기술을 사용함으로써 연구팀의 GANPU는 기존 최고 성능을 보이던 심층 신경망 학습 반도체 대비 4.8배 증가한 에너지효율을 달성했다.
연구팀은 GANPU의 활용 예시로 태블릿 카메라로 찍은 사진을 사용자가 직접 수정할 수 있는 응용 기술을 시연했다. 사진상의 얼굴에서 머리·안경·눈썹 등 17가지 특징에 대해 추가·삭제 및 수정사항을 입력하면 GANPU가 실시간으로 이를 자동으로 완성해 보여 주는 얼굴 수정 시스템을 개발했다.
2020.04.06 조회수 13723 -
 포유류 종마다 시각 뇌신경망 구조 다른 원인 밝혀
바이오및뇌공학과 백세범 교수 연구팀이 포유류 종들의 시각피질에서 서로 다른 뇌신경망 구조가 형성되는 원리를 밝혔다.
이번 연구결과는 시스템 뇌신경과학 분야에서 수십 년간 설명되지 못했던 문제를 이론적 접근과 계산적 모델 시뮬레이션을 통해 해답을 제시한 계산뇌과학 연구의 성공적인 예시로 평가된다.
연구팀은 두뇌의 시각피질과 망막에 분포하는 신경세포들 간의 정보 추출 비율을 분석함으로써 특정 포유류 종이 갖는 시각피질의 기능적 구조를 예측할 수 있음을 밝혀냈다.
연구팀은 서로 다른 크기의 망막과 시각피질 사이의 신경망 연결 모델을 시뮬레이션 해 두 정보 처리 영역 사이에 대응되는 신경세포의 비율이 달라짐에 따라 완전히 다른 두 가지 구조의 기능성 뇌지도가 형성됨을 보이고, 이 결과가 실제 실험에서 관측되는 신경망 구조와 일치함을 증명했다.
장재선, 송민 박사과정이 공동 1저자로 참여한 이번 연구는 국제 학술지 ‘셀(cell)’의 온라인 자매지 ‘셀 리포츠(Cell Reports)’ 3월 10일 자에 게재됐다. (논문명 : Retino-cortical mapping ratio predicts columnar and salt-and-pepper organization in mammalian visual cortex)
포유류의 시각피질에서는 시각 자극의 방향에 따라 반응의 정도가 달라지는 성질인 방향 선택성(orientation selectivity)을 갖는 세포들이 관측된다. 원숭이, 고양이 등의 종에서는 이 세포들의 선호 방향이 연속적, 주기적인 형태로 변하는 방향성 지도(orientation map) 구조를 형성하는 반면, 생쥐 등의 설치류에서는 마치 소금과 후추를 뿌려 놓은 듯한 무작위에 가까운 형태로 분포해, 이를 소금-후추 구조(salt-and-pepper organization)라 한다.
동일한 역할을 수행하는 것으로 보이는 기능성 뇌신경망이 이렇게 종에 따라 다른 구조를 갖는 원인을 찾기 위해 지난 수십여 년 간 다양한 연구가 진행됐으나, 아직까지도 이를 결정하는 요인에 대해서는 명확하게 알려진 바가 없었다.
이러한 원리를 규명하기 위해 연구팀은 서로 다른 크기의 망막과 시각피질이 연결될 때 동일한 망막 신호를 샘플링하는 시각피질 세포의 비율이 달라지게 된다고 가정했다. 이러한 조건에서 망막-시각피질 신호의 샘플링 형태를 시뮬레이션 하여 샘플링 비율에 따라 시각피질에서 형성되는 기능성 지도의 구조가 완전히 다르게 결정될 수 있음을 발견했다.
이 결과를 기반으로 연구팀은 다양한 종들에 대한 망막 및 시각피질 데이터를 종합적으로 비교해 시각피질이 클수록, 또 망막이 작을수록 연속적인 방향성 지도가 형성되는 경향이 있음을 확인했다.
또한, 기존의 연구에서 확인된 포유류 여덟 종의 시각피질-망막 크기 비율을 기반으로 한 모델을 정량적으로 시뮬레이션하고, 이 결과가 실험에서 관측된 것과 같이 방향성 지도 존재 여부에 따라 두 그룹으로 명확히 나누어짐을 확인했다.
이러한 결과는 다른 종으로 진화가 이뤄질 때, 감각기관의 크기와 같은 지극히 단순한 물리적인 조건의 차이에 의해서도 뇌신경망의 구조가 완전히 다른 방향으로 변화될 수 있음을 뜻한다. 이는 다양한 생물학적 구조가 기존의 생각보다 훨씬 단순한 물리적 요소들의 차이에 의해 예측되거나 설명될 수 있음을 보여준다.
백세범 교수는 “이미 오랫동안 알려져 있었으나 그 의미를 찾아내지 못했던 데이터들과 이론적인 모델을 결합해 새로운 발견을 도출해낸 의미 있는 연구이다”라며 “뇌 과학뿐만 아니라 계통분류학, 진화생물학 등 생물의 기능적 구조와 관련된 다양한 생물학 분야에서 이론적 모델 연구의 역할에 대한 중요한 시각을 제공할 것이다”라고 언급했다.
이번 연구는 한국연구재단의 이공분야기초연구사업 및 원천기술개발사업의 지원을 받아 수행됐다.
2020.03.11 조회수 10939
포유류 종마다 시각 뇌신경망 구조 다른 원인 밝혀
바이오및뇌공학과 백세범 교수 연구팀이 포유류 종들의 시각피질에서 서로 다른 뇌신경망 구조가 형성되는 원리를 밝혔다.
이번 연구결과는 시스템 뇌신경과학 분야에서 수십 년간 설명되지 못했던 문제를 이론적 접근과 계산적 모델 시뮬레이션을 통해 해답을 제시한 계산뇌과학 연구의 성공적인 예시로 평가된다.
연구팀은 두뇌의 시각피질과 망막에 분포하는 신경세포들 간의 정보 추출 비율을 분석함으로써 특정 포유류 종이 갖는 시각피질의 기능적 구조를 예측할 수 있음을 밝혀냈다.
연구팀은 서로 다른 크기의 망막과 시각피질 사이의 신경망 연결 모델을 시뮬레이션 해 두 정보 처리 영역 사이에 대응되는 신경세포의 비율이 달라짐에 따라 완전히 다른 두 가지 구조의 기능성 뇌지도가 형성됨을 보이고, 이 결과가 실제 실험에서 관측되는 신경망 구조와 일치함을 증명했다.
장재선, 송민 박사과정이 공동 1저자로 참여한 이번 연구는 국제 학술지 ‘셀(cell)’의 온라인 자매지 ‘셀 리포츠(Cell Reports)’ 3월 10일 자에 게재됐다. (논문명 : Retino-cortical mapping ratio predicts columnar and salt-and-pepper organization in mammalian visual cortex)
포유류의 시각피질에서는 시각 자극의 방향에 따라 반응의 정도가 달라지는 성질인 방향 선택성(orientation selectivity)을 갖는 세포들이 관측된다. 원숭이, 고양이 등의 종에서는 이 세포들의 선호 방향이 연속적, 주기적인 형태로 변하는 방향성 지도(orientation map) 구조를 형성하는 반면, 생쥐 등의 설치류에서는 마치 소금과 후추를 뿌려 놓은 듯한 무작위에 가까운 형태로 분포해, 이를 소금-후추 구조(salt-and-pepper organization)라 한다.
동일한 역할을 수행하는 것으로 보이는 기능성 뇌신경망이 이렇게 종에 따라 다른 구조를 갖는 원인을 찾기 위해 지난 수십여 년 간 다양한 연구가 진행됐으나, 아직까지도 이를 결정하는 요인에 대해서는 명확하게 알려진 바가 없었다.
이러한 원리를 규명하기 위해 연구팀은 서로 다른 크기의 망막과 시각피질이 연결될 때 동일한 망막 신호를 샘플링하는 시각피질 세포의 비율이 달라지게 된다고 가정했다. 이러한 조건에서 망막-시각피질 신호의 샘플링 형태를 시뮬레이션 하여 샘플링 비율에 따라 시각피질에서 형성되는 기능성 지도의 구조가 완전히 다르게 결정될 수 있음을 발견했다.
이 결과를 기반으로 연구팀은 다양한 종들에 대한 망막 및 시각피질 데이터를 종합적으로 비교해 시각피질이 클수록, 또 망막이 작을수록 연속적인 방향성 지도가 형성되는 경향이 있음을 확인했다.
또한, 기존의 연구에서 확인된 포유류 여덟 종의 시각피질-망막 크기 비율을 기반으로 한 모델을 정량적으로 시뮬레이션하고, 이 결과가 실험에서 관측된 것과 같이 방향성 지도 존재 여부에 따라 두 그룹으로 명확히 나누어짐을 확인했다.
이러한 결과는 다른 종으로 진화가 이뤄질 때, 감각기관의 크기와 같은 지극히 단순한 물리적인 조건의 차이에 의해서도 뇌신경망의 구조가 완전히 다른 방향으로 변화될 수 있음을 뜻한다. 이는 다양한 생물학적 구조가 기존의 생각보다 훨씬 단순한 물리적 요소들의 차이에 의해 예측되거나 설명될 수 있음을 보여준다.
백세범 교수는 “이미 오랫동안 알려져 있었으나 그 의미를 찾아내지 못했던 데이터들과 이론적인 모델을 결합해 새로운 발견을 도출해낸 의미 있는 연구이다”라며 “뇌 과학뿐만 아니라 계통분류학, 진화생물학 등 생물의 기능적 구조와 관련된 다양한 생물학 분야에서 이론적 모델 연구의 역할에 대한 중요한 시각을 제공할 것이다”라고 언급했다.
이번 연구는 한국연구재단의 이공분야기초연구사업 및 원천기술개발사업의 지원을 받아 수행됐다.
2020.03.11 조회수 10939 -
 인공신경망 기반 핵융합플라즈마 자기장 재구성 기술 개발
우리 대학 원자력및양자공학과 김영철 교수 연구팀(핵융합및플라즈마연구실)이 국가핵융합연구소, ㈜모비스 연구진과 공동으로 인공신경망 기반 핵융합플라즈마 자기장의 재구성 기법을 개발했다.
김 교수 연구팀은 비실시간으로 엄밀히 계산된 자기장 구조와의 오차를 최소화함과 동시에 실시간으로 해당 정보를 제공할 수 있는 인공신경망을 개발해 핵융합플라즈마 제어 성능을 높이는 데 기여할 것으로 기대된다.
정세민 박사과정이 1 저자로 참여한 이번 연구 결과는 국제 학술지 ‘뉴클리어 퓨전(Nuclear Fusion)’ 2019년 12월 3일 자에 게재됐다. (논문명: Deep neural network Grad-Shafranov solver constrained with measured magnetic signals)
핵융합 연구에 널리 사용되는 토카막은 실시간으로 재구성된 자기장 구조를 바탕으로 초고온(약 1억도) 핵융합 플라즈마의 운전과 제어를 가능하게 만든다. 따라서 재구성된 자기장 구조의 정확도는 토카막 운전 성능과 밀접한 관계가 있다.
2계 비선형 미분방정식을 따르는 토카막의 내부 자기장은 일반적으로 수치해석 기법과 외부에서 측정된 자기장 값을 이용하여 재구성된다. 실시간과 비실시간 재구성 기법이 존재하며, 비실시간 기법의 정확도가 실시간보다 높다고 알려졌지만 이름에서도 확인할 수 있듯 실시간 운전에 활용하기 어렵다는 아쉬움이 있다.
연구팀은 비실시간 기법의 정확도를 유지하되 실시간으로 해당 정보를 확보할 수 있는 알고리즘을 인공신경망을 활용해 개발했다. 측정된 외부 자기장과 토카막 내부 공간 정보를 입력값으로 하고 비실시간 기법을 활용해 재구성된 자기장을 출력값으로 신경망을 훈련했다.
또한, 신경망의 출력값은 앞서 언급된 2계 비선형 미분방정식을 만족해야 하므로 이 역시 신경망의 훈련 조건으로 둬 단순한 자기장 재구성을 넘어서 해당 문제의 지배방정식 역시 만족하도록 했다.
연구팀이 개발한 기법은 그 성능의 우수성과 더불어 토카막의 고성능 운전 달성에 큰 영향을 미칠 것을 인정받았다. 세계적으로 활발히 진행 중인 토카막 연구에 가장 기초적이며 중추적인 토카막 내부 자기장 정보를 최소화된 오차 내에서 실시간으로 제공할 수 있다는 점에서 토카막을 활용한 핵융합발전의 가능성을 제고할 수 있을 것으로 기대된다.
이번 연구는 과학기술정보통신부 한국연구재단의 핵융합기초연구사업과 개인연구사업(신진연구) 및 기관고유과제 KAI-NEET의 지원을 받아 수행됐다.
타기관 참여연구진
국가핵융합연구소(공저자순): 박준교, 이상곤, 한현선, 김현석 ㈜모비스(공저자순): 이근호, 권대호
□ 그림 설명
그림1. 토카막 내부 재구성된 자기장 구조
2020.02.05 조회수 8571
인공신경망 기반 핵융합플라즈마 자기장 재구성 기술 개발
우리 대학 원자력및양자공학과 김영철 교수 연구팀(핵융합및플라즈마연구실)이 국가핵융합연구소, ㈜모비스 연구진과 공동으로 인공신경망 기반 핵융합플라즈마 자기장의 재구성 기법을 개발했다.
김 교수 연구팀은 비실시간으로 엄밀히 계산된 자기장 구조와의 오차를 최소화함과 동시에 실시간으로 해당 정보를 제공할 수 있는 인공신경망을 개발해 핵융합플라즈마 제어 성능을 높이는 데 기여할 것으로 기대된다.
정세민 박사과정이 1 저자로 참여한 이번 연구 결과는 국제 학술지 ‘뉴클리어 퓨전(Nuclear Fusion)’ 2019년 12월 3일 자에 게재됐다. (논문명: Deep neural network Grad-Shafranov solver constrained with measured magnetic signals)
핵융합 연구에 널리 사용되는 토카막은 실시간으로 재구성된 자기장 구조를 바탕으로 초고온(약 1억도) 핵융합 플라즈마의 운전과 제어를 가능하게 만든다. 따라서 재구성된 자기장 구조의 정확도는 토카막 운전 성능과 밀접한 관계가 있다.
2계 비선형 미분방정식을 따르는 토카막의 내부 자기장은 일반적으로 수치해석 기법과 외부에서 측정된 자기장 값을 이용하여 재구성된다. 실시간과 비실시간 재구성 기법이 존재하며, 비실시간 기법의 정확도가 실시간보다 높다고 알려졌지만 이름에서도 확인할 수 있듯 실시간 운전에 활용하기 어렵다는 아쉬움이 있다.
연구팀은 비실시간 기법의 정확도를 유지하되 실시간으로 해당 정보를 확보할 수 있는 알고리즘을 인공신경망을 활용해 개발했다. 측정된 외부 자기장과 토카막 내부 공간 정보를 입력값으로 하고 비실시간 기법을 활용해 재구성된 자기장을 출력값으로 신경망을 훈련했다.
또한, 신경망의 출력값은 앞서 언급된 2계 비선형 미분방정식을 만족해야 하므로 이 역시 신경망의 훈련 조건으로 둬 단순한 자기장 재구성을 넘어서 해당 문제의 지배방정식 역시 만족하도록 했다.
연구팀이 개발한 기법은 그 성능의 우수성과 더불어 토카막의 고성능 운전 달성에 큰 영향을 미칠 것을 인정받았다. 세계적으로 활발히 진행 중인 토카막 연구에 가장 기초적이며 중추적인 토카막 내부 자기장 정보를 최소화된 오차 내에서 실시간으로 제공할 수 있다는 점에서 토카막을 활용한 핵융합발전의 가능성을 제고할 수 있을 것으로 기대된다.
이번 연구는 과학기술정보통신부 한국연구재단의 핵융합기초연구사업과 개인연구사업(신진연구) 및 기관고유과제 KAI-NEET의 지원을 받아 수행됐다.
타기관 참여연구진
국가핵융합연구소(공저자순): 박준교, 이상곤, 한현선, 김현석 ㈜모비스(공저자순): 이근호, 권대호
□ 그림 설명
그림1. 토카막 내부 재구성된 자기장 구조
2020.02.05 조회수 8571 -
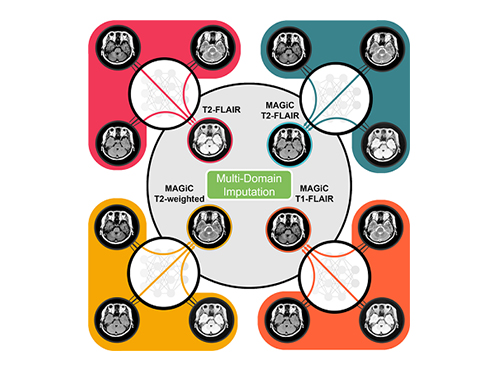 재촬영 없이 MRI 강조영상 얻는 AI 기술 개발
우리 대학 바이오및뇌공학과 예종철 교수 연구팀 자기공명영상(magnetic resonance imaging: MRI)에서 재촬영 없이도 누락된 강조영상을 얻을 수 있는 인공지능 기술을 개발했다.
이 연구를 통해 각 질환별로 강조영상이 암의 진단에 미치는 영향을 객관적으로 밝힐 수 있으며, 실제 임상에서 고비용의 MRI를 효과적이고 체계적으로 활용할 수 있는 방안을 설계할 수 있을 것으로 기대된다.
이동욱 박사가 1 저자로 참여하고 건국대 의과대학 영상의학과 문원진 교수팀이 참여한 이번 연구 결과는 국제 학술지 ‘네이처 머신인테리젼스(Nature Machine Intelligence)’ 1월 18일 자 온라인판에 게재됐다. (논문명 : Assessing the importance of magnetic resonance contrasts using collaborative generative adversarial networks).
MRI는 엑스선 컴퓨터 단층촬영, 초음파와 더불어 임상 진단에서 중요한 역할을 하는 진단 장비이다. 특히 비침습적 방법으로 고해상도의 영상을 얻기 때문에 종양이나 병변을 관찰하며 진단하는데 매우 중요한 임상 정보를 제공한다. 이는 영상의 대조도 (contrast)를 다양하게 조절할 수 있는 MRI의 특징 덕분이다.
예를 들어 뇌종양을 진단하는 데 활용되는 T1·T2 강조영상, FLAIR 기법 영상, T1 조영증강 영상 등 여러 가지 대조 영상을 얻어 진단에 사용함으로써 종양을 찾을 수 있다.
하지만 실제 임상 환경에서는 강조영상을 모두 얻기 어려운 경우가 많다. 여러 장의 강조영상 촬영을 위해 촬영시간이 길어지기도 하고, 잡음이나 인공음영 발생으로 인해 진단에 사용하기 어려운 경우가 많기 때문이다.
또한, 뇌질환진단을 위한 MRI 검사는 의심 질환이 무엇인지에 따라 필수 강조영상이 달라지며, 이후 특정 질환으로 진단명이 좁혀지면서 부득이하게 누락된 강조영상을 확보하기 위한 재촬영이 필요한 경우가 많다. 이러한 상황에 의해 많은 시간과 비용이 소모된다.
최근 인공지능 분야에서 생성적 적대 신경망(Generative adversarial networks, GAN)이라는 딥러닝을 이용해 영상을 합성하는 기술이 많이 보고되고 있지만, 이 기술을 MRI 강조영상 합성에 사용하면 준비하고 미리 학습해야 하는 네트워크가 너무 많아지게 된다.
또한, 이러한 기법은 하나의 영상에서 다른 영상으로의 관계를 학습하기 때문에 몇 개의 강조영상의 존재하더라도 이 정보 간의 시너지를 활용하는 영상 학습기법이 없는 현실이다.
예 교수 연구팀은 자체 개발한 ‘협조·생성적 적대신경망(Collaborative Generative Adversarial Network : CollaGAN)’이라는 기술을 이용해 여러 MRI 강조영상의 공통 특징 공간을 학습함으로써 확장성의 문제를 해결했다.
이를 통해 어떤 대조 영상의 생성이 가능한지와 불가능한지에 대한 질문과, 그에 대한 체계적인 대답 기법을 제안했다.
즉, 여러 개의 강조영상 중에서 임의의 순서 및 개수로 영상이 없어져도 남아있는 영상을 통해 사라진 영상을 복원하는 기법을 학습한 후 합성된 영상의 임상적 정확도를 평가해, 강조 영상 간 중요도를 자동으로 평가할 수 있는 원천 기술을 개발했다.
예 교수 연구팀은 건국대 문원진 교수 연구팀과의 협력을 통해 T1강조·T2강조 영상과 같이 내인성 강조영상은 다른 영상으로부터 정확한 합성이 가능하며, 합성된 강조영상이 실제 영상과 매우 유사하게 임상 정보를 표현하고 있다는 것을 확인했다.
연구팀은 확보한 합성 영상이 뇌종양 분할기법을 통해 뇌종양 범위를 파악하는데 유용한 정보를 제공한다는 것을 확인했다. 또한, 현재 많이 사용되는 합성 MRI 기법(synthetic MRI)에서 생기는 인공음영 영상도 자동 제거가 가능함이 증명됐다. 이 기술을 이용하면 추가적인 재촬영을 하지 않고도 필요한 대조 영상을 생성해 시간과 비용을 비약적으로 줄일 수 있을 것으로 기대된다.
건국대 영상의학과 문원진 교수는 “연구에서 개발한 방법을 이용해 인공지능을 통한 합성 영상을 임상현장에서 이용하면 재촬영으로 인한 환자의 불편을 최소화하고 진단정확도를 높여 전체의료비용 절감 효과를 가져올 것이다”라고 말했다.
예종철 교수는 “인공지능이 진단과 영상처리에 사용되는 현재의 응용 범위를 넘어서, 진단의 중요도를 선택하고 진단 규약을 계획하는 데 중요한 역할을 할 수 있는 것을 보여준 독창적인 연구이다”라고 말했다.
이 연구는 한국연구재단의 중견연구자지원사업을 받아 수행됐다.
□ 그림 설명
그림1. CollaGAN의 작동 원리의 예
2020.01.30 조회수 9969
재촬영 없이 MRI 강조영상 얻는 AI 기술 개발
우리 대학 바이오및뇌공학과 예종철 교수 연구팀 자기공명영상(magnetic resonance imaging: MRI)에서 재촬영 없이도 누락된 강조영상을 얻을 수 있는 인공지능 기술을 개발했다.
이 연구를 통해 각 질환별로 강조영상이 암의 진단에 미치는 영향을 객관적으로 밝힐 수 있으며, 실제 임상에서 고비용의 MRI를 효과적이고 체계적으로 활용할 수 있는 방안을 설계할 수 있을 것으로 기대된다.
이동욱 박사가 1 저자로 참여하고 건국대 의과대학 영상의학과 문원진 교수팀이 참여한 이번 연구 결과는 국제 학술지 ‘네이처 머신인테리젼스(Nature Machine Intelligence)’ 1월 18일 자 온라인판에 게재됐다. (논문명 : Assessing the importance of magnetic resonance contrasts using collaborative generative adversarial networks).
MRI는 엑스선 컴퓨터 단층촬영, 초음파와 더불어 임상 진단에서 중요한 역할을 하는 진단 장비이다. 특히 비침습적 방법으로 고해상도의 영상을 얻기 때문에 종양이나 병변을 관찰하며 진단하는데 매우 중요한 임상 정보를 제공한다. 이는 영상의 대조도 (contrast)를 다양하게 조절할 수 있는 MRI의 특징 덕분이다.
예를 들어 뇌종양을 진단하는 데 활용되는 T1·T2 강조영상, FLAIR 기법 영상, T1 조영증강 영상 등 여러 가지 대조 영상을 얻어 진단에 사용함으로써 종양을 찾을 수 있다.
하지만 실제 임상 환경에서는 강조영상을 모두 얻기 어려운 경우가 많다. 여러 장의 강조영상 촬영을 위해 촬영시간이 길어지기도 하고, 잡음이나 인공음영 발생으로 인해 진단에 사용하기 어려운 경우가 많기 때문이다.
또한, 뇌질환진단을 위한 MRI 검사는 의심 질환이 무엇인지에 따라 필수 강조영상이 달라지며, 이후 특정 질환으로 진단명이 좁혀지면서 부득이하게 누락된 강조영상을 확보하기 위한 재촬영이 필요한 경우가 많다. 이러한 상황에 의해 많은 시간과 비용이 소모된다.
최근 인공지능 분야에서 생성적 적대 신경망(Generative adversarial networks, GAN)이라는 딥러닝을 이용해 영상을 합성하는 기술이 많이 보고되고 있지만, 이 기술을 MRI 강조영상 합성에 사용하면 준비하고 미리 학습해야 하는 네트워크가 너무 많아지게 된다.
또한, 이러한 기법은 하나의 영상에서 다른 영상으로의 관계를 학습하기 때문에 몇 개의 강조영상의 존재하더라도 이 정보 간의 시너지를 활용하는 영상 학습기법이 없는 현실이다.
예 교수 연구팀은 자체 개발한 ‘협조·생성적 적대신경망(Collaborative Generative Adversarial Network : CollaGAN)’이라는 기술을 이용해 여러 MRI 강조영상의 공통 특징 공간을 학습함으로써 확장성의 문제를 해결했다.
이를 통해 어떤 대조 영상의 생성이 가능한지와 불가능한지에 대한 질문과, 그에 대한 체계적인 대답 기법을 제안했다.
즉, 여러 개의 강조영상 중에서 임의의 순서 및 개수로 영상이 없어져도 남아있는 영상을 통해 사라진 영상을 복원하는 기법을 학습한 후 합성된 영상의 임상적 정확도를 평가해, 강조 영상 간 중요도를 자동으로 평가할 수 있는 원천 기술을 개발했다.
예 교수 연구팀은 건국대 문원진 교수 연구팀과의 협력을 통해 T1강조·T2강조 영상과 같이 내인성 강조영상은 다른 영상으로부터 정확한 합성이 가능하며, 합성된 강조영상이 실제 영상과 매우 유사하게 임상 정보를 표현하고 있다는 것을 확인했다.
연구팀은 확보한 합성 영상이 뇌종양 분할기법을 통해 뇌종양 범위를 파악하는데 유용한 정보를 제공한다는 것을 확인했다. 또한, 현재 많이 사용되는 합성 MRI 기법(synthetic MRI)에서 생기는 인공음영 영상도 자동 제거가 가능함이 증명됐다. 이 기술을 이용하면 추가적인 재촬영을 하지 않고도 필요한 대조 영상을 생성해 시간과 비용을 비약적으로 줄일 수 있을 것으로 기대된다.
건국대 영상의학과 문원진 교수는 “연구에서 개발한 방법을 이용해 인공지능을 통한 합성 영상을 임상현장에서 이용하면 재촬영으로 인한 환자의 불편을 최소화하고 진단정확도를 높여 전체의료비용 절감 효과를 가져올 것이다”라고 말했다.
예종철 교수는 “인공지능이 진단과 영상처리에 사용되는 현재의 응용 범위를 넘어서, 진단의 중요도를 선택하고 진단 규약을 계획하는 데 중요한 역할을 할 수 있는 것을 보여준 독창적인 연구이다”라고 말했다.
이 연구는 한국연구재단의 중견연구자지원사업을 받아 수행됐다.
□ 그림 설명
그림1. CollaGAN의 작동 원리의 예
2020.01.30 조회수 9969 -
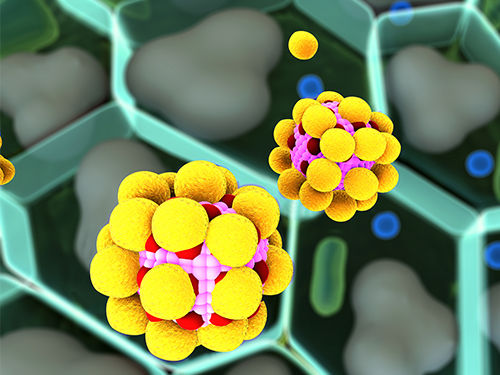 김지한 교수, 인공지능 이용한 다공성 물질 역설계 기술 개발
〈 김지한 교수 연구팀 〉
우리 대학 생명화학공학과 김지한 교수 연구팀이 인공지능을 활용해 원하는 물성의 다공성 물질을 역설계하는 방법을 개발했다.
김백준, 이상원 박사과정이 공동 1 저자로 참여한 이번 연구결과는 국제 학술지 ‘사이언스 어드밴시스(Science Advances)’ 1월 3일 자 온라인판에 게재됐다. (논문명 : Inverse Design of Porous Materials Using Artificial Neural Networks)
다공성 물질은 넓은 표면적과 풍부한 내부 공극(孔劇)을 가지고 있어 촉매, 기체 저장 및 분리, 센서, 약물 전달 등 다양한 분야에서 활용되고 있다.
기존에는 이러한 다공성 물질을 개발하기 위해 반복적인 실험을 통한 시행착오를 거치면서 시간과 비용이 많이 소모됐다. 이러한 낭비를 줄이기 위해 가상 구조를 스크리닝해 다공성 물질 개발을 가속화 하려는 시도들이 있었지만, 데이터베이스에 존재하지 않는 새로운 구조를 발견하지 못한다는 문제가 있었다.
최근에는 인공지능 기반의 역설계로 원하는 물성을 가진 물질을 개발하는 연구가 주목받고 있지만, 지금까지의 연구들은 단순한 소형 분자들 위주로 적용되고 있으며 복잡한 다공성 물질을 설계하는 연구는 보고되지 않았다.
김지한 교수 연구팀은 인공지능 기술과 분자 시뮬레이션 기술을 활용해 다공성 물질의 한 종류인 제올라이트 구조를 설계하는 방법을 개발했다.
연구팀은 인공지능 생성모델인 적대적 생성 신경망(GAN, Generative Adversarial Network)과 기존 분자 시뮬레이션에서 활용되는 3차원 그리드 데이터를 활용해 복잡한 다공성 물질의 특성을 인공지능이 학습하고 생성할 수 있도록 구조를 개발했다.
개발된 인공신경망 생성모델은 3차원 그리드로 이루어진 구조 정보와 흡착 물성 데이터를 같이 학습하게 되며, 학습 과정 안에서 흡착 물성을 빠르게 계산할 수 있다. 이를 통해 에너지 저장 소재의 특성을 효율적으로 학습할 수 있음을 증명했다.
또한, 연구팀은 인공지능 학습 과정에서 기존의 알려진 제올라이트 구조 중 일부를 제외해 학습시켰고, 그 결과 인공지능이 학습하지 않았던 구조들도 생성할 수 있음을 확인했다.
김지한 교수는“인공지능을 이용해 다공성 물질을 설계한 최초의 사례이다”라며 “기체 흡착 용도에 국한된 것이 아니라 다른 물성에도 쉽게 적용할 수 있어 촉매, 분리, 센서 등 다른 분야의 물질 개발에도 활용될 것으로 기대한다”라고 말했다.
이번 연구는 BK21, 한국연구재단 중견 연구자 지원 사업 그리고 에너지 클라우드 사업단의 지원을 받아 수행됐다.
□ 그림 설명
그림 1. 인공지능 기반 다공성 물질(제올라이트) 생성 개요도
2020.01.07 조회수 9919
김지한 교수, 인공지능 이용한 다공성 물질 역설계 기술 개발
〈 김지한 교수 연구팀 〉
우리 대학 생명화학공학과 김지한 교수 연구팀이 인공지능을 활용해 원하는 물성의 다공성 물질을 역설계하는 방법을 개발했다.
김백준, 이상원 박사과정이 공동 1 저자로 참여한 이번 연구결과는 국제 학술지 ‘사이언스 어드밴시스(Science Advances)’ 1월 3일 자 온라인판에 게재됐다. (논문명 : Inverse Design of Porous Materials Using Artificial Neural Networks)
다공성 물질은 넓은 표면적과 풍부한 내부 공극(孔劇)을 가지고 있어 촉매, 기체 저장 및 분리, 센서, 약물 전달 등 다양한 분야에서 활용되고 있다.
기존에는 이러한 다공성 물질을 개발하기 위해 반복적인 실험을 통한 시행착오를 거치면서 시간과 비용이 많이 소모됐다. 이러한 낭비를 줄이기 위해 가상 구조를 스크리닝해 다공성 물질 개발을 가속화 하려는 시도들이 있었지만, 데이터베이스에 존재하지 않는 새로운 구조를 발견하지 못한다는 문제가 있었다.
최근에는 인공지능 기반의 역설계로 원하는 물성을 가진 물질을 개발하는 연구가 주목받고 있지만, 지금까지의 연구들은 단순한 소형 분자들 위주로 적용되고 있으며 복잡한 다공성 물질을 설계하는 연구는 보고되지 않았다.
김지한 교수 연구팀은 인공지능 기술과 분자 시뮬레이션 기술을 활용해 다공성 물질의 한 종류인 제올라이트 구조를 설계하는 방법을 개발했다.
연구팀은 인공지능 생성모델인 적대적 생성 신경망(GAN, Generative Adversarial Network)과 기존 분자 시뮬레이션에서 활용되는 3차원 그리드 데이터를 활용해 복잡한 다공성 물질의 특성을 인공지능이 학습하고 생성할 수 있도록 구조를 개발했다.
개발된 인공신경망 생성모델은 3차원 그리드로 이루어진 구조 정보와 흡착 물성 데이터를 같이 학습하게 되며, 학습 과정 안에서 흡착 물성을 빠르게 계산할 수 있다. 이를 통해 에너지 저장 소재의 특성을 효율적으로 학습할 수 있음을 증명했다.
또한, 연구팀은 인공지능 학습 과정에서 기존의 알려진 제올라이트 구조 중 일부를 제외해 학습시켰고, 그 결과 인공지능이 학습하지 않았던 구조들도 생성할 수 있음을 확인했다.
김지한 교수는“인공지능을 이용해 다공성 물질을 설계한 최초의 사례이다”라며 “기체 흡착 용도에 국한된 것이 아니라 다른 물성에도 쉽게 적용할 수 있어 촉매, 분리, 센서 등 다른 분야의 물질 개발에도 활용될 것으로 기대한다”라고 말했다.
이번 연구는 BK21, 한국연구재단 중견 연구자 지원 사업 그리고 에너지 클라우드 사업단의 지원을 받아 수행됐다.
□ 그림 설명
그림 1. 인공지능 기반 다공성 물질(제올라이트) 생성 개요도
2020.01.07 조회수 9919 -
 박성준 박사과정, 2019 구글 PhD 펠로우 선정
〈 박성준 박사과정 〉
우리 대학 전산학부 박성준 박사과정(지도교수 오혜연)이 2019년 구글 PhD 자연어처리(Natural Language Processing) 부문 펠로우에 선정됐다.
2009년부터 시작된 구글 PhD 펠로우십 프로그램은 매년 컴퓨터 과학과 관련된 유망한 분야에서 연구 업적이 훌륭하고 미래가 유망한 대학원생을 발굴하고 지원하는 프로그램이다.
선정된 학생들에게는 장학금과 펠로우십 서밋 참여, 인턴십 기회, 구글 각 분야의 전문가 멘토의 연구 토의 및 피드백 등을 제공한다.
올해는 북미, 유럽, 아시아, 아프리카의 대학에서 50여 명의 박사과정 학생들이 선발됐으며, 아시아에서는 한국 학생 3명을 포함해 10명의 학생이 선발됐다.
박성준 박사과정은 기계학습 기반 자연어처리 기법을 활용한 전산심리치료(Computational Psychotherapy) 관련 연구 성과를 인정받아 구글 PhD 펠로우에 선정됐다.
또한, 기계학습 기반 자연어처리에서 널리 사용되는 어휘의 분산표상 학습 기법을 한국어에 적용하는 방법을 제안했고, 학습된 분산표상을 해석하는 방법을 2017, 2018년에 각각 자연어처리 분야 최고 수준의 국제학술대회 ACL(Annual Conference of the Association for Computational Linguistics), EMNLP(Conference on Empirical Methods in Natural Language Processing)에 발표했다.
박 박사과정은 이를 확장해 심리상담 대화록에서 내담자의 언어 반응을 내담자 요인에 따라 분류하는 기준 및 기계학습 모델을 제안해 자연어처리 분야 최고 수준의 국제학술대회 NAACL(Annual Conference of the North American Chapter of the Association for Computational Linguistics)에서 발표했다.
최근에는 인공신경망 기반 대화 생성 모델 개발, 텍스트에서 복합적인 감정 추출 및 예측, 전산 심리치료 애플리케이션 개발 연구 또한 현재 활발하게 진행하고 있다.
2019.09.16 조회수 10000
박성준 박사과정, 2019 구글 PhD 펠로우 선정
〈 박성준 박사과정 〉
우리 대학 전산학부 박성준 박사과정(지도교수 오혜연)이 2019년 구글 PhD 자연어처리(Natural Language Processing) 부문 펠로우에 선정됐다.
2009년부터 시작된 구글 PhD 펠로우십 프로그램은 매년 컴퓨터 과학과 관련된 유망한 분야에서 연구 업적이 훌륭하고 미래가 유망한 대학원생을 발굴하고 지원하는 프로그램이다.
선정된 학생들에게는 장학금과 펠로우십 서밋 참여, 인턴십 기회, 구글 각 분야의 전문가 멘토의 연구 토의 및 피드백 등을 제공한다.
올해는 북미, 유럽, 아시아, 아프리카의 대학에서 50여 명의 박사과정 학생들이 선발됐으며, 아시아에서는 한국 학생 3명을 포함해 10명의 학생이 선발됐다.
박성준 박사과정은 기계학습 기반 자연어처리 기법을 활용한 전산심리치료(Computational Psychotherapy) 관련 연구 성과를 인정받아 구글 PhD 펠로우에 선정됐다.
또한, 기계학습 기반 자연어처리에서 널리 사용되는 어휘의 분산표상 학습 기법을 한국어에 적용하는 방법을 제안했고, 학습된 분산표상을 해석하는 방법을 2017, 2018년에 각각 자연어처리 분야 최고 수준의 국제학술대회 ACL(Annual Conference of the Association for Computational Linguistics), EMNLP(Conference on Empirical Methods in Natural Language Processing)에 발표했다.
박 박사과정은 이를 확장해 심리상담 대화록에서 내담자의 언어 반응을 내담자 요인에 따라 분류하는 기준 및 기계학습 모델을 제안해 자연어처리 분야 최고 수준의 국제학술대회 NAACL(Annual Conference of the North American Chapter of the Association for Computational Linguistics)에서 발표했다.
최근에는 인공신경망 기반 대화 생성 모델 개발, 텍스트에서 복합적인 감정 추출 및 예측, 전산 심리치료 애플리케이션 개발 연구 또한 현재 활발하게 진행하고 있다.
2019.09.16 조회수 10000 -
 최성율 교수, 뉴로모픽 칩의 시냅스 구현
〈 최성율 교수 〉
우리 대학 전기및전자공학부 최성율 교수 연구팀이 멤리스터(Memristor) 소자의 구동 방식을 아날로그 형태로 변화해 뉴로모픽 칩의 시냅스로 활용할 수 있는 기술을 개발했다.
이 기술을 통해 기존의 디지털 비휘발성 메모리로만 이용되던 멤리스터를 아날로그 형태로 활용함으로써 인간의 뇌를 모사한 인공지능 컴퓨팅 칩인 뉴로모픽 칩의 상용화에 기여할 수 있을 것으로 기대된다.
장병철 박사(현 삼성전자 연구원), 김성규 박사(현 노스웨스턴대학), 양상윤 연구교수가 공동 1 저자로 참여하고 美 노스웨스턴 대학, KAIST 임성갑 교수가 공동으로 수행한 이번 연구는 나노과학 분야 국제 학술지 ‘나노 레터스 (Nano Letters)’ 1월 4일 온라인판에 게재됐다.
사람 뇌를 닮은 반도체로 알려진 뉴로모픽 칩은 기존의 반도체 칩이 갖는 전력 확보 문제를 해결할 수 있고 데이터 처리 과정을 통합할 수 있어 차세대 기술로 주목받고 있다.
멤리스터는 메모리와 레지스터의 합성어로, 메모리와 프로세스가 통합된 기능을 수행할 수 있다. 특히 뉴로모픽 칩 내부에 물리적 인공신경망을 가장 효과적으로 구현할 수 있는 크로스바 어레이(crossbar array) 제작에 최적인 소자로 알려져 있다.
물리적 인공신경망은 뉴런 회로와 이들의 연결부인 시냅스 소자로 구성되는데 뉴로모픽 칩 기반의 인공지능 연산을 수행할 때 각 시냅스 소자에서는 뉴런 간의 연결 강도를 나타내는 전도도 가중치가 아날로그 데이터로 저장 및 갱신돼야 한다.
그러나 기존 멤리스터들은 대부분 비휘발성 메모리 구현에 적합한 디지털의 특성을 가져 아날로그 방식의 구동에 한계가 있었고, 이로 인해 시냅스 소자로 응용하기 어려웠다.
최 교수 연구팀은 플라스틱 기판 위에 고분자 소재 기반의 유연 멤리스터를 제작하면서 소자 내부에 형성되는 전도성 금속 필라멘트 크기를 금속 원자 수준으로 얇게 조절하면 멤리스터의 동작이 디지털에서 아날로그 방식으로 변화하는 것을 발견했다.
연구팀은 이러한 현상을 이용해 멤리스터의 전도도 가중치를 연속적, 선형적으로 갱신할 수 있고 구부림 등의 기계적 변형 상태에서도 정상 동작하는 유연 멤리스터 시냅스 소자를 구현했다.
유연 멤리스터 시냅스로 구성된 인공신경망은 학습을 통해 사람의 얼굴을 효과적으로 인식해 분류할 수 있고 손상된 얼굴 이미지도 인식할 수 있음을 확인했다. 이를 통해 얼굴, 숫자, 사물 등의 인식을 효율적으로 수행할 수 있는 유연 뉴로모픽 칩 개발의 가능성을 확보했다.
최 교수는 “멤리스터 소자의 구동 방식이 디지털에서 아날로그로 변화되는 주요 원리를 밝힘으로써 다양한 멤리스터 소자들을 디지털 메모리 또는 시냅스 소자로 응용할 수 있는 길을 열었다”라며 “고성능 뉴로모픽 칩 개발의 가속화에 기여할 수 있을 것이다” 라고 말했다.
이번 연구는 과학기술정보통신부 한국연구재단 글로벌프론티어사업 중 (재)나노기판소프트일렉트로닉스 연구단의 지원을 받아 수행됐다.
□ 그림 설명
그림1. 플라스틱 기판 위에 제작된 유연 멤리스터 시냅스 소자 모식도
2019.02.11 조회수 8367
최성율 교수, 뉴로모픽 칩의 시냅스 구현
〈 최성율 교수 〉
우리 대학 전기및전자공학부 최성율 교수 연구팀이 멤리스터(Memristor) 소자의 구동 방식을 아날로그 형태로 변화해 뉴로모픽 칩의 시냅스로 활용할 수 있는 기술을 개발했다.
이 기술을 통해 기존의 디지털 비휘발성 메모리로만 이용되던 멤리스터를 아날로그 형태로 활용함으로써 인간의 뇌를 모사한 인공지능 컴퓨팅 칩인 뉴로모픽 칩의 상용화에 기여할 수 있을 것으로 기대된다.
장병철 박사(현 삼성전자 연구원), 김성규 박사(현 노스웨스턴대학), 양상윤 연구교수가 공동 1 저자로 참여하고 美 노스웨스턴 대학, KAIST 임성갑 교수가 공동으로 수행한 이번 연구는 나노과학 분야 국제 학술지 ‘나노 레터스 (Nano Letters)’ 1월 4일 온라인판에 게재됐다.
사람 뇌를 닮은 반도체로 알려진 뉴로모픽 칩은 기존의 반도체 칩이 갖는 전력 확보 문제를 해결할 수 있고 데이터 처리 과정을 통합할 수 있어 차세대 기술로 주목받고 있다.
멤리스터는 메모리와 레지스터의 합성어로, 메모리와 프로세스가 통합된 기능을 수행할 수 있다. 특히 뉴로모픽 칩 내부에 물리적 인공신경망을 가장 효과적으로 구현할 수 있는 크로스바 어레이(crossbar array) 제작에 최적인 소자로 알려져 있다.
물리적 인공신경망은 뉴런 회로와 이들의 연결부인 시냅스 소자로 구성되는데 뉴로모픽 칩 기반의 인공지능 연산을 수행할 때 각 시냅스 소자에서는 뉴런 간의 연결 강도를 나타내는 전도도 가중치가 아날로그 데이터로 저장 및 갱신돼야 한다.
그러나 기존 멤리스터들은 대부분 비휘발성 메모리 구현에 적합한 디지털의 특성을 가져 아날로그 방식의 구동에 한계가 있었고, 이로 인해 시냅스 소자로 응용하기 어려웠다.
최 교수 연구팀은 플라스틱 기판 위에 고분자 소재 기반의 유연 멤리스터를 제작하면서 소자 내부에 형성되는 전도성 금속 필라멘트 크기를 금속 원자 수준으로 얇게 조절하면 멤리스터의 동작이 디지털에서 아날로그 방식으로 변화하는 것을 발견했다.
연구팀은 이러한 현상을 이용해 멤리스터의 전도도 가중치를 연속적, 선형적으로 갱신할 수 있고 구부림 등의 기계적 변형 상태에서도 정상 동작하는 유연 멤리스터 시냅스 소자를 구현했다.
유연 멤리스터 시냅스로 구성된 인공신경망은 학습을 통해 사람의 얼굴을 효과적으로 인식해 분류할 수 있고 손상된 얼굴 이미지도 인식할 수 있음을 확인했다. 이를 통해 얼굴, 숫자, 사물 등의 인식을 효율적으로 수행할 수 있는 유연 뉴로모픽 칩 개발의 가능성을 확보했다.
최 교수는 “멤리스터 소자의 구동 방식이 디지털에서 아날로그로 변화되는 주요 원리를 밝힘으로써 다양한 멤리스터 소자들을 디지털 메모리 또는 시냅스 소자로 응용할 수 있는 길을 열었다”라며 “고성능 뉴로모픽 칩 개발의 가속화에 기여할 수 있을 것이다” 라고 말했다.
이번 연구는 과학기술정보통신부 한국연구재단 글로벌프론티어사업 중 (재)나노기판소프트일렉트로닉스 연구단의 지원을 받아 수행됐다.
□ 그림 설명
그림1. 플라스틱 기판 위에 제작된 유연 멤리스터 시냅스 소자 모식도
2019.02.11 조회수 8367 -
 한동수, 신진우 교수, 느린 인터넷 환경에서도 고화질 영상 감상 기술 개발
〈 (왼쪽부터) 김재홍, 정영목 석사과정, 여현호 박사과정, 한동수, 신진우 교수 〉
우리 대학 전기및전자공학부 신진우, 한동수 교수 연구팀이 딥러닝 기술을 이용한 인터넷 비디오 전송 기술을 개발했다.
여현호, 정영목, 김재홍 학생이 주도한 이번 연구 결과는 격년으로 개최되는 컴퓨터 시스템 분야의 유명 학술회의인 ‘유즈닉스 OSDI(USENIX OSDI)’에서 10월 10일 발표됐고 현재 국제 특허 출원을 완료했다.
이 기술은 유튜브, 넷플릭스 등에서 비디오를 사용자에게 전송할 때 사용하는 적응형 스트리밍(HTTP adaptive streaming) 비디오 전송기술과 딥러닝 기술인 심층 콘볼루션 신경망(CNN) 기반의 초해상화를 접목한 새로운 방식이다.
이는 열악한 인터넷 환경에서도 고품질, 고화질(HD)의 비디오 시청이 가능할 뿐 아니라 4K, AV/VR 등을 시청할 수 있는 새로운 기반 기술이 될 것으로 기대된다.
기존의 적응형 스트리밍은 시시각각 변화하는 인터넷 대역폭에 맞춰 스트리밍 중인 비디오 화질을 실시간으로 조절한다. 이를 위해 다양한 알고리즘이 연구되고 있으나 네트워크 환경이 좋지 않을 때는 어느 알고리즘이라도 고화질의 비디오를 감상할 수 없다는 한계가 있다.
연구팀은 적응형 스트리밍에 초해상화를 접목해 인터넷 대역폭에 의존하는 기존 적응형 스트리밍의 한계를 극복했다. 기존 기술은 비디오를 시청 시 긴 영상을 짧은 시간의 여러 비디오 조각으로 나눠 다운받는다. 이를 위해 비디오를 제공하는 서버에서는 비디오를 미리 일정 시간 길이로 나눠 준비해놓는 방식이다.
연구팀이 새롭게 개발한 시스템은 추가로 신경망 조각을 비디오 조각과 같이 다운받게 했다. 이를 위해 비디오 서버에서는 각 비디오에 대해 학습이 된 신경망을 제공하며 또 사용자 컴퓨터의 사양을 고려해 다양한 크기의 신경망을 제공한다.
제일 큰 신경망의 크기는 총 2메가바이트(MB)이며 비디오에 비해 상당히 작은 크기이다. 신경망을 사용자 비디오 플레이어에서 다운받을 때는 여러 개의 조각으로 나눠 다운받으며 신경망의 일부만 다운받아도 조금 떨어지는 성능의 초해상화 기술을 이용할 수 있도록 설계했다.
사용자의 컴퓨터에서는 동영상 시청과 함께 병렬적으로 심층 콘볼루션 신경망(CNN) 기반의 초해상화 기술을 사용해 비디오 플레이어 버퍼에 저장된 저화질 비디오를 고화질로 바꾸게 된다. 모든 과정은 실시간으로 이뤄지며 이를 통해 사용자들이 고화질의 비디오를 시청할 수 있다.
연구팀이 개발한 시스템을 이용하면 최대 26.9%의 적은 인터넷 대역폭으로도 최신 적응형 스트리밍과 같은 체감 품질(QoE, Quality of Experience)을 제공할 수 있다. 또한 같은 인터넷 대역폭이 주어진 경우에는 최신 적응형 스트리밍보다 평균 40% 높은 체감 품질을 제공할 수 있다.
이 시스템은 딥러닝 방식을 이용해 기존의 비디오 압축 방식보다 더 많은 압축을 이뤄낸 것으로 볼 수 있다. 연구팀의 기술은 콘볼루션 신경망 기반의 초해상화를 인터넷 비디오에 적용한 차세대 인터넷 비디오 시스템으로 권위 잇는 학회로부터 효용성을 인정받았다.
한 교수는 “지금은 데스크톱에서만 구현했지만 향후 모바일 기기에서도 작동하도록 발전시킬 예정이다”며 “이 기술은 현재 유튜브, 넷플릭스 등 스트리밍 기업에서 사용하는 비디오 전송 시스템에 적용한 것으로 실용성에 큰 의의가 있다”고 말했다.
이번 연구는 과학기술정보통신부 정보통신기술진흥센터(IITP) 방송통신연구개발 사업의 지원을 받아 수행됐다.
비디오 자료 링크 주소 1.
https://www.dropbox.com/sh/z2hvw1iv1459698/AADk3NB5EBgDhv3J4aiZo9nta?dl=0&lst =
□ 그림 설명
그림1. 기술이 적용되기 전 화질(좌)과 적용된 후 화질 비교(우)
그림2. 기술 개념도
그림3. 비디오 서버로부터 비디오가 전송된 후 저화질의 비디오가 고화질의 비디오로 변환되는 과정
2018.10.30 조회수 9048
한동수, 신진우 교수, 느린 인터넷 환경에서도 고화질 영상 감상 기술 개발
〈 (왼쪽부터) 김재홍, 정영목 석사과정, 여현호 박사과정, 한동수, 신진우 교수 〉
우리 대학 전기및전자공학부 신진우, 한동수 교수 연구팀이 딥러닝 기술을 이용한 인터넷 비디오 전송 기술을 개발했다.
여현호, 정영목, 김재홍 학생이 주도한 이번 연구 결과는 격년으로 개최되는 컴퓨터 시스템 분야의 유명 학술회의인 ‘유즈닉스 OSDI(USENIX OSDI)’에서 10월 10일 발표됐고 현재 국제 특허 출원을 완료했다.
이 기술은 유튜브, 넷플릭스 등에서 비디오를 사용자에게 전송할 때 사용하는 적응형 스트리밍(HTTP adaptive streaming) 비디오 전송기술과 딥러닝 기술인 심층 콘볼루션 신경망(CNN) 기반의 초해상화를 접목한 새로운 방식이다.
이는 열악한 인터넷 환경에서도 고품질, 고화질(HD)의 비디오 시청이 가능할 뿐 아니라 4K, AV/VR 등을 시청할 수 있는 새로운 기반 기술이 될 것으로 기대된다.
기존의 적응형 스트리밍은 시시각각 변화하는 인터넷 대역폭에 맞춰 스트리밍 중인 비디오 화질을 실시간으로 조절한다. 이를 위해 다양한 알고리즘이 연구되고 있으나 네트워크 환경이 좋지 않을 때는 어느 알고리즘이라도 고화질의 비디오를 감상할 수 없다는 한계가 있다.
연구팀은 적응형 스트리밍에 초해상화를 접목해 인터넷 대역폭에 의존하는 기존 적응형 스트리밍의 한계를 극복했다. 기존 기술은 비디오를 시청 시 긴 영상을 짧은 시간의 여러 비디오 조각으로 나눠 다운받는다. 이를 위해 비디오를 제공하는 서버에서는 비디오를 미리 일정 시간 길이로 나눠 준비해놓는 방식이다.
연구팀이 새롭게 개발한 시스템은 추가로 신경망 조각을 비디오 조각과 같이 다운받게 했다. 이를 위해 비디오 서버에서는 각 비디오에 대해 학습이 된 신경망을 제공하며 또 사용자 컴퓨터의 사양을 고려해 다양한 크기의 신경망을 제공한다.
제일 큰 신경망의 크기는 총 2메가바이트(MB)이며 비디오에 비해 상당히 작은 크기이다. 신경망을 사용자 비디오 플레이어에서 다운받을 때는 여러 개의 조각으로 나눠 다운받으며 신경망의 일부만 다운받아도 조금 떨어지는 성능의 초해상화 기술을 이용할 수 있도록 설계했다.
사용자의 컴퓨터에서는 동영상 시청과 함께 병렬적으로 심층 콘볼루션 신경망(CNN) 기반의 초해상화 기술을 사용해 비디오 플레이어 버퍼에 저장된 저화질 비디오를 고화질로 바꾸게 된다. 모든 과정은 실시간으로 이뤄지며 이를 통해 사용자들이 고화질의 비디오를 시청할 수 있다.
연구팀이 개발한 시스템을 이용하면 최대 26.9%의 적은 인터넷 대역폭으로도 최신 적응형 스트리밍과 같은 체감 품질(QoE, Quality of Experience)을 제공할 수 있다. 또한 같은 인터넷 대역폭이 주어진 경우에는 최신 적응형 스트리밍보다 평균 40% 높은 체감 품질을 제공할 수 있다.
이 시스템은 딥러닝 방식을 이용해 기존의 비디오 압축 방식보다 더 많은 압축을 이뤄낸 것으로 볼 수 있다. 연구팀의 기술은 콘볼루션 신경망 기반의 초해상화를 인터넷 비디오에 적용한 차세대 인터넷 비디오 시스템으로 권위 잇는 학회로부터 효용성을 인정받았다.
한 교수는 “지금은 데스크톱에서만 구현했지만 향후 모바일 기기에서도 작동하도록 발전시킬 예정이다”며 “이 기술은 현재 유튜브, 넷플릭스 등 스트리밍 기업에서 사용하는 비디오 전송 시스템에 적용한 것으로 실용성에 큰 의의가 있다”고 말했다.
이번 연구는 과학기술정보통신부 정보통신기술진흥센터(IITP) 방송통신연구개발 사업의 지원을 받아 수행됐다.
비디오 자료 링크 주소 1.
https://www.dropbox.com/sh/z2hvw1iv1459698/AADk3NB5EBgDhv3J4aiZo9nta?dl=0&lst =
□ 그림 설명
그림1. 기술이 적용되기 전 화질(좌)과 적용된 후 화질 비교(우)
그림2. 기술 개념도
그림3. 비디오 서버로부터 비디오가 전송된 후 저화질의 비디오가 고화질의 비디오로 변환되는 과정
2018.10.30 조회수 9048 -
 이흥규 교수, 인공신경망 기반 워터마킹 기술 개발
〈 (왼쪽부터) 강지현,문승민,지상근 박사과정, 이흥규 교수 〉
우리 대학 전산학부 이흥규 교수 연구팀이 인공신경망을 이용해 워터마크를 영상에 삽입 및 검출하는 기술을 개발했다.
인공신경망 기반 워터마킹 기술은 3일부터 홈페이지를 통해 시범 운영되고 있다.( http://watermark.kaist.ac.kr )
이번 웹 서비스는 연구실 수준으로만 진행되던 기술들을 다년간의 연구개발을 통해 일반에 공개함으로써 특정 조건의 실험실 환경이 아닌 조건이 변화하는 실제 환경에서 적용된다.
이를 통해 인공신경망을 기반으로 하는 새로운 접근 기법의 성능을 검증하고 기존 한계점을 극복할 수 있는 연구 방향을 제시하는 초석이 될 것으로 기대된다.
현재까지 개발된 기존 워터마킹 기술은 모두 공격 유형, 세기 등 특정 조건을 사전에 정하고 이를 만족시키도록 설계 및 구현됐다. 따라서 다양한 공격 유형이 존재하는 실제 환경에 사용하기에는 실용적 측면, 기술 확장성, 유용성 등에 한계가 있었다.
또한 워터마크 제거, 복사, 대체 등의 해킹 기술 발전으로 인해 기술 자체의 보안 취약성에도 문제가 있었다.
연구팀의 웹 서비스에서는 ▲인공신경망 학습을 통한 새로운 공격에 대응하고 ▲인공신경망의 비선형적인 특성을 통해 높은 보안성을 가진 인공신경망 기반 2D 영상 워터마킹 기법 ▲다양한 시점 변환이 발생하더라도 영상 보호가 가능한 DIBR 3D 영상 워터마킹 기법 ▲워터마크 삽입으로 인한 시각피로도 상승을 최소화하는 S3D 영상 워터마킹 기법을 제공한다.
연구팀은 다수의 연구 결과들을 기반으로 해당 웹 서비스 기술을 구현했다. 연구팀의 2D 영상 워터마킹 기법은 최초의 인공신경망 기반 워터마킹 기법으로 이미지에 가해질 수 있는 다양한 공격을 이용해 인공신경망을 학습함으로써 강인성을 획득한다.
동시에 인공신경망의 심층구조를 통해 워터마크 해킹 공격에 대한 높은 보안성을 획득함으로써 기존의 보안 취약점을 대폭 개선했다. 고부가가치를 가지는 3D 영상 보안을 위한 워터마킹 기법도 개발해 웹 서비스로 제공한다.
사용자는 2D 영상 또는 3D 영상을 웹 서비스에 업로드 해 워터마크를 삽입하고 추후 필요시 삽입한 워터마크를 검출함으로써 각종 분쟁 해결에 활용할 수 있다.
또한 이 기술은 압축 등의 공격을 가상으로 진행하는 시뮬레이션 툴과 워터마크 삽입 세기 조절, 그리고 워터마크 삽입으로 인한 영상품질 비교 등의 서비스를 함께 제공한다.
이번 연구는 기술 활용 모델에 따라 요구되는 다양한 견고성에 따라 유연하게 추가 수정(修正) 구현 가능하고 해킹에 견고하게 설계됨으로써 워터마킹 기술 유용성을 극대화했다.
이에 따라 개발 기술은 향후 인증, 진위 판별, 유통 추적이나 저작권 분야 등에서 다양한 콘텐츠를 사용한 활용이 가능하다. 향후 각종 영상물들의 불법 활용으로 인해 발생하는 사회경제적 손실을 줄이고 콘텐츠 산업의 성장과 디지털 사회 선진화에 기여할 것으로 기대된다.
연구팀은 개발된 기술은 다양한 공격 유형에 적응적으로 대응하며 상용 가능한 수준의 기술 신뢰도를 보인다고 밝혔다.
이흥규 교수는 “영상 관련 각종 분쟁들이 저작권에 국한되던 종전의 범위를 넘어 최근 가짜 영상 유통에 따른 진위 판별, 인증, 무결성 검사, 유통 추적 등으로 관심 분야가 급속히 커지고 있다”며 “인공지능 기술을 활용해 기존 워터마킹 기법들의 기술적인 한계점을 해결할 수 있는 디지털 워터마킹 연구를 선도하겠다”고 말했다.
이번 연구는 한국연구재단이 추진하는 중견연구지원사업의 지원으로 수행됐다.
□ 그림 설명
그림1.2D 영상 워터마킹 기법을 이용한 영상 예제
그림2.S3D 영상 워터마킹 기법을 이용한 영상 예제
2018.09.11 조회수 7280
이흥규 교수, 인공신경망 기반 워터마킹 기술 개발
〈 (왼쪽부터) 강지현,문승민,지상근 박사과정, 이흥규 교수 〉
우리 대학 전산학부 이흥규 교수 연구팀이 인공신경망을 이용해 워터마크를 영상에 삽입 및 검출하는 기술을 개발했다.
인공신경망 기반 워터마킹 기술은 3일부터 홈페이지를 통해 시범 운영되고 있다.( http://watermark.kaist.ac.kr )
이번 웹 서비스는 연구실 수준으로만 진행되던 기술들을 다년간의 연구개발을 통해 일반에 공개함으로써 특정 조건의 실험실 환경이 아닌 조건이 변화하는 실제 환경에서 적용된다.
이를 통해 인공신경망을 기반으로 하는 새로운 접근 기법의 성능을 검증하고 기존 한계점을 극복할 수 있는 연구 방향을 제시하는 초석이 될 것으로 기대된다.
현재까지 개발된 기존 워터마킹 기술은 모두 공격 유형, 세기 등 특정 조건을 사전에 정하고 이를 만족시키도록 설계 및 구현됐다. 따라서 다양한 공격 유형이 존재하는 실제 환경에 사용하기에는 실용적 측면, 기술 확장성, 유용성 등에 한계가 있었다.
또한 워터마크 제거, 복사, 대체 등의 해킹 기술 발전으로 인해 기술 자체의 보안 취약성에도 문제가 있었다.
연구팀의 웹 서비스에서는 ▲인공신경망 학습을 통한 새로운 공격에 대응하고 ▲인공신경망의 비선형적인 특성을 통해 높은 보안성을 가진 인공신경망 기반 2D 영상 워터마킹 기법 ▲다양한 시점 변환이 발생하더라도 영상 보호가 가능한 DIBR 3D 영상 워터마킹 기법 ▲워터마크 삽입으로 인한 시각피로도 상승을 최소화하는 S3D 영상 워터마킹 기법을 제공한다.
연구팀은 다수의 연구 결과들을 기반으로 해당 웹 서비스 기술을 구현했다. 연구팀의 2D 영상 워터마킹 기법은 최초의 인공신경망 기반 워터마킹 기법으로 이미지에 가해질 수 있는 다양한 공격을 이용해 인공신경망을 학습함으로써 강인성을 획득한다.
동시에 인공신경망의 심층구조를 통해 워터마크 해킹 공격에 대한 높은 보안성을 획득함으로써 기존의 보안 취약점을 대폭 개선했다. 고부가가치를 가지는 3D 영상 보안을 위한 워터마킹 기법도 개발해 웹 서비스로 제공한다.
사용자는 2D 영상 또는 3D 영상을 웹 서비스에 업로드 해 워터마크를 삽입하고 추후 필요시 삽입한 워터마크를 검출함으로써 각종 분쟁 해결에 활용할 수 있다.
또한 이 기술은 압축 등의 공격을 가상으로 진행하는 시뮬레이션 툴과 워터마크 삽입 세기 조절, 그리고 워터마크 삽입으로 인한 영상품질 비교 등의 서비스를 함께 제공한다.
이번 연구는 기술 활용 모델에 따라 요구되는 다양한 견고성에 따라 유연하게 추가 수정(修正) 구현 가능하고 해킹에 견고하게 설계됨으로써 워터마킹 기술 유용성을 극대화했다.
이에 따라 개발 기술은 향후 인증, 진위 판별, 유통 추적이나 저작권 분야 등에서 다양한 콘텐츠를 사용한 활용이 가능하다. 향후 각종 영상물들의 불법 활용으로 인해 발생하는 사회경제적 손실을 줄이고 콘텐츠 산업의 성장과 디지털 사회 선진화에 기여할 것으로 기대된다.
연구팀은 개발된 기술은 다양한 공격 유형에 적응적으로 대응하며 상용 가능한 수준의 기술 신뢰도를 보인다고 밝혔다.
이흥규 교수는 “영상 관련 각종 분쟁들이 저작권에 국한되던 종전의 범위를 넘어 최근 가짜 영상 유통에 따른 진위 판별, 인증, 무결성 검사, 유통 추적 등으로 관심 분야가 급속히 커지고 있다”며 “인공지능 기술을 활용해 기존 워터마킹 기법들의 기술적인 한계점을 해결할 수 있는 디지털 워터마킹 연구를 선도하겠다”고 말했다.
이번 연구는 한국연구재단이 추진하는 중견연구지원사업의 지원으로 수행됐다.
□ 그림 설명
그림1.2D 영상 워터마킹 기법을 이용한 영상 예제
그림2.S3D 영상 워터마킹 기법을 이용한 영상 예제
2018.09.11 조회수 7280 -
 예종철 교수, 인공지능 블랙박스의 원리 밝혀
〈 예종철 교수, 한요섭 연구원, 차은주 연구원 〉
우리 대학 바이오및뇌공학과 예종철 석좌교수 연구팀이 인공지능의 기하학적인 구조를 규명하고 이를 통해 의료영상 및 정밀분야에 활용 가능한 고성능 인공신경망 제작의 수학적인 원리를 밝혔다.
연구팀의 ‘심층 합성곱 프레임렛(Deep Convolutional Framelets)’이라는 새로운 조화분석학적 기술은 인공지능의 블랙박스로 알려진 심층 신경망의 수학적 원리를 밝혀 기존 심층 신경망 구조의 단점을 보완하고 이를 다양하게 응용 가능할 것으로 기대된다.
예종철 석좌교수가 주도하고 한요섭, 차은주 박사과정이 참여한 이번 연구는 응용수학 분야 국제 학술지 ‘사이암 저널 온 이매징 사이언스(SIAM Journal on Imaging Sciences)’ 4월 26일자 온라인 판에 게재됐다.
심층신경망은 최근 폭발적으로 성장하는 인공지능의 핵심을 이루는 딥 러닝의 대표적인 구현 방법이다. 이를 이용한 영상, 음성 인식 및 영상처리 기법, 바둑, 체스 등은 이미 사람의 능력을 뛰어넘고 있으며 현재 4차 산업혁명의 핵심기술로 알려져 있다.
그러나 이러한 심층신경망은 그 뛰어난 성능에도 불구하고 정확한 동작원리가 밝혀지지 않아 예상하지 못한 결과가 나오거나 오류가 발생하는 문제가 있다. 이로 인해 ‘설명 가능한 인공지능(explainable AI: XAI)’에 대한 사회적, 기술적 요구가 커지고 있다.
연구팀은 심층신경망의 구조가 얻어지는 고차원 공간에서의 기하학적 구조를 찾기 위해 노력했다. 그 결과 기존의 신호처리 분야에서 집중 연구된 고차원 구조인 행켈구조 행렬(Hankel matrix)을 기저함수로 분해하는 과정에서 심층신경망 구조가 나오는 것을 발견했다.
행켈 행렬이 분해되는 과정에서 기저함수는 국지기저함수(local basis)와 광역기저함수(non-local basis)로 나눠진다. 연구팀은 광역기저함수와 국지기저함수가 각각 인공지능의 풀링(pooling)과 필터링(filtering) 역할을 한다는 것을 밝혔다.
기존에는 인공지능을 구현하기 위한 심층신경망을 구성할 때 구체적인 작동 원리를 모른 채 실험적으로 구현했다면, 연구팀은 신호를 효과적으로 나타내는 고차원 공간인 행켈 행렬를 찾고 이를 분리하는 방식을 통해 필터링, 풀링 구조를 얻는 이론적인 구조를 제시한 것이다.
이러한 성질을 이용하면 입력신호의 복잡성에 따라 기저함수의 개수와 심층신경망의 깊이를 정해 원하는 심층신경망의 구조를 제시할 수 있다.
연구팀은 수학적 원리를 통해 제안된 인공신경망 구조를 영상잡음제거, 영상 화소복원 및 의료영상 복원 문제에 적용했고 매우 우수한 성능을 보임을 확인했다.
예종철 교수는 “시행착오를 반복해 설계하는 기존의 심층신경망과는 달리 원하는 응용에 따라 최적화된 심층신경망구조를 수학적 원리로 디자인하고 그 영향을 예측할 수 있다”며 “이 결과를 통해 의료 영상 등 설명 가능한 인공지능이 필요한 다양한 분야에 응용될 수 있다”고 말했다.
이번 연구는 과학기술정보통신부의 중견연구자지원사업(도약연구) 및 뇌과학원천기술사업의 지원을 받아 수행됐다.
□ 그림 설명
그림1. 수학적인 원리를 이용한 심층신경망의 설계 예시
그림2. 영상잡음제거 결과
그림3. 영상에서 80% 화소가 사라진 경우 인공신경망을 통해 복원한 결과
2018.05.10 조회수 14818
예종철 교수, 인공지능 블랙박스의 원리 밝혀
〈 예종철 교수, 한요섭 연구원, 차은주 연구원 〉
우리 대학 바이오및뇌공학과 예종철 석좌교수 연구팀이 인공지능의 기하학적인 구조를 규명하고 이를 통해 의료영상 및 정밀분야에 활용 가능한 고성능 인공신경망 제작의 수학적인 원리를 밝혔다.
연구팀의 ‘심층 합성곱 프레임렛(Deep Convolutional Framelets)’이라는 새로운 조화분석학적 기술은 인공지능의 블랙박스로 알려진 심층 신경망의 수학적 원리를 밝혀 기존 심층 신경망 구조의 단점을 보완하고 이를 다양하게 응용 가능할 것으로 기대된다.
예종철 석좌교수가 주도하고 한요섭, 차은주 박사과정이 참여한 이번 연구는 응용수학 분야 국제 학술지 ‘사이암 저널 온 이매징 사이언스(SIAM Journal on Imaging Sciences)’ 4월 26일자 온라인 판에 게재됐다.
심층신경망은 최근 폭발적으로 성장하는 인공지능의 핵심을 이루는 딥 러닝의 대표적인 구현 방법이다. 이를 이용한 영상, 음성 인식 및 영상처리 기법, 바둑, 체스 등은 이미 사람의 능력을 뛰어넘고 있으며 현재 4차 산업혁명의 핵심기술로 알려져 있다.
그러나 이러한 심층신경망은 그 뛰어난 성능에도 불구하고 정확한 동작원리가 밝혀지지 않아 예상하지 못한 결과가 나오거나 오류가 발생하는 문제가 있다. 이로 인해 ‘설명 가능한 인공지능(explainable AI: XAI)’에 대한 사회적, 기술적 요구가 커지고 있다.
연구팀은 심층신경망의 구조가 얻어지는 고차원 공간에서의 기하학적 구조를 찾기 위해 노력했다. 그 결과 기존의 신호처리 분야에서 집중 연구된 고차원 구조인 행켈구조 행렬(Hankel matrix)을 기저함수로 분해하는 과정에서 심층신경망 구조가 나오는 것을 발견했다.
행켈 행렬이 분해되는 과정에서 기저함수는 국지기저함수(local basis)와 광역기저함수(non-local basis)로 나눠진다. 연구팀은 광역기저함수와 국지기저함수가 각각 인공지능의 풀링(pooling)과 필터링(filtering) 역할을 한다는 것을 밝혔다.
기존에는 인공지능을 구현하기 위한 심층신경망을 구성할 때 구체적인 작동 원리를 모른 채 실험적으로 구현했다면, 연구팀은 신호를 효과적으로 나타내는 고차원 공간인 행켈 행렬를 찾고 이를 분리하는 방식을 통해 필터링, 풀링 구조를 얻는 이론적인 구조를 제시한 것이다.
이러한 성질을 이용하면 입력신호의 복잡성에 따라 기저함수의 개수와 심층신경망의 깊이를 정해 원하는 심층신경망의 구조를 제시할 수 있다.
연구팀은 수학적 원리를 통해 제안된 인공신경망 구조를 영상잡음제거, 영상 화소복원 및 의료영상 복원 문제에 적용했고 매우 우수한 성능을 보임을 확인했다.
예종철 교수는 “시행착오를 반복해 설계하는 기존의 심층신경망과는 달리 원하는 응용에 따라 최적화된 심층신경망구조를 수학적 원리로 디자인하고 그 영향을 예측할 수 있다”며 “이 결과를 통해 의료 영상 등 설명 가능한 인공지능이 필요한 다양한 분야에 응용될 수 있다”고 말했다.
이번 연구는 과학기술정보통신부의 중견연구자지원사업(도약연구) 및 뇌과학원천기술사업의 지원을 받아 수행됐다.
□ 그림 설명
그림1. 수학적인 원리를 이용한 심층신경망의 설계 예시
그림2. 영상잡음제거 결과
그림3. 영상에서 80% 화소가 사라진 경우 인공신경망을 통해 복원한 결과
2018.05.10 조회수 14818 -
 유회준 교수, 딥러닝용 AI 반도체 개발
우리대학 전기및전자공학부 유회준 교수 연구팀이 스타트업 '유엑스 팩토리'와 함께 가변 인공신경망 기술을 적용해 딥러닝을 효율적으로 처리하는 AI 반도체를 개발했다. 딥러닝이란 컴퓨터가 마치 사람처럼 스스로 학습할 수 있도록 인공신경망을 기반으로 구축한 '기계 학습' 기술이다.
유 교수 연구팀이 개발한 새로운 칩은 반도체 안에서 인공신경망의 무게 정밀도를 조절함으로써 에너지 효율과 정확도를 조절한다. 1비트부터 16비트까지 소프트웨어로 간편하게 조절하면서 상황에 맞춰 최적화된 동작을 얻어낸다. 하나의 칩이지만 '콘볼루션 신경망'(CNN)과 '재귀 신경망'(RNN)을 동시에 처리할 수 있다. CNN은 이미지를 분류나 탐지하는 데 쓰이며, RNN은 주로 시간의 흐름에 따라 변화하는 영상과 음성 등 데이터 학습에 적합하다. 또 통합 신경망 프로세서(UNPU)를 통해 인식 대상에 따라 에너지효율과 정확도를 다르게 설정하는 것도 가능하다.
모바일에서 AI 기술을 구현하려면 고속 연산을 '저전력'으로 처리해야 한다. 그렇지 않으면 한꺼번에 많은 정보를 처리하면서 발생하는 발열로 인해 배터리 폭발 등의 사고가 일어날 수 있기 때문이다. 연구팀에 따르면 이번 칩은 세계 최고 수준 모바일용 AI 칩 대비 CNN과 RNN 연산 성능이 각각 1.15배, 13.8배이 달한다. 에너지효율도 40% 높은 것으로 나타났다.
스마트폰 카메라를 통해 사람의 얼굴 표정을 인식해 행복, 슬픔, 놀람, 공포, 무표정 등 7가지의 감정을 자동으로 인식하는 감정인식 시스템도 개발됐다. 이 시스템은 감정 상태를 스마트폰 상에 실시간으로 표시한다. 유 교수 연구팀의 이번 연구는 지난 13일 미국 샌프란시스코에서 열린 국제고체회로설계학회(ISSCC)에서 발표됐다.
유회준 교수는 "기술 상용화에는 1년 정도 더 걸릴 전망"이라며 " 모바일에서 AI를 구현하기 위해 저전력으로 가속하는 반도체를 개발했으며, 향후 물체인식, 감정인식, 동작인식, 자동 번역 등 다양하게 응용될 것으로 기대된다"고 설명했다.
2018.02.26 조회수 12272
유회준 교수, 딥러닝용 AI 반도체 개발
우리대학 전기및전자공학부 유회준 교수 연구팀이 스타트업 '유엑스 팩토리'와 함께 가변 인공신경망 기술을 적용해 딥러닝을 효율적으로 처리하는 AI 반도체를 개발했다. 딥러닝이란 컴퓨터가 마치 사람처럼 스스로 학습할 수 있도록 인공신경망을 기반으로 구축한 '기계 학습' 기술이다.
유 교수 연구팀이 개발한 새로운 칩은 반도체 안에서 인공신경망의 무게 정밀도를 조절함으로써 에너지 효율과 정확도를 조절한다. 1비트부터 16비트까지 소프트웨어로 간편하게 조절하면서 상황에 맞춰 최적화된 동작을 얻어낸다. 하나의 칩이지만 '콘볼루션 신경망'(CNN)과 '재귀 신경망'(RNN)을 동시에 처리할 수 있다. CNN은 이미지를 분류나 탐지하는 데 쓰이며, RNN은 주로 시간의 흐름에 따라 변화하는 영상과 음성 등 데이터 학습에 적합하다. 또 통합 신경망 프로세서(UNPU)를 통해 인식 대상에 따라 에너지효율과 정확도를 다르게 설정하는 것도 가능하다.
모바일에서 AI 기술을 구현하려면 고속 연산을 '저전력'으로 처리해야 한다. 그렇지 않으면 한꺼번에 많은 정보를 처리하면서 발생하는 발열로 인해 배터리 폭발 등의 사고가 일어날 수 있기 때문이다. 연구팀에 따르면 이번 칩은 세계 최고 수준 모바일용 AI 칩 대비 CNN과 RNN 연산 성능이 각각 1.15배, 13.8배이 달한다. 에너지효율도 40% 높은 것으로 나타났다.
스마트폰 카메라를 통해 사람의 얼굴 표정을 인식해 행복, 슬픔, 놀람, 공포, 무표정 등 7가지의 감정을 자동으로 인식하는 감정인식 시스템도 개발됐다. 이 시스템은 감정 상태를 스마트폰 상에 실시간으로 표시한다. 유 교수 연구팀의 이번 연구는 지난 13일 미국 샌프란시스코에서 열린 국제고체회로설계학회(ISSCC)에서 발표됐다.
유회준 교수는 "기술 상용화에는 1년 정도 더 걸릴 전망"이라며 " 모바일에서 AI를 구현하기 위해 저전력으로 가속하는 반도체를 개발했으며, 향후 물체인식, 감정인식, 동작인식, 자동 번역 등 다양하게 응용될 것으로 기대된다"고 설명했다.
2018.02.26 조회수 12272 -
 김문철 교수, 인공지능 통해 풀HD영상 4K UHD로 실시간 변환
〈 김 문 철 교수 〉
우리 대학 전기및전자공학부 김문철 교수 연구팀이 딥러닝 기술을 이용해 풀 HD 비디오 영상을 4K UHD 초고화질 영상으로 초해상화 변환할 수 있는 기술을 개발했다.
이 기술은 인공지능의 핵심 기술인 심층 콘볼루션 신경망(Deep Convolutional Neural Network, DCNN)을 하드웨어로 구현했다. 초당 60프레임의 초고해상도 4K UHD 화면을 실시간으로 생성할 수 있는 알고리즘 및 하드웨어 개발을 통해 향후 프리미엄 UHD TV, 360 VR, 4K IPTV 등에 기여할 것으로 기대된다.
이번 연구는 KAIST 전기및전자공학부 김용우, 최재석 박사과정 등이 주도했고 현재 특허 출원을 준비 중이다.
최근 영상 화질 개선 연구에 인공지능의 핵심 기술인 심층 콘볼루션 신경망을 적용시키려는 노력이 활발히 이뤄지고 있다. 그러나 이러한 심층 콘볼루션 신경망 기술은 연산 복잡도와 매우 높고 사용되는 메모리가 커 작은 규모의 하드웨어를 통해 초고해상도 영상으로 실시간 변환하는 데 한계가 있다.
기존의 프레임 단위로 영상을 처리하던 방식은 DRAM과 같은 외부 메모리 사용이 필수적인데 이로 인해 영상 데이터를 처리할 때 지나친 외부 메모리 접근으로 인한 메모리 병목현상과 전력 소모 현상이 발생했다.
김 교수 연구팀은 프레임 단위 대신 라인 단위로 데이터를 처리할 수 있는 효율적인 심층 콘볼루션 신경망 구조를 개발해 외부 메모리를 사용하지 않고도 작은 규모의 하드웨어에서 초당 60 프레임의 4K UHD 초해상화를 구현했다.
연구팀은 기존 소프트웨어 방식의 심층 콘볼루션 신경망 기반의 고속 알고리즘과 비교해 필터 파라미터를 65% 정도만 적용하고도 유사한 화질을 유지했다.
이는 딥러닝 기술을 이용한 고해상도 영상 변환 기술이 활발히 진행되는 가운데 초당 60프레임의 4K UHD 초해상화를 하드웨어로 실현한 첫 사례로 꼽힌다.
김 교수는 “이번 연구는 심층 콘볼루션 신경망이 작은 규모의 하드웨어에서 초고품질 영상 처리에 실질적으로 응요 가능한 기술임을 보인 매우 중요한 사례다”며 “현재 프리미엄 UHD TV 및 UHD 방송 콘텐츠 생성, 360도 VR 콘텐츠, 4K IPTV 서비스에 매우 효과적으로 적용할 수 있다”고 말했다.
이번 연구는 과학기술정보통신부 정보통신기술진흥센터(IITP) ICT 기초연구실지원사업의 지원을 받아 수행됐다.
□ 그림 설명
그림1. 실시간 AI(딥러닝) 기반 고속 초고해상도 업스케일링 기술
그림2.심층 신경망 AI 기반 4K UHD 60fps 실시간 초해상화 하드웨어 (FPGA)
그림3. 심층 신경망 AI 기반 4K UHD 60fps 실시간 초해상화 하드웨어 시연
2018.01.16 조회수 14320
김문철 교수, 인공지능 통해 풀HD영상 4K UHD로 실시간 변환
〈 김 문 철 교수 〉
우리 대학 전기및전자공학부 김문철 교수 연구팀이 딥러닝 기술을 이용해 풀 HD 비디오 영상을 4K UHD 초고화질 영상으로 초해상화 변환할 수 있는 기술을 개발했다.
이 기술은 인공지능의 핵심 기술인 심층 콘볼루션 신경망(Deep Convolutional Neural Network, DCNN)을 하드웨어로 구현했다. 초당 60프레임의 초고해상도 4K UHD 화면을 실시간으로 생성할 수 있는 알고리즘 및 하드웨어 개발을 통해 향후 프리미엄 UHD TV, 360 VR, 4K IPTV 등에 기여할 것으로 기대된다.
이번 연구는 KAIST 전기및전자공학부 김용우, 최재석 박사과정 등이 주도했고 현재 특허 출원을 준비 중이다.
최근 영상 화질 개선 연구에 인공지능의 핵심 기술인 심층 콘볼루션 신경망을 적용시키려는 노력이 활발히 이뤄지고 있다. 그러나 이러한 심층 콘볼루션 신경망 기술은 연산 복잡도와 매우 높고 사용되는 메모리가 커 작은 규모의 하드웨어를 통해 초고해상도 영상으로 실시간 변환하는 데 한계가 있다.
기존의 프레임 단위로 영상을 처리하던 방식은 DRAM과 같은 외부 메모리 사용이 필수적인데 이로 인해 영상 데이터를 처리할 때 지나친 외부 메모리 접근으로 인한 메모리 병목현상과 전력 소모 현상이 발생했다.
김 교수 연구팀은 프레임 단위 대신 라인 단위로 데이터를 처리할 수 있는 효율적인 심층 콘볼루션 신경망 구조를 개발해 외부 메모리를 사용하지 않고도 작은 규모의 하드웨어에서 초당 60 프레임의 4K UHD 초해상화를 구현했다.
연구팀은 기존 소프트웨어 방식의 심층 콘볼루션 신경망 기반의 고속 알고리즘과 비교해 필터 파라미터를 65% 정도만 적용하고도 유사한 화질을 유지했다.
이는 딥러닝 기술을 이용한 고해상도 영상 변환 기술이 활발히 진행되는 가운데 초당 60프레임의 4K UHD 초해상화를 하드웨어로 실현한 첫 사례로 꼽힌다.
김 교수는 “이번 연구는 심층 콘볼루션 신경망이 작은 규모의 하드웨어에서 초고품질 영상 처리에 실질적으로 응요 가능한 기술임을 보인 매우 중요한 사례다”며 “현재 프리미엄 UHD TV 및 UHD 방송 콘텐츠 생성, 360도 VR 콘텐츠, 4K IPTV 서비스에 매우 효과적으로 적용할 수 있다”고 말했다.
이번 연구는 과학기술정보통신부 정보통신기술진흥센터(IITP) ICT 기초연구실지원사업의 지원을 받아 수행됐다.
□ 그림 설명
그림1. 실시간 AI(딥러닝) 기반 고속 초고해상도 업스케일링 기술
그림2.심층 신경망 AI 기반 4K UHD 60fps 실시간 초해상화 하드웨어 (FPGA)
그림3. 심층 신경망 AI 기반 4K UHD 60fps 실시간 초해상화 하드웨어 시연
2018.01.16 조회수 14320